The way modern applications are built and deployed has changed significantly over the past decade. Traditional methods relied heavily on physical servers or virtual machines, where each application often required a dedicated environment with its own operating system, dependencies, and configuration. While virtual machines improved efficiency by allowing multiple isolated systems on a single physical machine, they still carried overhead in terms of resource usage and management complexity.
Containers emerged as a more lightweight and flexible alternative. Instead of virtualizing entire operating systems, containers isolate applications at the process level. This means an application and everything it needs to run—such as libraries, configuration files, and runtime dependencies—are packaged together into a single unit. This unit can then be deployed consistently across different environments without modification.
This portability is one of the main reasons containers have become a cornerstone of modern cloud computing. Developers can build an application once and run it anywhere that supports container runtime environments. Whether it is a local machine, a private data center, or a public cloud platform, the behavior remains consistent.
However, while containers simplify application deployment, managing them at scale introduces new challenges. Running a single container is straightforward, but modern applications often consist of dozens, hundreds, or even thousands of containers working together. These containers need to be monitored, scaled, connected, and updated continuously without disrupting service.
This is where container orchestration becomes essential. Orchestration tools automate the management of container lifecycles, ensuring that applications remain available, scalable, and resilient even under changing workloads.
Understanding Container Orchestration in Cloud Environments
Container orchestration refers to the automated coordination of containerized applications across a cluster of computing resources. Instead of manually starting, stopping, and monitoring each container, orchestration systems handle these tasks programmatically.
At its core, orchestration is responsible for several key functions. It ensures that containers are deployed in the correct configuration, distributed efficiently across available computing resources, and restarted automatically if they fail. It also manages scaling, allowing applications to handle increased demand by launching additional containers or reducing capacity when demand decreases.
Another important role of orchestration is networking. Containers often need to communicate with each other, share data, or expose services to external users. Orchestration systems manage these connections and ensure secure and reliable communication paths.
Storage is another consideration. Containers are typically ephemeral, meaning they can be created and destroyed dynamically. Orchestration platforms provide mechanisms to connect persistent storage systems when needed, ensuring that important data is not lost when containers are replaced.
Security and compliance also fall under orchestration responsibilities. Access controls, identity management, and secure communication between services are typically integrated into orchestration frameworks to reduce operational risk.
In cloud environments, orchestration becomes even more important due to the scale and distributed nature of infrastructure. Cloud providers offer managed orchestration services that abstract much of the underlying complexity, allowing developers to focus more on application design and less on infrastructure management.
