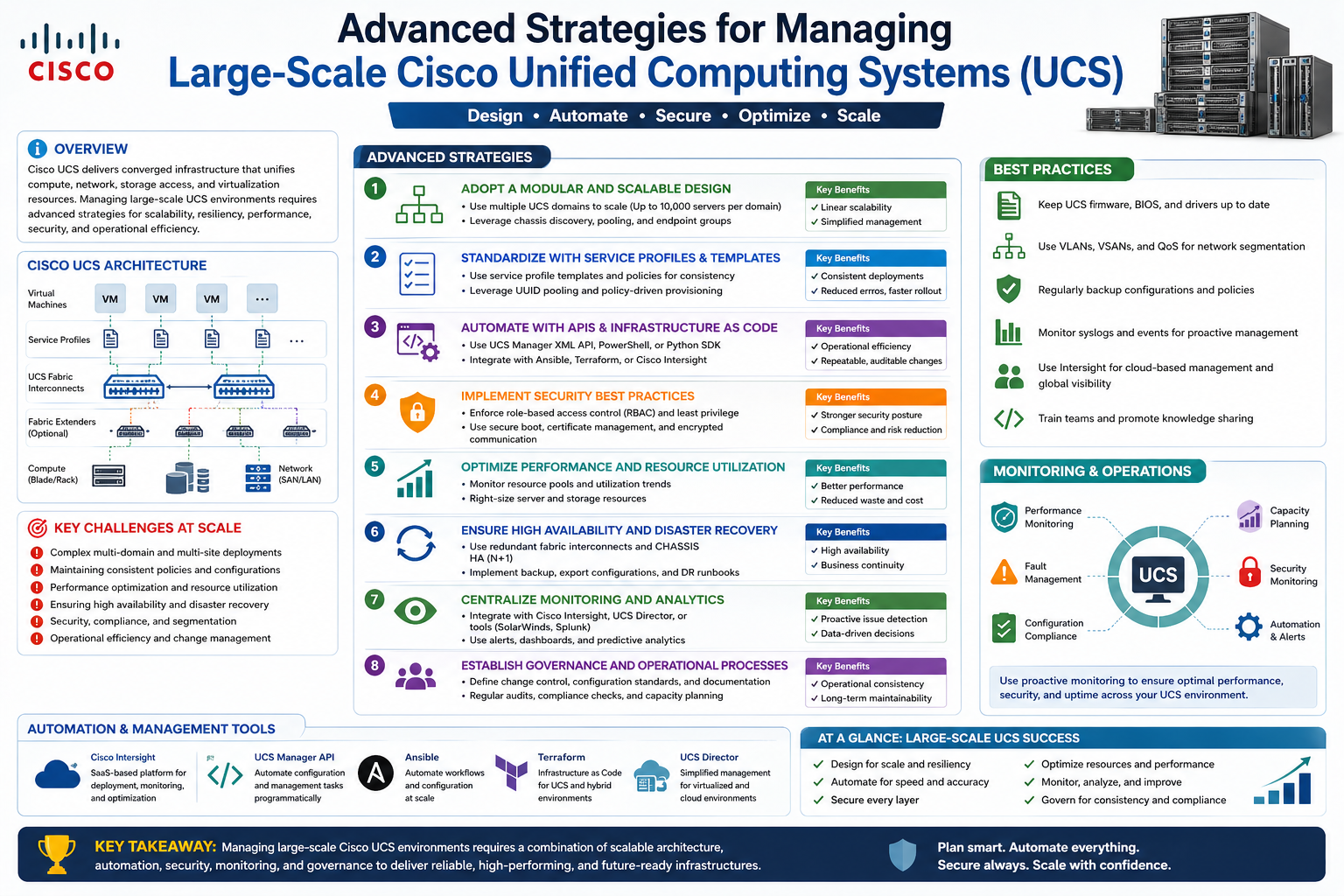
Managing a large Cisco UCS environment requires more than just basic familiarity with servers or networking hardware. At scale, the system becomes a tightly integrated ecosystem where compute, networking, and storage are unified into a single operational model. When environments grow beyond a few dozen servers into hundreds of blades and rack systems, the complexity shifts from simple administration to structured design and disciplined operational control.
Cisco UCS was designed specifically to address the inefficiencies found in traditional server infrastructures, where compute nodes, network switches, and storage systems are managed independently. In a large deployment, this separation often leads to configuration drift, inconsistent policies, and increased operational overhead. UCS reduces these challenges by introducing centralized control and standardized deployment models that apply consistently across all connected hardware.
