The journey from an idea to a fully functioning application has never been more accessible than it is today. With cloud computing reshaping how software is built and deployed, developers are no longer required to manage physical infrastructure or worry about provisioning servers manually. Among the many innovations driving this transformation, serverless computing stands out as a model that allows developers to focus purely on code while cloud providers handle the underlying systems. Within this ecosystem, choosing the right way to store and manage data becomes one of the most critical decisions you will make.
When building a serverless application using services such as Amazon Web Services offerings like AWS Lambda and Amazon API Gateway, the database layer must align with the same philosophy: minimal operational overhead, scalability on demand, and seamless integration. This is where serverless databases come into play. Understanding what they are, how they differ from traditional databases, and why they matter is the first step toward making an informed decision.
The Evolution of Data Storage in Application Development
To understand serverless databases, it helps to look at how data storage has evolved over time. In earlier computing environments, applications were often hosted on dedicated servers within an organization’s infrastructure. Databases were installed, configured, and maintained manually. This meant handling hardware failures, scaling limitations, backups, and security measures internally. It required significant expertise and resources, often involving specialized database administrators.
As cloud computing matured, organizations began migrating their workloads to cloud platforms. Instead of maintaining physical hardware, they could rent virtual machines and deploy databases on them. While this reduced some operational burden, it still required manual setup, patching, and scaling decisions. The responsibility shifted, but it did not disappear.
The next stage in this evolution was the introduction of managed databases. Cloud providers began offering database services where much of the operational work was handled automatically. Tasks such as backups, updates, and scaling were partially or fully managed by the provider. This allowed developers to focus more on application logic rather than infrastructure.
Serverless databases represent the latest step in this progression. They take the concept of managed services even further by removing the need to think about servers altogether. Instead of provisioning capacity in advance, resources are allocated dynamically based on demand. You pay only for what you use, and the system automatically scales up or down as needed.
What Makes a Database “Serverless”
The term “serverless” can be misleading at first glance. Servers still exist, but they are abstracted away from the user. In a serverless database, you do not manage the underlying hardware, operating system, or database engine directly. Instead, you interact with the database through APIs or managed interfaces provided by the cloud platform.
This abstraction brings several key characteristics. First, there is automatic scaling. Whether your application has ten users or ten million, the database adjusts its capacity accordingly. Second, there is no need for manual provisioning. You do not have to decide in advance how much storage or compute power you will need. Third, maintenance tasks such as patching, backups, and replication are handled automatically.
Another defining feature is the billing model. Traditional databases often require you to pay for allocated resources regardless of usage. Serverless databases, on the other hand, typically charge based on actual consumption. This makes them particularly appealing for applications with unpredictable or fluctuating workloads.
Comparing Traditional and Serverless Approaches
Traditional databases give you full control over configuration and performance tuning. This can be beneficial for highly specialized applications that require precise optimization. However, it also comes with increased complexity. You need to monitor performance, apply updates, and ensure availability manually.
Serverless databases trade some of that control for convenience and efficiency. They are designed to handle common use cases without requiring deep infrastructure knowledge. For many applications, this trade-off is worthwhile because it significantly reduces the time and effort needed to manage the system.
Another difference lies in scalability. In traditional setups, scaling often involves adding more servers or upgrading existing ones. This process can be time-consuming and may require downtime. Serverless databases handle scaling automatically and often instantly, making them ideal for applications that experience sudden spikes in traffic.
Reliability is another important factor. Managed and serverless databases are typically built with high availability in mind. They use techniques such as replication and distributed architecture to ensure that data remains accessible even if part of the system fails.
The Role of Serverless Databases in Application Architecture
In a serverless application, different components communicate through lightweight, event-driven mechanisms. For example, a user request might trigger a function in a serverless compute service, which then interacts with a database to retrieve or store information. This modular design allows each component to scale independently.
The database plays a central role in this architecture. It must be able to handle frequent, short-lived connections and respond quickly to requests. Serverless databases are designed with these requirements in mind. They support rapid scaling, low latency, and flexible data models.
Because serverless applications often rely on microservices, the database layer must also support diverse data needs. Different parts of the application may require different types of data storage. For instance, one component might need structured data with strict relationships, while another might handle unstructured or semi-structured data.
This is why cloud providers offer a variety of database types within their serverless ecosystem. Each type is optimized for specific use cases, allowing developers to choose the most appropriate solution for each part of their application.
