In modern enterprise environments, DHCP configuration has evolved from a relatively simple service into a highly structured and detail-driven process that supports large-scale, distributed infrastructures. As networks grow in size and diversity, the number of devices relying on dynamic addressing increases significantly, which introduces a wide range of configuration requirements that extend far beyond basic IP assignment. DHCP options are now commonly used to deliver critical network parameters such as gateway information, domain details, vendor-specific instructions, and boot-related instructions for devices that require automated provisioning. This added functionality makes DHCP an essential part of infrastructure orchestration rather than just a background service. However, this increased responsibility also introduces complexity in how these options are defined, maintained, and applied across multiple environments. Administrators must ensure consistency in configuration across multiple DHCP scopes, maintain alignment with evolving infrastructure policies, and carefully manage dependencies between different network services. Even small inconsistencies in DHCP configuration can lead to devices failing to boot correctly, receiving incorrect network parameters, or being unable to communicate with essential services. As organizations scale, these challenges multiply, particularly in environments that span multiple sites or include hybrid infrastructure components. The need for precision becomes even more critical when DHCP is tied into automated provisioning systems, where devices rely on predefined instructions during initial boot stages. This makes DHCP not just a configuration tool but a foundational element of network orchestration that must be carefully controlled and consistently managed to avoid operational disruption.
Why Software Defined Networking Increases Configuration Demands
Software Defined Networking introduces a level of abstraction that separates control logic from underlying hardware, enabling more flexible and programmable network environments. While this separation brings significant advantages in terms of agility and scalability, it also increases the demand for more structured configuration management practices. In traditional networking models, configuration changes were often applied directly to individual devices, but in SDN environments, these changes are typically orchestrated through centralized systems that distribute policies across multiple nodes. This shift means that configuration elements such as DHCP options are no longer isolated settings but part of a broader policy framework that must be consistently applied across the entire network fabric. As a result, even a single configuration change may have cascading effects across multiple systems, requiring careful validation and coordination. SDN environments also introduce a higher degree of automation, which depends heavily on accurate configuration data to function correctly. If DHCP options are misconfigured or inconsistently applied, automated provisioning processes can fail, leading to delays in device deployment or incorrect network behavior. Additionally, SDN architectures often support dynamic scaling, meaning that devices may be added or removed from the network frequently. This creates a continuous demand for configuration updates that must be synchronized across the system. The increased abstraction layer does not reduce complexity; instead, it shifts complexity into centralized systems where precision, consistency, and orchestration become essential for maintaining operational stability.
Challenges in Manual DHCP Option Management
Managing DHCP options manually in large-scale networks presents several operational challenges that stem primarily from the repetitive and detail-sensitive nature of the task. Each DHCP option must be carefully defined, validated, and applied to the correct scope, ensuring that devices receiving these configurations interpret them correctly. In environments where multiple DHCP servers are deployed, maintaining consistency across configurations becomes increasingly difficult, as each server may require identical settings to ensure uniform behavior across the network. Manual configuration also increases the risk of human error, particularly when dealing with complex option structures that require precise formatting or encoding. A single incorrect value can disrupt device provisioning processes or lead to miscommunication between network components. Furthermore, manual management lacks scalability, as each new device type or network segment may require additional configuration work that must be repeated across multiple systems. This not only increases administrative workload but also slows down deployment cycles, especially in environments where rapid scaling is required. Another challenge arises from the lack of visibility into configuration states across the network. Without centralized control, administrators may struggle to determine whether DHCP options have been consistently applied or whether discrepancies exist between different servers. This lack of visibility can lead to troubleshooting difficulties when issues arise, as identifying the root cause often requires manual comparison of configurations across multiple systems. These challenges highlight the limitations of manual DHCP management in modern network environments, where speed, accuracy, and consistency are critical for operational efficiency.