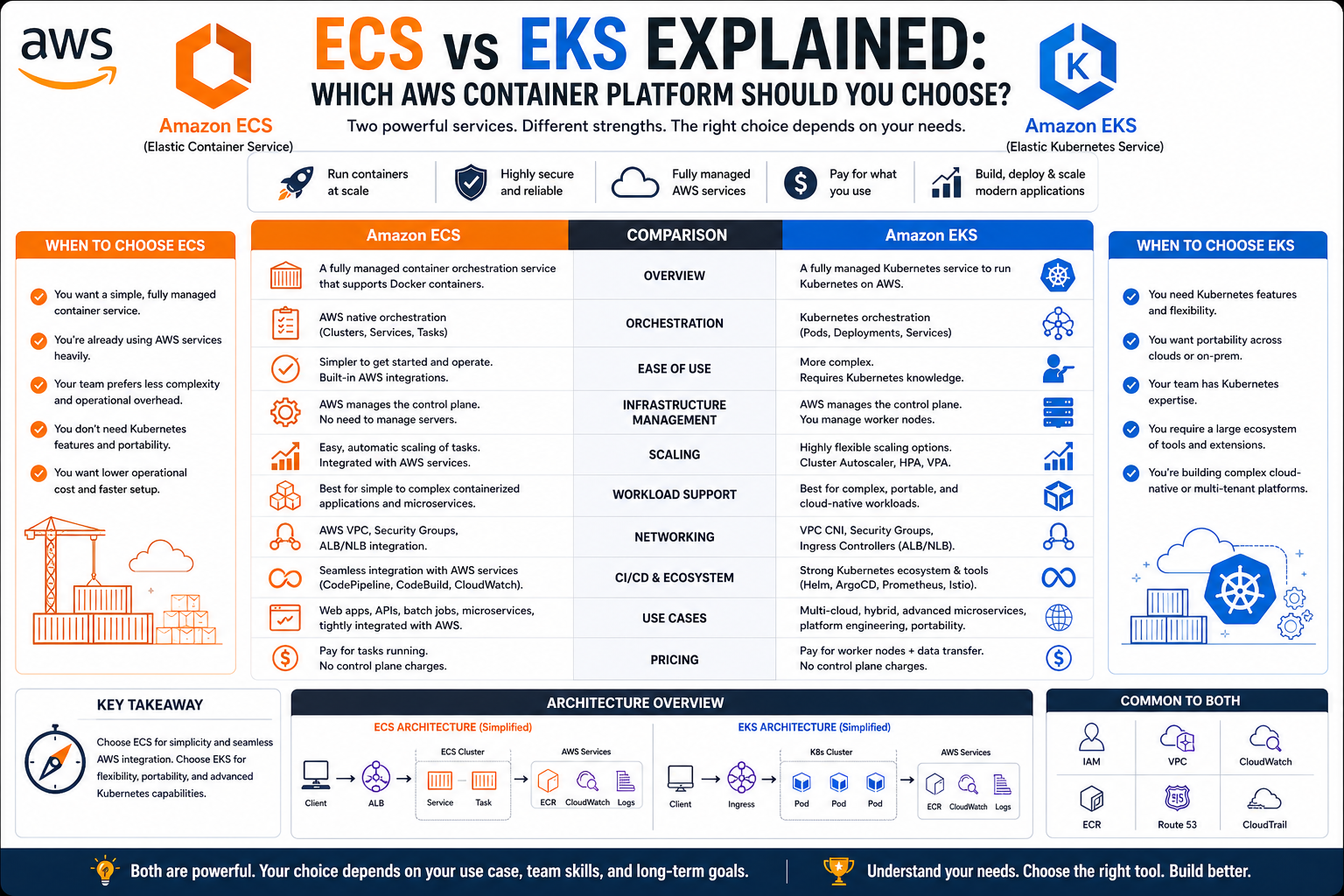
Amazon Web Services provides two major container orchestration options. One is a native service designed specifically for the AWS ecosystem, while the other is built around a widely adopted open-source standard. These two services reflect different philosophies in cloud application management and cater to different types of users and use cases.
Evolution of Containers and the Rise of AWS Orchestration Services
The shift toward containerized applications did not happen overnight. It evolved gradually as software development practices changed and as cloud computing matured. Early cloud environments primarily focused on virtual machines, where each workload ran in a fully isolated operating system instance. While this provided strong isolation, it also introduced inefficiencies in resource utilization.
As organizations began deploying more complex applications, the need for faster deployment cycles and improved scalability became more urgent. Containers addressed these needs by offering a more efficient way to package and run software. Instead of deploying entire virtual machines for each application, developers could deploy multiple containers on a single host, significantly improving resource usage.
This evolution led to the rise of container management platforms. Initially, tools were simple and focused on running containers on a single machine. However, as production systems grew, it became clear that managing containers across multiple machines required a more sophisticated approach.
Amazon Web Services responded to this shift by introducing its own container orchestration service. The goal was to provide a fully managed solution that integrates seamlessly with existing cloud services. At the same time, the broader industry adopted Kubernetes as a standard for container orchestration, leading AWS to also support Kubernetes through a managed service.
This dual approach created two distinct paths for container orchestration within AWS. One is tightly integrated with the AWS ecosystem and designed for simplicity and ease of use. The other is based on an open-source platform that offers flexibility and portability across different environments.
Deep Dive into Amazon Elastic Container Service
Amazon Elastic Container Service is a fully managed container orchestration platform designed specifically for the AWS ecosystem. It allows users to run containerized applications without needing to manage the underlying orchestration software themselves.
One of the key characteristics of this service is its tight integration with other AWS components. It works naturally with compute services, networking tools, identity management systems, and storage solutions within the AWS environment. This integration simplifies deployment workflows and reduces the need for complex configuration.
In this system, containers are defined using task definitions. A task definition acts as a blueprint that describes how a container should behave. It includes details such as which container image to use, how much memory and CPU it should allocate, and what environment variables it requires. Once defined, these tasks are deployed onto clusters of compute resources.
Clusters can be managed in different ways. In one approach, users directly manage the underlying virtual machines that host containers. In another approach, the infrastructure is abstracted away, allowing AWS to manage compute resources automatically. This flexibility allows organizations to choose between more control and more automation depending on their needs.