In environments that exceed 250 blade servers, the importance of standardization becomes even more critical. Without consistent configurations, administrators would struggle to maintain system stability, especially when dealing with firmware updates, service deployments, or hardware replacements. The UCS model allows administrators to define reusable configuration logic that can be applied uniformly across all systems, ensuring predictable behavior regardless of scale.
At this level of deployment, even minor inconsistencies can lead to significant operational issues. For example, differences in firmware versions or BIOS settings across blades can affect workload performance or prevent virtual machines from migrating smoothly in virtualized environments. This is why large UCS deployments rely heavily on centralized policy enforcement rather than manual configuration.
Another defining characteristic of large UCS environments is the balance between flexibility and control. While the system provides extensive configuration options, not all of them are required for every environment. Administrators must identify which features add real operational value and which may introduce unnecessary complexity. This selective approach helps maintain stability while still taking advantage of UCS’s automation capabilities.
Understanding UCS at scale also involves recognizing how physical infrastructure translates into logical management structures. A single physical change, such as adding a blade or replacing a chassis component, is not treated as an isolated event. Instead, it becomes part of a larger managed ecosystem where configuration, identity, and connectivity are dynamically assigned based on predefined rules.
Architecture Foundations of UCS Domains
The foundation of any Cisco UCS environment is the concept of a domain. A UCS domain represents a logically unified set of computing resources managed as a single entity. This typically includes a pair of fabric interconnects along with multiple chassis or rack servers connected to them. In large environments, multiple domains are often used to distribute workload, reduce risk, and improve manageability.
A key characteristic of the UCS domain architecture is its hierarchical structure. At the top level, fabric interconnects serve as the central control point. Beneath them, chassis and servers operate as managed endpoints that inherit configuration settings from centralized policies. This hierarchical design simplifies large-scale administration by reducing the need to configure each device individually.
In environments with hundreds of servers, domain design plays a crucial role in ensuring operational efficiency. While a single domain can technically support a large number of servers, practical considerations often lead administrators to distribute workloads across multiple domains. This approach helps reduce the impact of maintenance activities and improves fault isolation.
Each domain operates independently, meaning that configuration changes, firmware upgrades, and hardware events are contained within that specific domain. This isolation is particularly valuable in large data centers where uptime requirements are strict, and downtime must be carefully controlled. By segmenting infrastructure into multiple domains, administrators can perform maintenance on one portion of the environment while others continue operating normally.
Another important aspect of UCS domain architecture is scalability. While a single domain has defined limits in terms of chassis and server support, the overall system can scale horizontally by adding more domains. This allows organizations to grow their infrastructure without redesigning their entire management framework.
The domain concept also introduces a consistent operational model. Regardless of size, each domain behaves in a predictable manner, using the same management tools and configuration principles. This consistency reduces the learning curve for administrators and simplifies troubleshooting across different parts of the infrastructure.
Fabric Interconnects and Unified Connectivity
At the core of every UCS domain are the fabric interconnects. These devices serve as the primary communication and management layer between compute resources and the external network infrastructure. They are responsible for handling both data traffic and management traffic, making them one of the most critical components in the entire system.
Fabric interconnects operate in a paired configuration to provide redundancy. In large environments, high availability is essential, and the dual-device setup ensures that the failure of one interconnect does not disrupt operations. The system automatically handles failover between devices, maintaining connectivity and minimizing downtime.
One of the most important roles of fabric interconnects is to abstract the underlying complexity of physical connections. Instead of requiring administrators to manage individual network interfaces on each server, UCS centralizes connectivity through unified fabric policies. This means that network and storage connections can be defined once and applied consistently across all servers in the domain.
This abstraction significantly simplifies large-scale network management. In traditional environments, each server may require individual configuration for network access, VLAN assignment, and storage connectivity. In UCS, these configurations are centrally defined and automatically applied based on server identity.
Fabric interconnects also play a key role in storage integration. They are capable of handling both Ethernet and Fibre Channel traffic, allowing them to connect directly to storage area networks without requiring separate dedicated switches for each function. This convergence reduces infrastructure complexity and improves efficiency in large deployments.
In addition to connectivity, fabric interconnects are responsible for enforcing policies and maintaining communication with UCS Manager. They act as the execution layer for configuration changes, ensuring that policies defined at the management level are properly implemented across all connected hardware.
At scale, the performance and reliability of fabric interconnects become increasingly important. Since all traffic flows through these devices, they must be sized and configured appropriately to handle the demands of hundreds of servers. Proper planning of bandwidth, redundancy, and failover behavior is essential in large environments to prevent bottlenecks and ensure consistent performance.