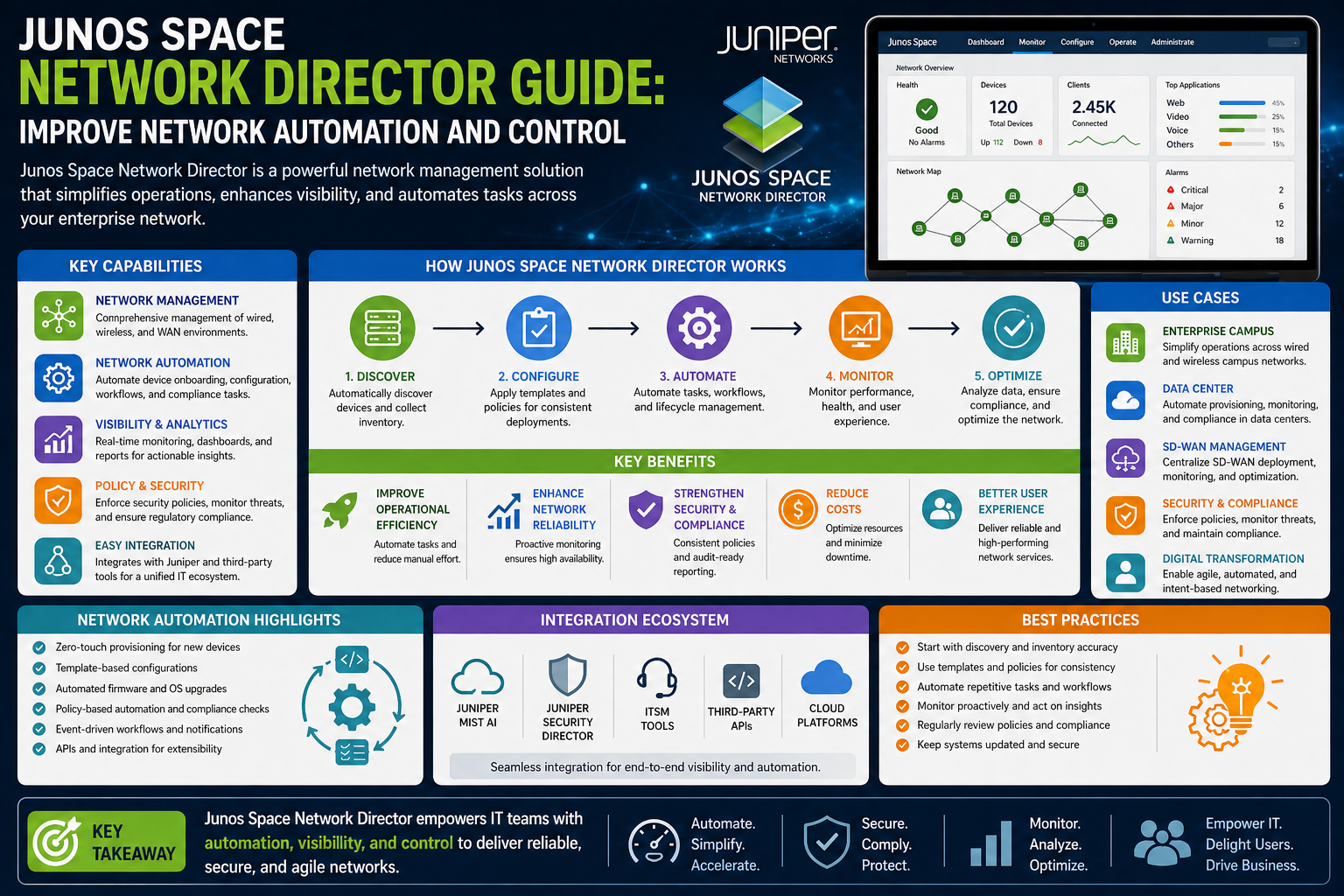
Understanding Junos Space as a Centralized Platform
Junos Space functions as a centralized management environment designed to provide unified control over network infrastructure components, enabling administrators to manage configuration, monitoring, and operational tasks from a single interface. Instead of interacting with individual devices separately, engineers can use this platform to define policies and configurations that are then distributed across the network in a controlled and consistent manner. This centralized approach reduces fragmentation in configuration management and helps ensure that all devices operate according to the same operational standards. Within this framework, DHCP configuration becomes part of a larger ecosystem of network services that are managed cohesively rather than independently. The platform enables administrators to maintain structured control over configuration workflows, reducing the likelihood of inconsistencies that often arise in distributed management environments. It also provides a foundation for automation by allowing predefined templates and policies to be applied across multiple devices simultaneously. This eliminates the need for repetitive manual configuration tasks and helps maintain alignment between network services and organizational requirements. In addition, centralized management improves operational visibility by consolidating network information into a unified view, making it easier to understand how different components interact within the infrastructure. This holistic perspective is particularly valuable in complex environments where multiple systems must work together seamlessly to support application delivery and service reliability. By centralizing control, Junos Space simplifies the operational model of large networks while maintaining the flexibility needed to support dynamic and evolving infrastructure demands.