Scaling is handled automatically based on defined policies. When demand increases, additional containers can be launched to distribute the workload. When demand decreases, unnecessary containers can be removed to optimize resource usage. This dynamic scaling helps maintain performance while controlling costs.
Networking in this environment is also tightly integrated. Containers can communicate securely within a cluster, and external access can be controlled through load-balancing mechanisms. This ensures that traffic is distributed efficiently and that services remain accessible even under high demand.
Security is a central part of the design. Access to resources is controlled using identity and access management systems, ensuring that only authorized entities can interact with containerized applications. Encryption and secure communication channels further enhance protection.
Another important aspect is the support for different deployment models. Containers can be run on virtual machines, on serverless compute infrastructure, or even in hybrid environments that extend into on-premises systems. This flexibility allows organizations to adapt the platform to a wide range of architectural requirements.
Architecture and Operational Model of ECS
The operational model of this service is built around the concept of clusters, tasks, and services. Each of these components plays a specific role in how applications are deployed and managed.
A cluster represents a logical grouping of computing resources where containers run. These resources can be managed directly or abstracted through serverless compute options. The cluster acts as the foundation for all container activity.
A task represents a running instance of a container or a group of containers defined by a task definition. Tasks are the smallest deployable unit in this system. They are launched, monitored, and terminated based on application requirements and scaling policies.
A service ensures that a specified number of tasks are running at any given time. If a task fails, the service automatically replaces it to maintain the desired state. This self-healing behavior is critical for maintaining application reliability.
Deployment strategies are built into the system to support rolling updates. This means that new versions of applications can be introduced gradually without causing downtime. Old containers are replaced incrementally, ensuring continuous availability.
Monitoring and logging are also integrated into the architecture. Metrics related to performance, resource utilization, and application health are collected and can be used to make operational decisions. This visibility helps teams maintain control over complex distributed systems.
Introduction to Kubernetes-Based Orchestration in AWS
Alongside its native orchestration service, AWS also provides support for Kubernetes, an open-source platform that has become a standard in container orchestration across the industry. Kubernetes was originally developed to manage large-scale container deployments in a consistent and portable way.
Unlike proprietary systems, Kubernetes is designed to work across different cloud providers and on-premises environments. This makes it attractive for organizations that want to avoid dependency on a single cloud vendor or that operate in hybrid infrastructure environments.
AWS offers a managed implementation of Kubernetes that simplifies deployment and maintenance. While Kubernetes itself is powerful, it can be complex to set up and operate. The managed service reduces this complexity by handling control plane management, scaling, and maintenance tasks.
In Kubernetes-based systems, applications are defined using declarative configuration files. These files describe the desired state of the system, and the orchestration platform ensures that the actual state matches the desired state. This approach allows for highly flexible and automated application management.
Containers in this environment are organized into pods, which are the smallest deployable units in Kubernetes. A pod can contain one or more containers that share networking and storage resources.
Why Organizations Adopt Kubernetes in Cloud Environments
One of the main reasons organizations choose Kubernetes-based orchestration is portability. Applications built on Kubernetes can run on any environment that supports the platform, whether it is a public cloud, private cloud, or hybrid infrastructure.
This portability reduces vendor lock-in and allows organizations to move workloads between environments as needed. It also enables consistent deployment practices across different stages of development, testing, and production.
Another reason is the large ecosystem surrounding Kubernetes. Because it is widely adopted, there is extensive community support, documentation, and third-party tooling available. This ecosystem helps organizations solve complex deployment challenges more easily.
Kubernetes also provides a high degree of customization. Advanced scheduling, networking configurations, and scaling policies can be defined to meet specific application requirements. This flexibility makes it suitable for complex and large-scale distributed systems.
However, this flexibility comes with increased complexity. Kubernetes requires a deeper understanding of its architecture and operational model compared to more simplified orchestration platforms. This is why managed services are often used to reduce operational overhead.
Serverless Container Execution in Orchestration Platforms
Modern container orchestration has evolved to include serverless execution models. In this approach, users do not need to manage the underlying infrastructure that runs containers. Instead, they define the application requirements, and the platform automatically allocates resources.
This model is particularly useful for applications with variable or unpredictable workloads. It eliminates the need to provision and maintain servers, allowing developers to focus solely on application logic.
Both AWS orchestration services support serverless execution options. Containers can be run without managing virtual machines, and scaling is handled automatically based on demand. This approach reduces operational complexity and improves resource efficiency.