Exploring Database Types Available in Serverless Environments
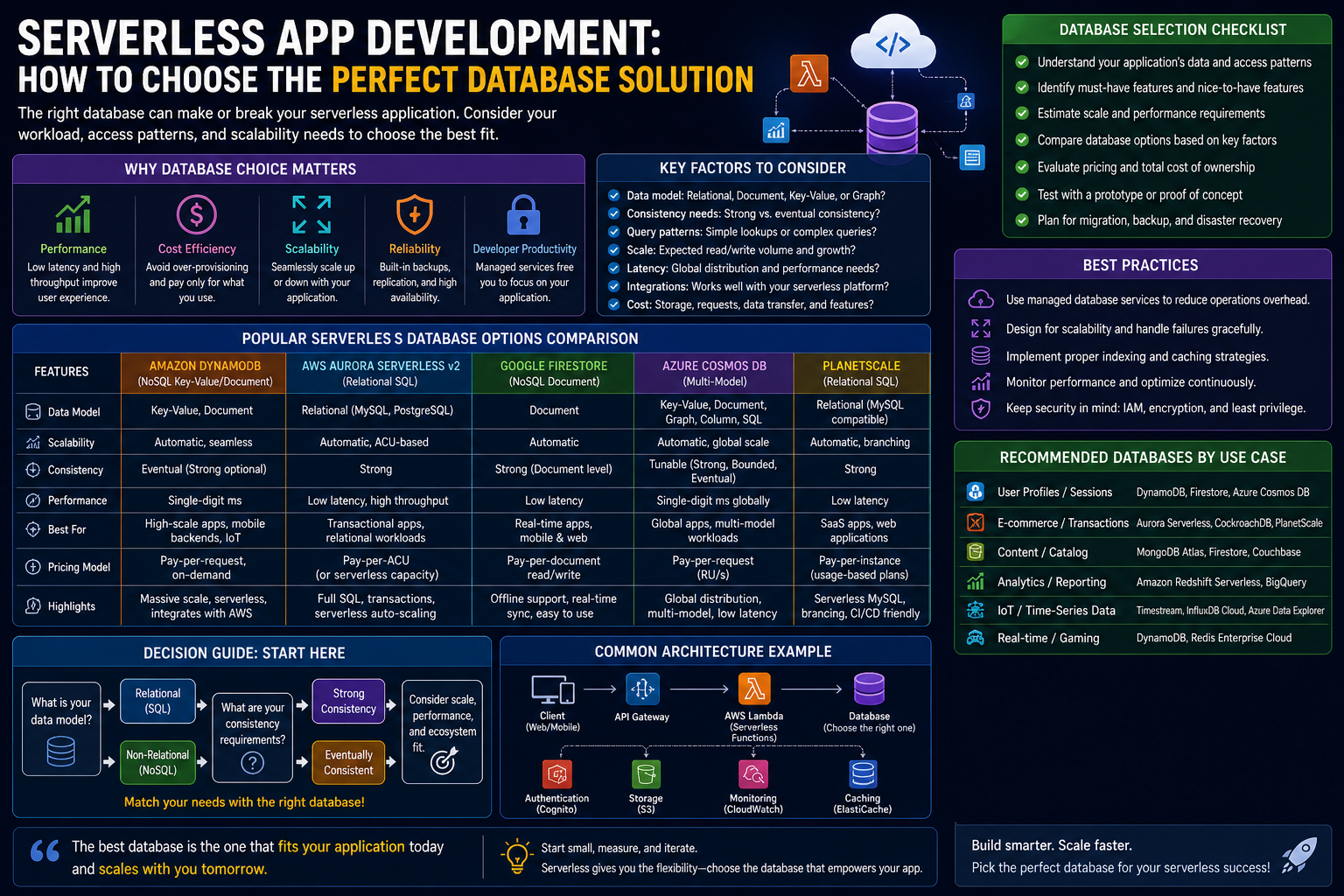
Cloud platforms provide multiple database models to accommodate different application requirements. Among the most commonly used are relational and document databases, but there are several others designed for specialized use cases.
Relational databases organize data into tables with rows and columns. They use structured schemas and support complex queries through SQL. These databases are well-suited for applications that require strong consistency and well-defined relationships between data elements. Examples in the serverless space include services like Amazon Aurora and Amazon RDS.
Document databases, often categorized under NoSQL, store data in flexible formats such as JSON-like structures. They allow for dynamic schemas, making them ideal for applications where data requirements may evolve over time. A widely recognized example is MongoDB, while cloud-native equivalents include Amazon DocumentDB.
Key-value databases are another type commonly used in serverless applications. They store data as simple pairs, making them extremely fast and efficient for certain tasks. These databases are often used for caching, session management, and real-time data processing.