Blade Chassis and Rack Server Integration
Cisco UCS environments are built to support both blade servers and rack-mounted servers within the same management framework. Blade systems are typically deployed in chassis that house multiple compute nodes, while rack servers operate as standalone units. Both types of servers are managed using the same UCS principles, allowing for consistent administration across different hardware formats.
Blade chassis are designed to maximize density and efficiency. A single chassis can contain multiple blade servers, all sharing power, cooling, and networking components. This shared infrastructure reduces physical complexity and improves space utilization in data centers. In large environments, this density becomes particularly valuable as it allows organizations to scale compute resources without significantly increasing physical footprint.
Each chassis connects to the fabric interconnects through modular input/output components. These connections provide both network and storage access to the blades inside the chassis. The backplane architecture ensures that communication between blades and external systems remains efficient and centralized.
Rack servers, on the other hand, provide flexibility for workloads that require standalone configurations or specific hardware requirements. These servers integrate into UCS through dedicated connectivity to the fabric interconnects, allowing them to be managed alongside blade systems.
One of the strengths of UCS is its ability to treat both blade and rack servers as part of a unified compute pool. From a management perspective, there is no fundamental difference between the two once they are integrated into a UCS domain. They can both be assigned service profiles, managed through policies, and monitored using the same tools.
In large-scale environments, this unified approach simplifies infrastructure planning. Instead of maintaining separate management systems for different server types, administrators can apply a consistent operational model across all compute resources. This reduces complexity and improves visibility across the entire environment.
Physical awareness remains important, however. Even though UCS abstracts much of the underlying hardware complexity, administrators must still understand where systems are located, how they are connected, and how they are distributed across data center racks and chassis. This knowledge becomes critical during maintenance, troubleshooting, and capacity planning activities.
Importance of Hardware Awareness in Operations
Even in highly automated environments, physical hardware awareness remains an essential part of managing large UCS deployments. While administrators may interact primarily with logical constructs such as service profiles and policies, these abstractions are ultimately mapped to physical components.
Understanding the physical layout of a UCS environment helps ensure effective troubleshooting and maintenance. When a hardware issue occurs, being able to identify the exact chassis, slot, or rack location of a server can significantly reduce resolution time. In large environments, where hundreds of servers may be distributed across multiple data center rows, this knowledge becomes essential.
Hardware awareness also plays a role in capacity planning. Knowing how resources are physically distributed allows administrators to make informed decisions about workload placement, redundancy strategies, and expansion planning. For example, placing critical workloads across multiple chassis or domains can reduce the impact of hardware failures.
Another important aspect is LED indicators and physical status signals. Even though UCS provides detailed monitoring through software interfaces, physical indicators on hardware components often provide the first sign of an issue. Administrators and technicians must be able to interpret these signals accurately to diagnose problems quickly.
In addition to troubleshooting, hardware familiarity supports effective communication between teams. In large organizations, different teams may be responsible for networking, computing, storage, and facilities. Being able to clearly reference physical components helps ensure coordination during maintenance or incident response activities.
Large UCS environments also require a strong understanding of lifecycle management. Hardware components eventually require replacement, upgrade, or reconfiguration. Knowing how these components fit into the overall system architecture ensures that changes can be made without disrupting service continuity.
UCS Manager and Centralized Management Approach
UCS Manager serves as the primary interface for managing a single UCS domain. It provides a centralized platform where administrators can configure hardware, define policies, monitor system health, and manage connectivity. In large environments, UCS Manager becomes the operational backbone for day-to-day administration.
One of the key strengths of UCS Manager is its policy-driven architecture. Instead of configuring each server individually, administrators define policies that describe how systems should behave. These policies are then applied consistently across all relevant hardware components.
The interface is typically accessed through a virtual management address that provides redundancy between fabric interconnects. This ensures that management access remains available even if one interconnect becomes unavailable. The system automatically handles failover, maintaining continuous access to management functions.
Within UCS Manager, administrators can manage a wide range of resources, including compute profiles, network configurations, storage connections, and firmware settings. This centralized approach reduces administrative overhead and improves consistency across the environment.
In large-scale deployments, UCS Manager becomes especially valuable because it enables automation through templates and reusable configurations. Instead of manually configuring each server, administrators can define templates that automatically generate standardized server profiles.
This approach significantly reduces the time required to deploy new systems and ensures that all servers adhere to the same configuration standards. It also minimizes human error, which is particularly important when managing large numbers of systems.