Serverless execution also improves cost management. Since resources are allocated dynamically, organizations only pay for the compute capacity they use. This makes it an attractive option for workloads that do not require constant resource allocation.
In addition to cost benefits, serverless models also improve reliability. The underlying platform handles fault tolerance, scaling, and infrastructure maintenance, reducing the likelihood of service disruptions caused by infrastructure issues.
Role of Container Image Management in Deployment Workflows
Container orchestration relies heavily on container images, which serve as the foundation for running applications. These images contain everything needed to execute an application, including code, dependencies, and runtime environments.
Managing these images effectively is crucial for maintaining consistent deployments. A centralized image repository is often used to store and distribute container images across environments.
In AWS-based systems, image repositories are integrated into the broader ecosystem, allowing seamless access during deployment. When a container is launched, the orchestration platform retrieves the appropriate image from the repository and uses it to start the container.
Version control is also an important aspect of image management. Different versions of an application can be stored and deployed independently, allowing teams to roll back to previous versions if needed.
Security scanning is often applied to container images to detect vulnerabilities before deployment. This helps ensure that applications are not exposed to known security risks.
Efficient image management contributes significantly to the reliability and scalability of containerized systems, making it a foundational component of orchestration platforms.
Design Philosophy Behind AWS Native and Kubernetes Approaches
The difference between Amazon’s native container orchestration service and its Kubernetes-based alternative begins at the level of design philosophy. One approach is built around deep integration within a single cloud ecosystem, while the other is designed around portability and open standards.
The native AWS approach prioritizes simplicity within its own environment. It assumes that workloads will primarily run inside AWS infrastructure and optimizes for tight coupling with other cloud services. This design reduces configuration overhead and allows many operational tasks to be automated behind the scenes. The goal is to reduce the number of decisions developers need to make about infrastructure behavior.
In contrast, the Kubernetes-based approach is designed with independence in mind. It assumes that applications may need to run across multiple environments, including different cloud providers or on-premises systems. Instead of relying on tightly integrated services, it uses a standardized orchestration model that behaves consistently regardless of the underlying infrastructure.
This philosophical difference influences nearly every aspect of how the two systems operate, from deployment workflows to scaling strategies and system visibility. One favors convenience within a controlled environment, while the other favors flexibility across diverse environments.
Cluster Management and Control Plane Responsibilities
Cluster management represents one of the most significant differences between the two orchestration approaches. A cluster acts as the foundational structure where containerized workloads are executed, and the way this cluster is managed has a major impact on operational complexity.
In the AWS-native system, cluster management is largely simplified through abstraction. Users define what they want to run, and the platform handles much of the underlying coordination automatically. The infrastructure that supports container execution can be managed directly or abstracted further through serverless compute options. This reduces the need to manually maintain control plane components or handle infrastructure scaling decisions.
In the Kubernetes-based system, cluster management is more explicit. The control plane is responsible for maintaining the overall state of the system, including scheduling, scaling, and monitoring workloads. Although managed services reduce the burden of maintaining the control plane itself, users still interact with a more detailed orchestration model.
The control plane in Kubernetes continuously evaluates the desired state of the system against the actual state and makes adjustments as needed. This reconciliation process is powerful but requires a deeper understanding of how the system operates. The tradeoff is greater control at the cost of increased complexity.
Workload Scheduling and Resource Allocation Differences
Scheduling is the process of determining where and how containers should run within a cluster. It plays a critical role in performance optimization and resource utilization.
In the AWS-native orchestration system, scheduling decisions are often simplified through predefined rules and automatic placement strategies. The platform considers available compute capacity, resource requirements, and constraints to place containers efficiently. Users can define basic preferences, but much of the decision-making is handled automatically.
This approach reduces the need for manual tuning and makes it easier to deploy applications without deep infrastructure knowledge. It is particularly useful for teams that want to focus on application development rather than infrastructure optimization.
In Kubernetes-based orchestration, scheduling is more transparent and configurable. The system uses a scheduler that evaluates multiple factors, including node capacity, affinity rules, and resource requests. Developers can define detailed constraints that influence where workloads are placed.
This level of control allows for highly optimized deployments, especially in complex environments with specific performance or compliance requirements. However, it also introduces additional configuration overhead and requires a deeper understanding of scheduling behavior.
Networking Models and Service Communication Patterns
Networking is a fundamental aspect of container orchestration because modern applications are typically composed of multiple interconnected services. The way these services communicate directly affects performance, reliability, and security.