In-memory databases focus on speed by storing data in RAM rather than on disk. This allows for extremely fast read and write operations. Services like Redis are frequently used in this role, often as a caching layer to improve application performance.
Other database types include graph databases for handling complex relationships, time-series databases for tracking data over time, and ledger databases for maintaining immutable records. While these are less commonly used, they can be essential for specific applications.
Why Serverless Databases Are Gaining Popularity
The growing adoption of serverless databases is driven by several factors. One of the most significant is the reduction in operational complexity. Developers no longer need to spend time managing infrastructure, allowing them to focus on building features and improving user experience.
Scalability is another major advantage. Modern applications often experience unpredictable traffic patterns. A serverless database can handle sudden increases in demand without requiring manual intervention. This ensures that the application remains responsive even under heavy load.
Cost efficiency also plays a role. By charging based on actual usage, serverless databases eliminate the need to pay for unused capacity. This is particularly beneficial for startups and small teams that need to manage resources carefully.
Security is another important consideration. Managed services typically include built-in security features such as encryption, access controls, and monitoring. While developers still need to follow best practices, the underlying platform provides a strong foundation for protecting data.
Challenges and Considerations
Despite their advantages, serverless databases are not a perfect solution for every scenario. One potential challenge is the lack of control over the underlying infrastructure. For applications that require highly customized configurations, this can be a limitation.
Latency can also be a concern in some cases. Because serverless databases rely on dynamic scaling, there may be slight delays when resources are allocated. This is often referred to as a “cold start” effect, although it is generally minimal in well-optimized systems.
Cost can become an issue if usage patterns are not carefully managed. While the pay-as-you-go model is efficient for many applications, high volumes of requests can lead to increased expenses. It is important to monitor usage and optimize queries to keep costs under control.
Another consideration is vendor dependency. Using a serverless database often means relying on a specific cloud provider’s ecosystem. Migrating to another platform can be challenging, especially if the application is tightly integrated with proprietary services.
Understanding Data Needs Before Making a Choice
Before selecting a database for a serverless application, it is essential to understand the nature of the data you will be working with. This includes considering how the data will be structured, how it will be accessed, and how it may evolve over time.
Applications with well-defined data models and complex relationships often benefit from relational databases. These systems provide strong consistency and support advanced querying capabilities. They are particularly useful for applications such as financial systems, inventory management, and enterprise software.
On the other hand, applications with flexible or rapidly changing data requirements may be better suited to document databases. These systems allow for greater adaptability, making them ideal for startups and projects in the early stages of development.
Performance requirements also play a role. Applications that require real-time responses or handle large volumes of data may need specialized database types such as in-memory or key-value stores.
The Importance of Planning for Growth
One of the most common mistakes in application development is failing to plan for growth. An application that works well with a small user base may encounter challenges as it scales. Serverless databases help address this issue by providing automatic scaling, but it is still important to design the system with future growth in mind.
This includes considering factors such as data volume, query complexity, and access patterns. It is also important to think about how the application may evolve over time. Features that are not part of the initial version may become essential later, and the database should be able to accommodate these changes.
By taking a forward-looking approach, developers can avoid costly redesigns and ensure that their application remains robust as it grows.
Integrating Databases with Serverless Workflows
In a serverless environment, integration is key. The database must work seamlessly with other components such as compute functions, APIs, and event-driven services. This requires careful design and consideration of how data flows through the system.
For example, a typical workflow might involve a user request being processed by a serverless function, which then interacts with the database to retrieve or store information. The response is then returned to the user through an API. Each step in this process must be optimized for performance and reliability.
Serverless databases are designed to support these workflows by providing efficient APIs and integration with other cloud services. This allows developers to build complex applications without having to manage the underlying infrastructure.
Building a Strong Foundation for Your Application
Choosing the right database is one of the most important decisions you will make when building a serverless application. It affects not only how data is stored and accessed but also how the application performs, scales, and evolves over time.
By understanding the principles behind serverless databases and the options available, you can make an informed decision that aligns with your application’s needs. This involves considering factors such as data structure, scalability, performance, and cost.
A well-chosen database provides a strong foundation for your application, enabling you to focus on innovation and user experience. As serverless computing continues to evolve, the role of databases will remain central to building efficient and scalable systems.
Deep Dive into Serverless Database Choices for Modern Applications
As serverless computing continues to reshape how applications are designed and deployed, the database layer has become one of the most important architectural decisions a developer must make. While the first part explored what serverless databases are and how they fit into modern application design, the next step is understanding how to evaluate them in real-world scenarios. This involves looking beyond definitions and focusing on performance, structure, scalability behavior, cost implications, and long-term maintainability.