Role of Network Director in Unified Operations
Network Director operates as a key component within the centralized management ecosystem by focusing specifically on the operational aspects of network infrastructure, including provisioning, configuration management, and ongoing device lifecycle handling. It provides a unified operational layer that allows administrators to manage switches, routers, and other network devices through a consistent framework, reducing the need to interact with each device individually. This unified approach ensures that configuration policies are applied consistently across the entire network, which is particularly important in environments where multiple device types and configurations coexist. Network Director also enhances operational efficiency by enabling administrators to perform bulk configuration tasks, reducing the time required to deploy new devices or modify existing configurations. It supports structured workflows that guide the deployment process from initial setup through to operational readiness, ensuring that each stage of configuration is completed correctly before progressing. In addition, it provides visibility into network topology and device status, allowing engineers to monitor the health of the infrastructure in real time. This visibility is essential for maintaining operational stability, as it enables quick identification of configuration issues or performance anomalies. By consolidating these functions into a single operational tool, Network Director reduces complexity and improves the consistency of network management practices, making it easier to maintain large-scale infrastructures without sacrificing control or accuracy.
How Centralized Orchestration Changes Provisioning Workflows
Centralized orchestration fundamentally transforms the way provisioning workflows are executed within network environments by shifting control from individual device configuration to policy-driven automation. Instead of manually configuring each device during deployment, administrators define high-level policies that are automatically applied as devices are introduced into the network. This approach significantly reduces the time required to bring new infrastructure components online and ensures that configurations remain consistent across all deployed devices. In this model, provisioning becomes a structured process that follows predefined stages, allowing for predictable and repeatable deployment outcomes. Centralized orchestration also improves coordination between different network services, ensuring that dependencies such as IP addressing, routing configurations, and service discovery mechanisms are properly aligned during the provisioning process. This reduces the likelihood of configuration mismatches that can occur when systems are configured independently. Additionally, orchestration systems maintain awareness of network state, allowing them to adjust configurations dynamically as devices are added or removed. This adaptability is particularly important in environments that require rapid scaling or frequent changes in network topology. By automating these processes, centralized orchestration reduces administrative overhead while improving deployment accuracy and operational consistency across the entire infrastructure.
Zero Touch Provisioning in Enterprise Environments
Zero Touch Provisioning introduces a fully automated approach to device deployment where network equipment is configured without requiring manual intervention during initial setup. When a device is powered on and connected to the network, it automatically retrieves configuration instructions from centralized systems and applies them without requiring direct administrator input. This process relies heavily on predefined configuration policies and communication between DHCP services and orchestration platforms. In enterprise environments, this approach significantly accelerates deployment timelines by eliminating the need for manual configuration of individual devices. It also reduces the risk of human error during initial setup, ensuring that all devices are configured consistently according to organizational standards. ZTP is particularly valuable in large-scale deployments where hundreds or even thousands of devices may need to be configured within a short period of time. It also supports distributed environments where physical access to devices may be limited or impractical. By automating the initial provisioning process, ZTP allows network teams to focus on higher-level operational tasks rather than repetitive configuration work. This approach aligns closely with modern network design principles that emphasize automation, scalability, and consistency across infrastructure components.
DHCP Option 43 Complexity and Real-World Implications
DHCP Option 43 is commonly used in enterprise environments to provide vendor-specific information to network devices during the provisioning process. However, its configuration is often complex due to the structured format required to encode data correctly. Unlike standard DHCP options, Option 43 frequently requires precise formatting that ensures devices can correctly interpret the information being provided. This complexity increases the likelihood of configuration errors, particularly when administrators must manually construct or validate encoded values. In real-world deployments, incorrect configuration of Option 43 can lead to devices failing to locate provisioning servers or misinterpreting network instructions, resulting in failed deployments or incomplete configurations. The challenge is further compounded in environments where multiple device vendors are used, each potentially requiring different formatting standards or interpretation methods. As a result, administrators must carefully manage these configurations to ensure compatibility across diverse infrastructure components. The importance of accuracy in Option 43 configuration makes it a critical element in automated provisioning systems, where even minor inconsistencies can disrupt entire deployment workflows. This reinforces the need for structured management approaches that reduce manual handling and improve configuration reliability across the network environment.