In the AWS-native system, networking is tightly integrated with the cloud provider’s infrastructure. Containers can communicate within a virtual network environment that is managed as part of the broader cloud ecosystem. Service discovery, load balancing, and traffic routing are handled through built-in mechanisms that reduce configuration complexity.
This integrated networking model allows containers to communicate efficiently without requiring extensive manual setup. External traffic can be routed through managed load-balancing systems that distribute requests across multiple containers automatically.
In Kubernetes-based systems, networking is more modular and relies on a combination of components to achieve similar functionality. A networking layer is required to enable communication between containers across different nodes, and additional tools are often used to manage service discovery and traffic routing.
This modular approach provides flexibility in how networking is configured, but it also requires more setup and maintenance. Different environments may use different networking implementations, which can introduce variability in behavior across deployments.
Security Boundaries and Identity Handling in Both Systems
Security in container orchestration involves controlling access to resources, managing identity, and ensuring secure communication between components. Both systems provide robust security features, but they approach implementation differently.
In the AWS-native system, security is deeply integrated into the broader cloud identity framework. Access to container resources is governed by centralized identity and access management controls. This allows fine-grained permissions to be defined for users, services, and applications.
Containers can assume specific roles that determine what resources they are allowed to access. This approach reduces the need for hardcoded credentials and improves overall security posture. Encryption and secure communication are also integrated into the platform, ensuring that data is protected both at rest and in transit.
In Kubernetes-based orchestration, security is more configurable and layered. Identity management is handled through a combination of system components and external integrations. Access control policies define what actions are allowed within the cluster, and these policies can be customized extensively.
While this provides a high degree of flexibility, it also requires careful configuration to ensure consistent security enforcement. Misconfiguration can lead to unintended access or exposure, making security management a more hands-on responsibility.
Scaling Behavior Under Variable Application Demand
Scaling is one of the most important functions of container orchestration systems. It ensures that applications can handle changes in demand without degrading performance.
In the AWS-native system, scaling is designed to be highly automated. The platform monitors resource usage and application performance, then adjusts the number of running containers accordingly. This allows applications to respond quickly to changes in traffic without manual intervention.
Scaling policies can be defined in simple terms, such as target utilization levels or desired capacity ranges. The system then handles the underlying adjustments automatically, including launching new containers or removing unused ones.
In Kubernetes-based orchestration, scaling is also supported but typically requires more configuration. The system can automatically adjust the number of running containers based on metrics such as CPU or memory usage. However, these behaviors are defined through explicit configuration objects.
This allows for more precise control over scaling behavior but requires a deeper understanding of application performance characteristics. In complex systems, multiple scaling strategies may be combined to achieve optimal results.
Operational Complexity and Learning Curve Considerations
Operational complexity plays a significant role in determining which orchestration system is more appropriate for a given use case. It affects how quickly teams can adopt the technology and how easily they can maintain applications over time.
The AWS-native system is designed to minimize operational complexity. Many infrastructure decisions are abstracted away, allowing users to deploy applications without managing underlying systems in detail. This reduces the learning curve and makes it accessible to teams with limited infrastructure experience.
The Kubernetes-based system, on the other hand, introduces a steeper learning curve. Its flexibility comes with a need for a deeper understanding of orchestration concepts, configuration structures, and system behavior. While this complexity can be challenging, it also enables more advanced use cases and fine-grained control.
Organizations often choose between these systems based on their internal expertise and operational requirements. Simpler systems are easier to adopt, while more complex systems offer greater customization potential.
Hybrid and Multi-Environment Deployment Scenarios
Modern application architectures often extend beyond a single environment. Many organizations operate in hybrid setups that combine cloud infrastructure with on-premises systems or multiple cloud providers.
The Kubernetes-based orchestration model is particularly well-suited for these scenarios. Its design allows applications to run consistently across different environments without significant modification. This makes it easier to move workloads between systems or maintain consistency across distributed infrastructure.
The AWS-native system can also support hybrid scenarios, but it is more closely tied to its own ecosystem. While integration options exist for extending functionality beyond the cloud environment, the system is primarily optimized for workloads running within the provider’s infrastructure.
This difference influences how organizations design their long-term infrastructure strategies. Those prioritizing portability often lean toward Kubernetes-based systems, while those focusing on cloud-centric architectures may prefer native orchestration tools.
Performance Characteristics in Real-World Workloads
Performance in container orchestration is influenced by factors such as scheduling efficiency, networking overhead, and resource allocation strategies.