UCS Manager also provides detailed visibility into system health and performance. Administrators can monitor hardware status, track configuration changes, and identify potential issues before they impact operations. This proactive monitoring capability is essential in large environments where manual oversight would be impractical.
Pools, Policies, and Service Profile Concepts
A defining feature of Cisco UCS is its use of pools and policies to abstract and automate configuration management. Pools represent collections of resources such as MAC addresses, WWPN identifiers, or UUIDs, which can be dynamically assigned to servers as needed. This eliminates the need for manual assignment and reduces the risk of duplication or conflict.
Policies define how systems should be configured and behave. These may include settings related to BIOS configuration, network connectivity, boot order, or firmware versions. By separating policy definition from hardware configuration, UCS allows for highly flexible and scalable management.
Service profiles bring these concepts together by acting as logical representations of servers. A service profile contains all the configuration information required for a server to operate, including network identity, storage configuration, and hardware settings. When a service profile is assigned to a physical server, it effectively defines that server’s entire identity and behavior.
In large environments, service profiles are essential for maintaining consistency. They ensure that every server configured for a specific role behaves identically, regardless of underlying hardware differences. This consistency is critical for applications that rely on predictable infrastructure behavior.
Service profiles also support mobility. Because configuration is decoupled from physical hardware, a service profile can be reassigned to a different server if needed. This allows for rapid hardware replacement and simplifies disaster recovery processes.
Service Profile Templates and Automation at Scale
Service profile templates extend the concept of service profiles by enabling automated generation of multiple consistent configurations. Instead of creating each service profile individually, administrators define a template that serves as a blueprint.
When a template is used, multiple service profiles can be generated automatically, each inheriting the same configuration structure. This is particularly useful in large environments where dozens or hundreds of similar servers need to be deployed.
Templates support scalability by ensuring that configuration standards are applied consistently across all generated profiles. This reduces administrative effort and ensures uniformity across the environment.
At scale, this automation becomes one of the most important features of UCS. Without it, managing hundreds of servers would require significant manual effort and would increase the likelihood of configuration errors.
Templates also support dynamic updates. Changes made to a template can be propagated to linked service profiles, ensuring that configuration updates are applied consistently. This capability is particularly valuable in environments where infrastructure requirements evolve.
Operational Considerations for Deployment and Booting Systems
Deploying operating systems in large UCS environments involves careful planning of boot strategies and installation methods. Since servers are often deployed at scale, manual installation is not practical. Instead, automated or semi-automated methods are used to streamline the process.
Network-based booting is one common approach, allowing servers to retrieve installation images from centralized infrastructure. This method requires proper configuration of boot policies and network services, but provides a scalable solution for large deployments.
Another approach involves virtual media, where installation images are mounted remotely and used to install operating systems directly onto servers. This method is often used for flexibility, especially when dealing with diverse operating system requirements.
In large environments, the choice of deployment method depends on operational needs, network design, and automation strategy. Regardless of the method used, consistency in configuration is essential to ensure predictable outcomes across all systems.
Boot configuration is tightly integrated with service profiles, meaning that changes to deployment settings can be managed centrally. This ensures that all servers follow the same installation process, reducing variability and improving efficiency.
Expanding UCS Environments Through Multi-Domain Design
As Cisco UCS environments grow beyond a single cluster of chassis and servers, the operational model begins to shift from simple centralized management to distributed architectural design. In large-scale deployments, the introduction of multiple domains becomes a foundational strategy for controlling complexity, improving resilience, and reducing operational risk.
A single UCS domain can support a substantial number of servers, but when environments exceed a few hundred blades and rack systems, practical limitations emerge. These limitations are not only technical but also operational. Maintenance windows, firmware upgrades, and configuration changes all become more impactful when applied across a single large domain.
By introducing multiple domains, administrators create logical boundaries that segment infrastructure into manageable units. Each domain operates independently, with its own fabric interconnects, policies, and management plane. This separation allows maintenance activities to be performed on one domain while others continue operating without interruption.
Multi-domain design also introduces better fault isolation. If a configuration error or hardware issue occurs in one domain, the impact is contained within that segment. This reduces the risk of widespread disruption and improves overall system stability in large environments.
From an operational perspective, multi-domain design requires careful planning of workload distribution. Compute resources must be balanced across domains to avoid overloading one segment while underutilizing another. This balance becomes particularly important in virtualized environments where workloads are dynamically distributed.
In environments integrated with virtualization platforms like VMware vCenter, domain separation can also support controlled migration strategies. Virtual machines can be moved between domains to facilitate maintenance or upgrades, reducing downtime and improving service continuity.