Hex Conversion Requirements in Network Configurations
Hexadecimal conversion is often required in network configuration scenarios where data must be encoded into a format that devices can interpret during provisioning processes. This is particularly common in DHCP configurations, where certain options require values to be represented in hexadecimal form rather than standard decimal or textual formats. The need for conversion arises from the way network devices process configuration data at a low level, where binary and hexadecimal representations are more efficient for interpretation. However, manual conversion introduces additional complexity into the configuration process, as administrators must ensure that values are accurately translated without errors. Even small mistakes in conversion can result in incorrect configuration data being delivered to devices, potentially causing provisioning failures or misconfigurations. This process becomes even more challenging in large-scale environments where multiple values must be converted and validated across different configuration scopes. The reliance on manual conversion also increases the risk of inconsistency, particularly when multiple administrators are involved in managing the same infrastructure. As network environments become more automated and dynamic, the need for reliable and consistent encoding mechanisms becomes increasingly important to ensure smooth provisioning and operational stability.
Integration Between DHCP and Device Bootstrapping
The integration between DHCP services and device bootstrapping processes plays a critical role in automated network provisioning by enabling devices to receive essential configuration information during their initial startup phase. When a device boots, it relies on DHCP not only for IP addressing but also for additional configuration parameters that guide its next steps in the provisioning workflow. This integration allows devices to automatically locate provisioning servers, download configuration files, and apply necessary settings without manual intervention. The effectiveness of this process depends heavily on the accuracy and consistency of DHCP configuration, as any discrepancies can disrupt the bootstrapping sequence and prevent devices from completing their setup. In modern network environments, this integration is often tightly coupled with centralized orchestration systems that manage both DHCP configuration and provisioning workflows. This ensures that devices receive consistent instructions that align with overall network policies and operational requirements. By linking DHCP services with bootstrapping mechanisms, organizations can achieve a higher level of automation and reduce the complexity associated with manual device configuration, enabling faster and more reliable network expansion.
Inventory Management and Lifecycle Visibility
Effective inventory management and lifecycle visibility are essential components of modern network operations, particularly in environments where devices are frequently added, removed, or reconfigured. Centralized management systems provide a structured way to track network devices throughout their entire lifecycle, from initial deployment through to decommissioning. This visibility allows administrators to maintain accurate records of device status, configuration state, and operational health across the entire infrastructure. It also supports better decision-making by providing insights into how network resources are being utilized and where potential issues may arise. Lifecycle visibility ensures that devices remain properly aligned with configuration policies over time, reducing the risk of configuration drift or inconsistencies that can affect network performance. In addition, it simplifies troubleshooting by providing a clear view of device history and current state, enabling faster identification of issues when they occur. Inventory management also plays a key role in supporting automation, as accurate device information is required for orchestration systems to function correctly. By maintaining a comprehensive and up-to-date view of the network environment, organizations can improve operational efficiency and maintain greater control over complex infrastructure deployments.
Architecture of Centralized Network Orchestration Systems
Centralized network orchestration systems are built on layered architectures that separate intent definition, policy interpretation, and device-level execution into distinct functional domains. This separation allows complex network operations to be managed in a structured and predictable manner while still maintaining flexibility across diverse infrastructure components. At the highest level, the orchestration layer acts as the control point where administrators define operational intent, such as how devices should behave, how traffic should flow, and how services should be delivered across the network. This intent is then translated into structured policies that can be applied consistently across different device types and network segments. Beneath this layer, a mediation system interprets these policies and converts them into device-specific configurations that align with the capabilities of each hardware element. This translation process is essential because enterprise networks often consist of heterogeneous devices with varying configuration requirements and operational models. At the lowest level, execution engines interact directly with network devices to apply configurations, monitor status, and collect operational data. This layered structure ensures that high-level decisions remain independent of device-specific complexity, allowing engineers to manage networks based on intent rather than individual configuration commands. In environments where DHCP and provisioning systems are integrated, this architecture ensures that configuration data flows seamlessly from centralized policy definitions to device-level execution without requiring manual intervention. The result is a highly structured environment where consistency, scalability, and control are maintained across the entire infrastructure.