The AWS-native system is optimized for performance within its own environment. Because it integrates tightly with the underlying infrastructure, it can reduce overhead in communication and resource provisioning. This often results in predictable performance behavior for workloads running entirely within the ecosystem.
Kubernetes-based systems can achieve similar performance levels but may require more tuning. Since they are designed to operate across different environments, there may be additional abstraction layers involved in networking and scheduling. These layers can introduce variability depending on configuration and infrastructure setup.
However, Kubernetes also allows for advanced performance optimization through custom configurations. This makes it suitable for workloads that require specialized tuning or operate under unique constraints.
Cost Structure and Resource Efficiency Tradeoffs
Cost management is an important consideration in container orchestration, especially in large-scale deployments. Both systems influence cost through how efficiently they manage compute resources.
The AWS-native system often provides more straightforward cost management because of its integration with cloud billing and resource optimization features. Automated scaling and serverless execution options can help reduce wasted capacity by ensuring that resources are used only when needed.
The Kubernetes-based system offers more control over resource allocation, which can lead to cost savings in optimized environments. However, achieving this efficiency often requires more manual tuning and monitoring.
In some cases, the flexibility of Kubernetes allows organizations to optimize workloads across multiple environments, potentially reducing overall infrastructure costs. However, this benefit depends heavily on the level of operational maturity and expertise within the organization.
Both systems offer strong resource efficiency capabilities, but they achieve it through different mechanisms—one through automation and integration, and the other through configurability and control.
Deployment Strategies and Application Lifecycle Management
Modern container orchestration is not just about running applications; it is also about managing how those applications evolve. Deployment strategies define how new versions of an application are introduced, how traffic is shifted between versions, and how failures are handled during updates.
In the AWS-native orchestration environment, deployment strategies are designed to reduce operational effort while maintaining application availability. Updates can be rolled out gradually, allowing new versions of an application to replace older ones in controlled stages. This minimizes disruption and helps ensure that users experience stable service even during updates.
The system continuously monitors the health of newly deployed containers. If a problem is detected, the deployment process can automatically pause or roll back changes. This built-in safety mechanism reduces the risk of downtime caused by faulty updates.
Application lifecycle management also includes the ability to maintain multiple versions of a service simultaneously. This allows for testing, phased rollouts, and controlled migration between versions. The orchestration system ensures that desired states are maintained, replacing failed or outdated containers automatically.
In Kubernetes-based orchestration, deployment management is more explicit and configurable. Deployment objects define how applications should be updated, including the number of replicas, update strategies, and rollback conditions. This gives developers precise control over how changes are applied.
Different rollout strategies can be implemented, such as incremental updates or full replacements. The system continuously compares the desired state defined in configuration files with the actual running state, making adjustments to align the two.
This declarative approach provides strong consistency guarantees but requires careful configuration. Application lifecycle management becomes a structured process where every change is defined in advance rather than being automatically inferred by the system.
Observability, Monitoring, and System Visibility
Observability is a critical aspect of managing containerized applications at scale. It refers to the ability to understand the internal state of a system based on its outputs, such as logs, metrics, and traces.
In the AWS-native orchestration system, observability is deeply integrated into the platform. Metrics related to container performance, resource usage, and system health are automatically collected. These metrics can be used to monitor application behavior and trigger scaling or recovery actions.
Logging is also centralized, allowing developers to view output from multiple containers in a unified interface. This makes it easier to diagnose issues and understand system behavior without needing to access individual containers directly.
In Kubernetes-based systems, observability is more modular. The core orchestration system provides basic metrics and logs, but additional tools are often used to build a complete observability stack. This may include monitoring systems, logging frameworks, and distributed tracing tools.
This modular approach offers flexibility in how observability is implemented, but requires more setup and integration effort. Organizations can choose the tools that best fit their needs, but they must also ensure that these tools work together effectively.
Both systems support deep visibility into container behavior, but they differ in how much is provided out of the box versus how much must be assembled from components.
Fault Tolerance and Self-Healing Mechanisms
Fault tolerance is one of the key advantages of container orchestration systems. It ensures that applications remain available even when individual components fail.
In the AWS-native system, fault tolerance is built into the orchestration layer. If a container fails or becomes unresponsive, it is automatically replaced with a new instance. The system continuously monitors the health of running containers and takes corrective action when needed.
This self-healing behavior reduces the need for manual intervention and improves overall system reliability. It also ensures that applications maintain their desired state even in the presence of infrastructure failures.