Centralized Management Evolution with UCS Central
While individual UCS domains provide strong localized control, managing multiple domains independently can become operationally inefficient at scale. To address this challenge, centralized management platforms were introduced to extend visibility and control across multiple domains.
One such platform is UCS Central, designed to provide a unified view of the distributed UCS infrastructure. Rather than replacing domain-level management, it acts as an overlay that aggregates configuration, inventory, and monitoring data across multiple domains.
In large environments, UCS Central enables administrators to apply consistent policies across geographically distributed data centers. This is particularly important for organizations that operate multiple infrastructure sites but require standardized compute behavior across all locations.
Policy consistency is one of the most critical benefits of centralized management. Without it, each domain could drift into slightly different configurations over time, leading to inconsistencies that complicate troubleshooting and workload mobility.
By using centralized policy distribution, administrators can ensure that changes made at a higher level are propagated consistently across all managed domains. This reduces manual configuration effort and improves alignment across the entire infrastructure estate.
However, UCS Central also introduces considerations related to versioning and lifecycle alignment. Since it operates as an additional management layer, it must remain compatible with the underlying domain software versions. This requires careful coordination during upgrades and maintenance cycles.
Modern UCS Management with Cisco Intersight
As infrastructure management continues to evolve toward cloud-based operational models, Cisco introduced a more modern platform in the form of Cisco Intersight. Unlike traditional on-premises management tools, Intersight operates as a SaaS-based platform designed to provide unified visibility across compute, networking, and storage environments.
In large UCS deployments, Intersight plays an increasingly important role in simplifying multi-domain operations. Instead of managing each domain individually or relying solely on on-premises aggregation tools, administrators can leverage cloud-based analytics and centralized control.
One of the key advantages of Intersight is its ability to correlate operational data across infrastructure layers. This means that hardware health, configuration status, and workload performance can be analyzed together, providing deeper insights into system behavior.
In environments with hundreds or thousands of servers, this level of visibility becomes essential for proactive management. Rather than reacting to failures, administrators can identify trends and potential issues before they escalate into outages.
Intersight also introduces policy-based automation at scale. Policies can be defined once and applied across multiple UCS domains, reducing configuration drift and improving consistency. This approach aligns well with modern infrastructure practices that emphasize infrastructure as code and automated lifecycle management.
Security is another important aspect of Intersight’s design. As a cloud-based platform, it incorporates identity management, secure connectivity, and role-based access control to ensure that infrastructure data remains protected while still being accessible to authorized administrators.
Lifecycle Management in Large UCS Deployments
Lifecycle management is one of the most complex aspects of operating large UCS environments. It involves coordinating hardware upgrades, firmware updates, configuration changes, and software patches across hundreds of interconnected systems.
In traditional infrastructure environments, lifecycle management is often fragmented, with different teams responsible for different components. UCS simplifies this by centralizing control over firmware and configuration policies.
Firmware management in large UCS environments must be carefully orchestrated to avoid downtime. Because components such as fabric interconnects, chassis I/O modules, and blades are tightly integrated, upgrades must follow specific sequences to maintain system stability.
In large environments, staged upgrades are often used to minimize risk. Instead of updating all components simultaneously, changes are rolled out incrementally across domains or clusters. This allows administrators to validate stability before proceeding to the next phase.
Service profiles play a critical role in lifecycle management by decoupling configuration from physical hardware. This means that servers can be replaced or upgraded without requiring manual reconfiguration, as long as the service profile is reassigned correctly.
In virtualized environments, integration with platforms like VMware vCenter further enhances lifecycle flexibility. Virtual machines can be migrated away from hosts scheduled for maintenance, enabling non-disruptive upgrades.
Advanced Firmware Coordination and Upgrade Strategies
Firmware management in UCS environments is not simply a maintenance task; it is a coordinated operational discipline. Every component in the system, from fabric interconnects to individual blades, depends on firmware compatibility to ensure stable operation.
In large deployments, firmware upgrades are typically governed by predefined baselines. These baselines define approved versions for all components and ensure that systems remain aligned across the environment.
One of the key challenges in firmware management is dependency coordination. Certain components must be upgraded in a specific order to avoid compatibility issues. For example, fabric interconnect upgrades often precede chassis and blade updates.
To manage this complexity, administrators rely on staged upgrade workflows. These workflows ensure that changes are applied systematically, with validation steps between each stage. This reduces the risk of widespread failure during upgrade cycles.
Rollback planning is also an important part of firmware strategy. In large environments, the ability to revert to a previous stable state is essential in case unexpected issues arise during upgrades.