Policy-Driven Configuration Models in Enterprise Networks
Policy-driven configuration models represent a fundamental shift in how network behavior is defined and managed within modern infrastructures. Instead of configuring individual devices manually, administrators define policies that describe desired outcomes, such as connectivity rules, service requirements, and provisioning behaviors. These policies are then automatically translated into device configurations by centralized orchestration systems. This abstraction allows engineers to focus on what the network should achieve rather than how each device should be configured to achieve it. In complex environments, this approach significantly reduces operational overhead by eliminating repetitive configuration tasks and ensuring that all devices adhere to the same operational standards. Policy models also introduce a higher level of consistency, as changes made at the policy level are automatically propagated throughout the network, reducing the risk of configuration drift. When applied to DHCP and provisioning workflows, policy-driven models ensure that devices receive consistent network parameters during bootstrapping, regardless of their physical location or deployment context. This is particularly important in distributed environments where devices may be deployed across multiple sites with varying network conditions. By centralizing policy control, organizations can maintain uniform behavior across their entire infrastructure while still accommodating local variations where necessary. This balance between central control and distributed execution is a key characteristic of modern network management systems.
Device Discovery and Automated Enrollment Processes
Device discovery and automated enrollment processes play a critical role in enabling large-scale network automation by ensuring that new devices are seamlessly integrated into existing infrastructure without manual configuration. When a device is introduced into the network, discovery mechanisms identify its presence and gather relevant metadata such as hardware type, interface capabilities, and initial network state. This information is then used to determine how the device should be configured and where it fits within the overall network topology. Automated enrollment builds on this process by registering the device within centralized management systems and assigning it appropriate configuration policies based on predefined rules. In environments where DHCP and provisioning systems are integrated, discovery often begins during the initial IP assignment phase, where devices receive basic network connectivity information that allows them to communicate with orchestration platforms. Once communication is established, the device can be fully onboarded into the management system without requiring manual intervention. This automated approach significantly reduces deployment time and ensures that devices are consistently configured according to organizational standards. It also improves scalability by allowing networks to expand dynamically without requiring proportional increases in administrative effort. As a result, device discovery and enrollment form a foundational component of modern automated network infrastructures.
Configuration Templates and Standardization Mechanisms
Configuration templates serve as reusable building blocks that define standardized settings for network devices, enabling consistent deployment across large and diverse infrastructures. These templates encapsulate predefined configuration parameters such as interface settings, routing behavior, security policies, and service definitions, allowing them to be applied uniformly across multiple devices. By using templates, administrators can eliminate the need to manually configure each device individually, reducing both operational complexity and the risk of human error. Standardization mechanisms built into orchestration systems ensure that templates are applied consistently and that any deviations from defined standards are automatically identified and corrected. This approach is particularly valuable in environments where multiple device types and vendors coexist, as it allows for consistent operational behavior despite underlying hardware differences. In the context of DHCP and provisioning workflows, configuration templates ensure that devices receive consistent initialization parameters during bootstrapping, aligning their behavior with network-wide policies from the moment they join the infrastructure. Templates also support scalability by enabling rapid deployment of new devices or network segments without requiring custom configuration for each instance. Over time, this leads to a more stable and predictable network environment where configuration consistency is maintained across all operational domains.
Multi-Site Network Coordination and Consistency Management
Managing networks that span multiple physical sites introduces additional complexity due to variations in connectivity, latency, and local infrastructure requirements. Multi-site coordination mechanisms within centralized orchestration systems are designed to address these challenges by ensuring that configuration policies are consistently applied across all locations while still allowing for localized adjustments where necessary. This is achieved through hierarchical management structures where global policies define overarching network behavior, while site-specific configurations handle local variations. Consistency management ensures that changes made at the global level are propagated to all sites in a controlled manner, reducing the risk of configuration drift between locations. In environments where DHCP and provisioning systems are deployed across multiple sites, synchronization becomes particularly important, as devices at different locations must receive consistent configuration parameters to ensure uniform behavior. Multi-site coordination also improves operational visibility by aggregating status and performance data from all locations into a centralized view, allowing administrators to monitor the entire network as a single entity. This unified perspective simplifies troubleshooting and enables faster identification of issues that may affect multiple sites simultaneously. As networks continue to expand geographically, multi-site coordination becomes an essential component of maintaining operational consistency and reliability.
Workflow Automation in Network Provisioning
Workflow automation in network provisioning transforms complex deployment processes into structured, repeatable sequences that can be executed without manual intervention. These workflows define the steps required to bring new devices into operational status, including discovery, authentication, configuration, validation, and activation. Each step is executed automatically based on predefined rules and conditions, ensuring that devices are provisioned consistently and efficiently. Automation reduces the time required to deploy new infrastructure components and minimizes the risk of human error during configuration. In addition, workflow systems provide visibility into each stage of the provisioning process, allowing administrators to track progress and identify potential issues in real time. When integrated with DHCP services, workflows can trigger specific actions based on network events such as IP assignment or device boot completion, further enhancing automation capabilities. This integration ensures that provisioning processes are tightly aligned with network state, enabling seamless transitions between different stages of deployment. Workflow automation also supports scalability by allowing multiple devices to be provisioned simultaneously using the same process definitions. This is particularly valuable in environments that require rapid expansion or frequent updates to network infrastructure.