In Kubernetes-based orchestration, fault tolerance is achieved through a similar reconciliation process. The system continuously checks whether the actual state of the cluster matches the desired state defined in configuration files. If discrepancies are detected, corrective actions are taken automatically.
This may involve restarting failed containers, rescheduling workloads to healthy nodes, or adjusting resource allocations. The system is designed to be resilient and self-correcting, but it relies on proper configuration to function effectively.
Both systems provide strong fault tolerance capabilities, but they differ in how much is automated versus how much is defined by configuration.
Integration with Application Development Workflows
Container orchestration does not exist in isolation; it is closely connected to application development workflows. Developers need to build, test, and deploy applications continuously, often in automated pipelines.
In the AWS-native environment, integration with development workflows is streamlined through tightly coupled services. Container images can be built, stored, and deployed using integrated tools that reduce friction between development and production environments.
This allows for faster iteration cycles and smoother transitions from development to deployment. The orchestration system automatically pulls updated images and deploys them according to defined policies.
In Kubernetes-based environments, integration with development workflows is more flexible but also more complex. Developers typically use external tools to build and manage container images, and deployment pipelines must be configured to interact with the orchestration system.
This modular approach allows organizations to design custom workflows that fit their specific needs. However, it also requires more coordination between different systems and tools.
The difference between the two approaches reflects a broader tradeoff between simplicity and flexibility in application lifecycle management.
Multi-Tenant Environments and Workload Isolation
In many organizations, container orchestration systems are used to support multiple teams or applications within a shared infrastructure. This introduces the need for workload isolation and resource governance.
In the AWS-native system, isolation is achieved through resource boundaries and identity-based access control. Different applications or teams can be assigned specific resource limits and permissions, ensuring that workloads do not interfere with each other.
The platform enforces these boundaries automatically, reducing the risk of resource contention or unauthorized access. This makes it easier to manage multi-tenant environments without extensive manual configuration.
In Kubernetes-based systems, isolation is achieved through namespaces and resource quotas. Namespaces provide logical separation between different workloads, while quotas control how much compute resources each workload can consume.
This approach is highly flexible and allows for detailed customization of resource allocation policies. However, it requires careful configuration to ensure that isolation boundaries are properly enforced.
Both systems support multi-tenant environments effectively, but they differ in how much of the enforcement is automatic versus manually configured.
Portability and Vendor Independence Considerations
One of the most important factors influencing the choice between orchestration systems is portability. Portability refers to the ability to move applications between different environments without significant modification.
The AWS-native system is closely tied to its cloud ecosystem. While it offers strong integration and ease of use within that environment, it is less portable across different platforms. Applications built on this system are typically optimized for deployment within a single cloud provider.
In contrast, Kubernetes-based orchestration is designed specifically for portability. Applications defined using Kubernetes standards can run across different cloud providers or on-premises environments with minimal changes.
This makes Kubernetes particularly attractive for organizations that want to avoid dependency on a single vendor or maintain flexibility in their infrastructure strategy. It also supports hybrid and multi-cloud architectures more naturally.
However, portability comes with its own challenges. Ensuring consistent behavior across different environments may require additional configuration and testing.
Operational Maturity and Organizational Readiness
The choice between orchestration systems is often influenced by an organization’s level of operational maturity. This includes factors such as infrastructure expertise, automation capabilities, and DevOps practices.
The AWS-native system is often favored by teams that prioritize simplicity and rapid adoption. Its managed nature reduces the need for deep infrastructure expertise, allowing teams to focus on application development rather than system administration.
This makes it suitable for organizations that are transitioning to cloud-native architectures or that prefer a more guided operational model.
Kubernetes-based orchestration, on the other hand, is often adopted by organizations with more mature infrastructure practices. It requires a deeper understanding of distributed systems and orchestration concepts, but it also provides greater control and flexibility.
Organizations that invest in Kubernetes typically develop strong automation pipelines and infrastructure-as-code practices to manage complexity effectively.
Long-Term Evolution of Container Orchestration Models
Container orchestration continues to evolve as application architectures become more distributed and dynamic. New patterns such as microservices, event-driven systems, and serverless computing are influencing how orchestration platforms are designed and used.
The AWS-native system continues to evolve toward deeper automation and integration. The goal is to reduce operational overhead further and make container management increasingly invisible to end users.
Kubernetes continues to evolve as a flexible standard for distributed application management. Its ecosystem is expanding, with new tools and extensions being developed to address emerging use cases.