Service Profile Mobility and Infrastructure Agility
Service profiles are one of the most powerful features in UCS environments because they allow compute identity to be decoupled from physical hardware. This abstraction enables a level of flexibility that is not typically found in traditional server environments.
In large deployments, service profile mobility allows workloads to be shifted between physical servers without requiring reconfiguration. This is particularly useful during hardware maintenance or failure recovery scenarios.
When a server fails or requires replacement, its service profile can be reassigned to a new physical node. The new server inherits all configuration settings, including network identity, storage connectivity, and boot parameters.
This mobility significantly reduces recovery time and simplifies hardware lifecycle operations. Instead of manually rebuilding server configurations, administrators can restore functionality through profile reassignment.
In environments integrated with virtualization platforms, service profile mobility complements virtual machine migration strategies. Together, they create a highly flexible infrastructure model capable of adapting to changing workload demands.
Automation and Scripting in Large UCS Environments
Automation plays a central role in managing large UCS environments. As the number of servers increases, manual administration becomes impractical and prone to error. Automation tools help streamline repetitive tasks and ensure consistency across the infrastructure.
One of the primary automation interfaces in UCS environments is PowerShell-based tooling provided by Cisco Systems. These tools allow administrators to interact programmatically with UCS Manager and perform bulk operations efficiently.
Automation is commonly used for tasks such as inventory collection, configuration auditing, and bulk provisioning. In large environments, even small efficiencies gained through automation can translate into significant operational savings.
Scripting also enables integration between UCS and other infrastructure systems. For example, data collected from UCS can be combined with virtualization or monitoring platforms to provide a unified operational view.
In mature environments, automation evolves from simple scripts to fully integrated workflows. These workflows coordinate actions across compute, storage, and network layers, ensuring that infrastructure changes are applied consistently and safely.
Integration Between UCS and Virtualized Infrastructure
Modern UCS environments are rarely operated in isolation. Instead, they are typically integrated with virtualization platforms and higher-level orchestration systems. This integration allows compute resources to be dynamically allocated based on workload demand.
In environments using VMware vCenter, UCS serves as the underlying physical infrastructure layer, while virtualization platforms manage workload distribution. This separation of concerns improves flexibility and resource utilization.
When integrated properly, UCS and virtualization systems work together to enable advanced operational capabilities such as live migration, load balancing, and automated failover. These capabilities are essential in large-scale enterprise environments where uptime requirements are strict.
Service profiles further enhance this integration by ensuring that physical hosts maintain a consistent configuration regardless of where virtual workloads are placed. This reduces variability and improves predictability across the infrastructure stack.
Operational Troubleshooting at Scale
Troubleshooting in large UCS environments requires a structured approach due to the complexity and scale of the infrastructure. Issues may originate at the hardware level, network layer, or configuration layer, and identifying the root cause requires correlation across all components.
One of the advantages of UCS is its centralized visibility. Administrators can access detailed system health information from a single management interface, reducing the need to physically inspect hardware.
However, effective troubleshooting still depends on understanding system relationships. A failure in one component may have cascading effects across multiple servers or services. Recognizing these dependencies is critical for accurate diagnosis.
In large environments, troubleshooting is often supported by historical data and trend analysis. By reviewing system behavior over time, administrators can identify patterns that indicate underlying issues before they escalate.
Scaling Challenges and Operational Discipline
As UCS environments scale, operational discipline becomes increasingly important. Without standardized processes, even advanced automation tools cannot prevent configuration drift or inconsistent system behavior.
Scaling introduces challenges in resource allocation, workload balancing, and maintenance coordination. These challenges must be addressed through careful architectural planning and consistent operational governance.
Large environments also require strong change management practices. Every configuration change has the potential to impact multiple systems, so changes must be carefully reviewed, tested, and deployed in controlled phases.
At scale, success depends not only on technology but also on process maturity. Well-defined operational procedures ensure that infrastructure remains stable, predictable, and efficient even as it grows in size and complexity.
Operational Complexity in Mature Cisco UCS Environments
As Cisco UCS environments mature and scale beyond a few hundred servers, the operational focus shifts from deployment and basic configuration to sustained management, optimization, and risk control. At this stage, the infrastructure is no longer just a collection of compute resources—it becomes a tightly interdependent ecosystem where every change can have wide-reaching effects.
In large environments, complexity is not only measured by the number of servers but also by the number of interactions between components. Each blade, chassis, fabric interconnect, and network connection contributes to a larger operational surface area that must be continuously monitored and maintained.