Network Fabric Construction and Logical Topology Management
Network fabric construction refers to the process of building a logical network structure that abstracts underlying physical infrastructure into a unified operational model. This approach allows complex networks to be managed as a single entity rather than a collection of individual devices. Logical topology management enables administrators to define how devices are interconnected, how traffic flows through the network, and how services are distributed across different segments. By abstracting physical complexity, network fabric models simplify configuration and improve scalability. In environments where DHCP and provisioning systems are integrated, fabric construction ensures that devices are automatically placed into the correct logical segments during onboarding, based on predefined policies. This reduces the need for manual configuration and ensures consistent network behavior across all deployed devices. Logical topology management also improves resilience by allowing the network to dynamically adapt to changes in device availability or connectivity. If a device fails or is removed, the fabric can automatically adjust routing and configuration parameters to maintain service continuity. This dynamic adaptability is a key characteristic of modern network architectures, enabling organizations to maintain stable and efficient operations even in highly dynamic environments.
Telemetry Collection and Network Visibility Enhancement
Telemetry collection provides continuous insight into network behavior by gathering operational data from devices across the infrastructure. This data includes performance metrics, configuration states, traffic patterns, and system health indicators, all of which are used to build a comprehensive view of network operations. Enhanced visibility allows administrators to understand how the network is performing in real time and identify potential issues before they impact services. In centralized orchestration systems, telemetry data is aggregated and analyzed to provide insights into overall network health, enabling proactive management and optimization. When combined with DHCP and provisioning workflows, telemetry can also be used to monitor device onboarding processes, ensuring that new devices are correctly configured and integrated into the network. This continuous feedback loop improves operational accuracy and reduces the time required to diagnose and resolve issues. Telemetry also supports long-term planning by providing historical data that can be used to identify trends and capacity requirements. As networks grow in size and complexity, telemetry becomes an essential tool for maintaining visibility and control across distributed environments.
Security Policy Enforcement in Automated Environments
Security policy enforcement in automated network environments ensures that all devices adhere to predefined security standards throughout their lifecycle. These policies define how devices should authenticate, what types of traffic are allowed, and how access controls are applied across the network. In centralized orchestration systems, security policies are automatically applied during device provisioning, ensuring that new devices are compliant from the moment they join the network. This reduces the risk of misconfiguration and strengthens overall network security posture. In addition, automated enforcement ensures that security policies remain consistent across all devices, even as the network evolves over time. When integrated with DHCP and provisioning workflows, security policies can be dynamically assigned based on device type, location, or role within the network. This allows for granular control over network access while maintaining centralized management. Automated security enforcement also improves response times to emerging threats by allowing policies to be updated and propagated across the entire infrastructure quickly. This ensures that the network remains protected even in rapidly changing threat environments.
Change Management and Controlled Configuration Updates
Change management processes in network environments are designed to ensure that configuration updates are applied in a controlled, predictable, and reversible manner. These processes are essential for maintaining network stability, particularly in large-scale environments where even small configuration changes can have wide-ranging effects. Centralized orchestration systems provide structured mechanisms for defining, reviewing, and deploying configuration changes across multiple devices simultaneously. This ensures that updates are applied consistently and that potential conflicts are identified before they impact operations. In environments where DHCP and provisioning systems are integrated, change management also extends to bootstrapping and device onboarding processes, ensuring that updates do not disrupt ongoing deployments. Controlled configuration updates typically follow staged deployment models, where changes are first tested in limited environments before being rolled out more broadly. This reduces risk and allows for validation of configuration behavior under real-world conditions. By enforcing structured change management practices, organizations can maintain operational stability while still enabling continuous improvement and network evolution.
Fault Management and Automated Recovery Mechanisms
Fault management systems are responsible for detecting, isolating, and responding to network issues in real time. These systems continuously monitor device status and network behavior to identify anomalies that may indicate failures or performance degradation. When a fault is detected, automated recovery mechanisms can initiate predefined responses such as configuration rollback, device restart, or traffic rerouting to restore normal operations. This automation reduces the need for manual intervention and minimizes downtime during network disruptions. In centralized orchestration environments, fault management is closely integrated with provisioning and configuration systems, allowing recovery actions to take into account the overall network state and policy requirements. This ensures that recovery processes do not introduce additional inconsistencies or configuration conflicts. When combined with DHCP and bootstrapping workflows, fault management systems can also assist in recovering failed device deployments by reinitiating provisioning sequences automatically. This improves overall network resilience and ensures that services remain available even in the presence of hardware or configuration failures.