Both systems are adapting to support modern cloud-native architectures, but they are doing so from different directions—one emphasizing managed simplicity and the other emphasizing extensibility and portability.
Interaction Between Serverless Computing and Container Orchestration
Serverless computing has introduced a new layer of abstraction above traditional container orchestration. In this model, developers focus entirely on application logic while the underlying infrastructure is managed automatically.
In AWS environments, serverless container execution integrates directly with orchestration systems. Containers can be executed without provisioning or managing servers, allowing for highly dynamic scaling and resource allocation.
This model is particularly useful for workloads with unpredictable traffic patterns or short-lived execution requirements. It eliminates the need to manage infrastructure capacity manually.
Kubernetes-based systems also support serverless-like behavior through additional layers and extensions. However, this typically requires integrating external tools or platforms that provide similar functionality.
The relationship between serverless computing and container orchestration represents an ongoing shift toward higher levels of abstraction in cloud computing.
Strategic Considerations in Selecting an Orchestration Approach
Choosing between orchestration systems involves evaluating multiple strategic factors, including operational complexity, portability, scalability, and long-term infrastructure goals.
The AWS-native system is often selected for its simplicity, deep integration, and managed nature. It reduces operational burden and allows teams to deploy applications quickly within a single cloud environment.
The Kubernetes-based system is chosen for its flexibility, portability, and strong ecosystem support. It is better suited for organizations that require multi-environment deployments or advanced customization.
Both approaches are capable of supporting large-scale, production-grade applications, but they align with different organizational priorities and technical strategies.
As cloud computing continues to evolve, container orchestration will remain a central component of modern application architecture, shaping how software is built, deployed, and maintained across diverse environments.
Conclusion
Container orchestration has become a foundational element of modern cloud computing, shaping how applications are deployed, managed, and scaled in distributed environments. As software systems continue to grow in complexity, the need for reliable automation, efficient resource management, and consistent deployment practices has become increasingly important. Both AWS-native container orchestration and Kubernetes-based orchestration address these needs, but they do so through different design philosophies and operational models.
The AWS-native approach focuses on simplifying container management within a tightly integrated cloud ecosystem. It reduces the operational burden on teams by abstracting much of the underlying infrastructure complexity. This allows developers and organizations to deploy applications more quickly without needing deep expertise in system administration or distributed systems architecture. By integrating closely with other cloud services, it provides a streamlined experience where networking, scaling, security, and monitoring are unified under a single operational framework. This makes it particularly suitable for teams that prioritize ease of use, rapid deployment, and minimal infrastructure management overhead.
On the other hand, Kubernetes-based orchestration represents a more flexible and widely adopted standard for container management across diverse environments. Its strength lies in portability and extensibility, enabling applications to run consistently across different cloud providers and on-premises infrastructure. This makes it an ideal choice for organizations that require hybrid or multi-cloud strategies, or that want to avoid dependency on a single vendor. Kubernetes also offers a high degree of customization, allowing teams to fine-tune scheduling, networking, scaling, and security to meet specific application requirements. However, this flexibility comes with increased operational complexity and a steeper learning curve.
Despite their differences, both approaches share a common goal: enabling scalable, resilient, and efficient application delivery. They both support automation of critical tasks such as deployment, recovery, and scaling, ensuring that applications remain available and performant even under changing workloads. They also both integrate with modern DevOps practices, supporting continuous integration and continuous deployment workflows that accelerate software delivery cycles.
Another important aspect of both systems is their role in enabling modern architectural patterns such as microservices and distributed computing. Containers and orchestration platforms allow applications to be broken into smaller, independently deployable components, improving maintainability and scalability. This shift has fundamentally changed how software is designed and operated, moving away from monolithic systems toward more modular and dynamic architectures.
Ultimately, the choice between AWS-native orchestration and Kubernetes-based orchestration is not about which is universally better, but about which aligns more closely with an organization’s goals, expertise, and infrastructure strategy. Some organizations benefit from the simplicity and deep integration of a managed cloud-native system, while others require the flexibility and portability offered by an open-source standard that works across multiple environments.
As cloud technologies continue to evolve, container orchestration will remain at the center of innovation in application deployment. It will continue to adapt to new computing paradigms, including serverless architectures, edge computing, and hybrid cloud ecosystems. Understanding the strengths and tradeoffs of each orchestration approach is essential for building scalable, resilient, and future-ready systems in an increasingly distributed digital landscape.