One of the most important aspects of managing mature UCS deployments is maintaining consistency. Even small deviations in configuration can lead to unpredictable behavior when workloads are scaled across hundreds of servers. This is especially critical in environments where workloads are distributed dynamically and rely on predictable hardware behavior.
As the environment grows, administrators must also manage increasing levels of abstraction. Instead of interacting directly with physical hardware, most operations are performed through service profiles, policies, and templates. While this abstraction improves efficiency, it also requires a strong understanding of how logical configurations map to physical infrastructure.
In highly scaled deployments, operational discipline becomes just as important as technical capability. Without strict adherence to configuration standards, lifecycle processes, and change control, even the most advanced infrastructure can become unstable over time.
Scaling Operational Governance Across UCS Domains
Governance in large UCS environments refers to the policies, processes, and controls used to manage infrastructure consistently across multiple domains. As environments expand, governance becomes essential to ensure that all systems operate within defined boundaries.
Each UCS domain operates independently, but governance structures ensure that these domains remain aligned. This includes standardized naming conventions, consistent firmware baselines, and uniform service profile configurations.
In large organizations, governance is often enforced through centralized management frameworks that define how infrastructure should be configured and maintained. These frameworks ensure that even when multiple teams are involved in managing different domains, the overall system remains consistent.
A key challenge in scaling governance is balancing flexibility with control. While UCS provides powerful customization options, unrestricted flexibility can lead to inconsistencies. Governance structures help define which configurations are allowed and which must remain standardized.
In environments with multiple UCS domains, governance also plays a critical role in change coordination. Updates to policies or firmware must be carefully synchronized to avoid mismatches between domains. This is particularly important when workloads span multiple domains or when shared services depend on consistent infrastructure behavior.
Advanced Lifecycle Coordination in Large Deployments
Lifecycle management in large UCS environments extends far beyond routine upgrades. It involves continuous coordination between hardware, firmware, software, and workload requirements.
As infrastructure scales, lifecycle events become more frequent and more complex. Hardware components age at different rates, firmware versions evolve, and application requirements change over time. Managing these variables requires a structured approach to lifecycle coordination.
In mature environments, lifecycle management is typically divided into phases. These include planning, validation, deployment, and post-change verification. Each phase is designed to minimize risk and ensure that changes do not negatively impact production workloads.
One of the most critical aspects of lifecycle coordination is dependency management. UCS components are tightly integrated, meaning that changes to one component often require updates to others. For example, updating fabric interconnect firmware may require corresponding updates to chassis I/O modules and server firmware.
To manage this complexity, administrators rely on predefined compatibility matrices and upgrade paths. These tools help ensure that all components remain aligned and that upgrades follow supported sequences.
In environments integrated with virtualization platforms such as VMware vCenter, lifecycle coordination also includes workload migration planning. Virtual machines may need to be moved between hosts to accommodate maintenance activities, requiring careful orchestration between compute and virtualization layers.
Performance Optimization at Scale
Performance optimization in large UCS environments involves more than tuning individual servers. It requires a holistic view of how compute, network, and storage resources interact across the entire infrastructure.
At scale, performance issues are often not caused by single points of failure but by resource contention or misaligned configurations. Identifying these issues requires continuous monitoring and correlation across multiple system layers.
One of the key advantages of UCS is its ability to standardize hardware configurations. This consistency makes it easier to identify performance anomalies, as deviations from expected behavior are more noticeable in uniform environments.
Performance optimization also involves workload placement strategies. In large environments, workloads must be distributed across servers in a way that balances CPU, memory, and I/O utilization. Poor placement decisions can lead to bottlenecks that impact overall system performance.
Networking performance is another critical factor. Since UCS integrates compute and network connectivity through fabric interconnects, network design plays a direct role in application performance. Proper configuration of VLANs, bandwidth allocation, and redundancy paths is essential for maintaining consistent performance.
Storage performance must also be carefully managed. UCS environments often connect to external storage systems, and performance depends on both fabric configuration and storage backend efficiency.
High Availability and Fault Tolerance Design
High availability is a core requirement in large UCS environments. As the number of servers increases, the likelihood of hardware failures also increases, making fault tolerance essential for maintaining service continuity.
UCS achieves high availability through multiple layers of redundancy. Fabric interconnects operate in pairs, chassis include redundant power and networking components, and servers are typically configured with multiple network and storage paths.
In large environments, fault tolerance is not limited to hardware redundancy. It also includes architectural design choices such as workload distribution across multiple domains. This ensures that a failure in one domain does not impact the entire infrastructure.