Scalability Models for Expanding Network Infrastructure
Scalability in network infrastructure refers to the ability to expand operational capacity without compromising performance or manageability. Modern orchestration systems achieve scalability through automation, policy-driven configuration, and centralized management structures that reduce the complexity of adding new devices or services. As networks grow, these systems ensure that new components are seamlessly integrated into existing workflows without requiring significant manual effort. In environments where DHCP and provisioning systems are used, scalability is further enhanced by automating device onboarding and configuration processes, allowing large numbers of devices to be deployed simultaneously. Scalability models also incorporate load distribution mechanisms that ensure network resources are efficiently utilized as demand increases. This includes balancing traffic across multiple devices, optimizing configuration distribution, and maintaining consistent policy enforcement across expanding infrastructures. By combining automation with centralized control, scalable network systems enable organizations to grow their infrastructure dynamically while maintaining operational stability and consistency across all network domains.
Integration of Centralized Networking with SDN Environments
In modern enterprise infrastructures, centralized network management platforms are increasingly designed to operate alongside Software Defined Networking environments, creating a unified operational model that blends hardware control with software-driven intelligence. This integration allows network behavior to be defined at a higher abstraction level, where policies and intent are translated into dynamic configurations across physical and virtual components. Within this model, centralized orchestration systems act as the coordination layer between application requirements and underlying network resources. This ensures that changes in application demand can be reflected in network behavior without requiring manual device-level intervention. The integration also enables more responsive network adaptation, where routing decisions, bandwidth allocation, and service provisioning can be adjusted in near real time based on operational conditions. In environments where automated provisioning is already in place, SDN integration enhances responsiveness by ensuring that newly deployed devices immediately align with global network policies. This alignment reduces configuration delays and ensures consistent operational behavior across hybrid infrastructures. As organizations continue to adopt distributed computing models, the combination of centralized orchestration and SDN becomes a foundational approach for maintaining agility and operational coherence.
Advanced Lifecycle Automation in Network Devices
Lifecycle automation extends beyond initial device provisioning to encompass the entire operational lifespan of network infrastructure components. This includes deployment, configuration updates, performance monitoring, maintenance scheduling, and eventual decommissioning. By automating each stage of the lifecycle, organizations reduce the need for manual intervention while improving consistency and reliability across network operations. During the deployment phase, devices are automatically discovered, registered, and configured according to predefined policies. Once operational, they are continuously monitored to ensure compliance with performance and security standards. Automated systems can detect deviations in behavior or configuration and trigger corrective actions without human input. Maintenance processes are also streamlined through automation, allowing firmware updates and configuration changes to be applied systematically across large device populations. This ensures that infrastructure remains up to date without introducing unnecessary downtime or operational risk. When devices reach the end of their lifecycle, automated decommissioning processes ensure that configurations are safely removed, and resources are released back into the network pool. This structured lifecycle approach improves resource efficiency and ensures that network environments remain clean, organized, and aligned with operational standards throughout their evolution.
Role of API-Driven Network Management
API-driven network management introduces a programmable interface layer that enables external systems and applications to interact directly with network orchestration platforms. This approach allows administrators and automation tools to perform configuration tasks, retrieve operational data, and manage network resources programmatically. By exposing network functionality through APIs, centralized platforms become more flexible and integrable with broader IT ecosystems. This is particularly valuable in environments where network operations must align closely with application deployment pipelines or cloud orchestration systems. API-driven models enable dynamic configuration changes that can be triggered automatically based on external events, such as application scaling or workload migration. In addition, APIs facilitate integration with monitoring systems, allowing real-time data collection and analysis to support operational decision-making. When combined with automated provisioning workflows, API-based control allows for fully dynamic network environments where infrastructure adapts continuously to changing requirements. This reduces reliance on manual configuration processes and enables more responsive and efficient network management practices. The ability to programmatically control network behavior represents a significant step toward fully automated infrastructure ecosystems.