Virtualization adds another layer of fault tolerance. In environments integrated with platforms like VMware vCenter, workloads can be automatically restarted or migrated when hardware failures occur.
Service profiles further enhance fault tolerance by allowing rapid reassignment of server identities. If a physical server fails, its configuration can be transferred to another server, restoring functionality without manual reconfiguration.
High availability design also includes careful planning of maintenance strategies. Since updates and upgrades can introduce temporary downtime, environments must be designed to tolerate partial outages without impacting critical services.
Infrastructure Security in Large UCS Deployments
Security becomes increasingly important as UCS environments scale. With hundreds of servers and multiple domains, the attack surface expands, requiring strong controls at both physical and logical levels.
At the hardware level, security includes controlling access to data center facilities and ensuring that physical servers are protected from unauthorized access. At the infrastructure level, security focuses on configuration control and access management.
UCS provides role-based access control, allowing administrators to define granular permissions for different operational roles. This ensures that only authorized personnel can make changes to critical infrastructure components.
Network security is also a key consideration. Since UCS integrates compute and networking, proper segmentation and isolation of traffic are essential for protecting sensitive workloads.
In large environments, security policies must be consistently applied across all domains. Without centralized governance, configuration drift can introduce vulnerabilities that are difficult to detect.
Audit logging and monitoring also play an important role in security. By tracking configuration changes and system events, administrators can identify unauthorized activity and respond quickly to potential threats.
Automation Maturity and Infrastructure as Code Practices
As UCS environments grow, automation evolves from simple scripting to fully integrated infrastructure management. This transition is often described as moving toward infrastructure as code principles.
In mature environments, infrastructure configurations are defined programmatically rather than manually. This ensures that systems can be deployed, modified, and scaled consistently across all domains.
Automation reduces the risk of human error, which becomes increasingly important as the number of servers grows. Manual configuration of hundreds of systems is not only inefficient but also prone to inconsistency.
Automation also enables faster provisioning of new resources. Instead of manually configuring each server, administrators can deploy standardized templates that automatically generate fully configured systems.
Integration between UCS and external automation tools allows for end-to-end orchestration of infrastructure changes. This includes compute provisioning, network configuration, and storage allocation.
In environments using virtualization platforms such as VMware vCenter, automation can extend into workload placement and lifecycle management, enabling fully dynamic infrastructure operations.
Monitoring, Analytics, and Predictive Operations
Monitoring in large UCS environments goes beyond simple status checking. It involves continuous analysis of system behavior to detect trends, anomalies, and potential failures before they occur.
At scale, raw monitoring data becomes less useful unless it is correlated and analyzed effectively. Modern UCS environments rely on centralized analytics to transform operational data into actionable insights.
Predictive operations are becoming increasingly important in large environments. By analyzing historical performance data, systems can identify patterns that indicate potential hardware failure or performance degradation.
This proactive approach allows administrators to address issues before they impact production workloads. It also reduces downtime and improves overall system reliability.
Monitoring also supports capacity planning. By analyzing resource utilization over time, administrators can make informed decisions about when to expand infrastructure or redistribute workloads.
Multi-Site UCS Architecture and Geographic Distribution
Large enterprises often operate UCS environments across multiple geographic locations. This introduces additional complexity in terms of latency, synchronization, and operational consistency.
Multi-site architecture requires careful planning of domain distribution and workload placement. Each site may operate independently, but governance and policy consistency must be maintained across all locations.
In distributed environments, centralized management platforms play a key role in maintaining visibility across all sites. This ensures that administrators can monitor and manage infrastructure regardless of geographic location.
Network connectivity between sites must also be carefully designed to support replication, migration, and centralized management functions. Latency and bandwidth considerations become critical factors in system design.
Conclusion
Managing a large Cisco UCS environment requires a combination of structured design, disciplined operations, and consistent governance. As infrastructure scales into hundreds of blade and rack servers, complexity shifts from individual system administration to coordinated lifecycle and policy management across multiple domains. The strength of UCS lies in its ability to unify compute, network, and storage under a centralized model, reducing manual configuration and improving consistency at scale.
However, this efficiency depends heavily on how well organizations apply automation, standardization, and monitoring practices. Service profiles, templates, and centralized policies help ensure uniform behavior, while multi-domain architectures improve resilience and reduce operational risk. Integration with virtualization and modern management platforms further enhances flexibility and workload mobility.
Ultimately, success in large UCS environments is not defined by hardware alone but by operational discipline. Careful planning, continuous optimization, and strong lifecycle management ensure that the infrastructure remains stable, scalable, and capable of supporting evolving enterprise demands over time.