Network Analytics and Operational Intelligence
Network analytics transforms raw operational data into actionable insights that support decision-making, performance optimization, and predictive maintenance. Centralized management systems collect large volumes of telemetry data from across the network, including traffic patterns, device performance metrics, and configuration states. This data is then processed and analyzed to identify trends, anomalies, and potential issues before they impact service delivery. Operational intelligence built on top of this data allows administrators to understand how the network behaves under different conditions and how resources are being utilized over time. In automated environments, analytics also play a critical role in optimizing provisioning workflows by identifying inefficiencies or bottlenecks in configuration processes. Predictive capabilities enable systems to anticipate potential failures or performance degradation, allowing proactive intervention before issues escalate. This shift from reactive to proactive network management significantly improves reliability and reduces downtime. Additionally, analytics provide valuable input for capacity planning, ensuring that infrastructure expansion aligns with actual usage patterns and future demand. As networks become more complex, analytics-driven intelligence becomes essential for maintaining visibility and control over distributed environments.
High Availability and Redundancy Strategies
High availability and redundancy are fundamental design principles in modern network infrastructures, ensuring continuous service delivery even in the event of component failures. These strategies involve deploying multiple instances of critical services and network devices so that workloads can be automatically transferred if a failure occurs. Centralized orchestration systems play a key role in managing redundancy by monitoring device health and dynamically adjusting configurations to maintain service continuity. In environments where automated provisioning is used, redundancy mechanisms ensure that new devices are seamlessly integrated into failover structures without manual configuration. This reduces downtime and enhances resilience across the entire network. Redundancy is typically implemented at multiple levels, including device redundancy, link redundancy, and system-level redundancy, each contributing to overall network stability. High availability systems continuously monitor network conditions and trigger automatic failover processes when disruptions are detected. This ensures that services remain accessible even during hardware failures or connectivity issues. By combining redundancy with automation, modern networks achieve a level of resilience that supports mission-critical operations and large-scale distributed deployments.
Configuration Drift Detection and Correction
Configuration drift occurs when network devices gradually deviate from their intended configuration state due to manual changes, system updates, or inconsistent application of policies. Over time, this drift can lead to inconsistencies that affect network performance, security, and reliability. Centralized management systems address this issue by continuously monitoring device configurations and comparing them against defined policy baselines. When discrepancies are detected, automated correction mechanisms can restore devices to their intended state without manual intervention. This ensures that network behavior remains consistent across all infrastructure components, regardless of operational changes or environmental factors. Drift detection is particularly important in large-scale environments where manual tracking of configuration changes is impractical. It also plays a critical role in maintaining compliance with organizational standards and regulatory requirements. Automated correction mechanisms reduce the operational burden on administrators by eliminating the need for manual remediation of configuration inconsistencies. By maintaining strict alignment between intended and actual configurations, organizations can ensure stable and predictable network behavior across all operational domains.
Security Automation and Policy Enforcement Consistency
Security automation ensures that protective measures are consistently applied across all network devices without relying on manual configuration. This includes enforcement of access control rules, encryption policies, authentication mechanisms, and traffic filtering rules. In centralized orchestration environments, security policies are defined at a high level and automatically propagated to all relevant devices. This ensures that security configurations remain consistent even as the network evolves or expands. Automated enforcement reduces the risk of misconfiguration, which is a common source of security vulnerabilities in manually managed environments. It also allows for rapid response to emerging threats, as security policies can be updated centrally and distributed across the network in real time. In environments with automated provisioning, security policies are applied during device onboarding, ensuring that new devices are compliant from the moment they join the network. This eliminates the risk of unsecured devices operating within the infrastructure. Consistency in security enforcement is essential for maintaining a strong security posture, particularly in distributed and dynamic network environments.
Conclusion
Centralized network management through platforms like Junos Space with Network Director represents a significant shift in how modern infrastructures are designed, deployed, and maintained. By bringing configuration, provisioning, and monitoring into a unified framework, organizations reduce reliance on manual processes and improve overall operational consistency. The integration of automation, policy-driven control, and zero touch provisioning helps eliminate many of the traditional challenges associated with DHCP configuration, device onboarding, and network scaling. As networks continue to expand in complexity, the ability to maintain accuracy, visibility, and control becomes increasingly important. Centralized orchestration ensures that changes are applied consistently across all devices, while automation reduces human error and accelerates deployment cycles. Combined with analytics and lifecycle management, these systems provide a more resilient and adaptive network environment. Ultimately, this approach enables enterprises to support growing demands while maintaining stability, security, and efficiency across increasingly dynamic and distributed infrastructures.