When building applications with services such as AWS Lambda and Amazon API Gateway within the ecosystem of Amazon Web Services, the database must not only store data efficiently but also respond quickly under unpredictable workloads. The challenge is not simply choosing a database—it is choosing the right type of database for a specific workload pattern in a serverless environment where scaling and latency behave differently from traditional systems.
Understanding Workload Patterns in Serverless Applications
Before selecting any database, it is essential to understand how serverless applications behave under real usage conditions. Unlike traditional applications that run continuously on dedicated servers, serverless applications operate in response to events. These events may include HTTP requests, file uploads, background jobs, scheduled tasks, or data stream processing.
This event-driven nature creates highly variable workloads. At one moment, the application may be idle. In the next moment, it may experience a sudden spike in traffic due to a viral event, seasonal demand, or batch processing job. This unpredictability is one of the defining characteristics of serverless architecture.
Because of this, the database must be capable of handling sudden bursts of requests without manual intervention. It must also scale down efficiently during idle periods to avoid unnecessary cost. Traditional databases often struggle in this area because they rely on pre-provisioned capacity. Serverless databases, in contrast, are designed specifically for this kind of dynamic environment.
Understanding workload patterns also involves identifying whether your application is read-heavy, write-heavy, or balanced. A social media feed, for example, is typically read-heavy, while a logging system may be write-heavy. Each of these scenarios influences the type of database that will perform best.
Relational Databases in Serverless Architectures
Relational databases remain one of the most widely used data storage systems in software development. They are built on structured schemas, where data is organized into tables with rows and columns. Relationships between tables are defined using keys, allowing complex queries and joins.
In serverless environments, relational databases are often used when data consistency and structure are critical. Applications such as financial systems, booking platforms, and inventory management systems rely on strict relationships between data entities.
Services like Amazon Aurora and Amazon RDS provide relational database capabilities in a managed and scalable form. These systems reduce operational overhead while maintaining the powerful querying capabilities of traditional SQL databases.
However, relational databases in serverless environments introduce unique considerations. One of the main challenges is connection management. Serverless functions can scale rapidly, creating a large number of short-lived database connections. Traditional relational databases may struggle with this pattern if not properly configured.
To address this, many serverless relational systems use connection pooling or proxy layers that manage connections efficiently. This ensures that the database is not overwhelmed by sudden spikes in connection requests.
Another consideration is schema rigidity. Relational databases require predefined schemas, which means changes to data structure must be carefully planned. While this provides stability, it can slow down development in rapidly evolving applications.
When Relational Databases Are the Right Choice
Relational databases are most suitable when your data is highly structured and relationships between entities are clearly defined. For example, consider an e-commerce platform. Products, customers, orders, and payments all have well-defined relationships that must remain consistent.
In such cases, relational databases provide strong guarantees through ACID properties—atomicity, consistency, isolation, and durability. These properties ensure that transactions are reliable, even in complex operations involving multiple tables.
Relational databases are also ideal when reporting and analytics require complex joins and aggregations. Their ability to handle structured queries efficiently makes them powerful tools for business intelligence applications.
However, the trade-off is reduced flexibility. If your application requires frequent schema changes or deals with unpredictable data formats, relational databases may introduce unnecessary complexity.
Document Databases and Flexibility in Serverless Systems
Document databases represent a more flexible approach to data storage. Instead of structured tables, they store data in documents, often using formats similar to JSON. Each document can have a different structure, allowing developers to adapt quickly to changing requirements.
In serverless environments, document databases are particularly popular because they align well with agile development practices. Applications can evolve without requiring strict schema migrations.
A widely used example in this category is MongoDB, while cloud-native implementations include Amazon DocumentDB. These systems are designed to handle large-scale, unstructured, or semi-structured data efficiently.
Document databases are especially useful in applications where data models are not fully defined at the start of development. Startups and early-stage projects often benefit from this flexibility because it allows rapid iteration.
For example, a content management system may start with simple article storage but later expand to include multimedia content, user interactions, and metadata. A document database can accommodate these changes without requiring major restructuring.
Advantages of Document Databases in Serverless Environments
One of the main advantages of document databases is their ability to scale horizontally with ease. Since documents are independent of each other, they can be distributed across multiple nodes without complex relational mapping.
This makes them highly compatible with serverless architectures, where scalability is a core requirement. They also reduce the need for complex joins, which can be expensive in distributed systems.
Another advantage is developer productivity. Because the schema is flexible, developers can focus on application logic rather than database design. This speeds up development cycles and allows for faster experimentation.
However, this flexibility comes with trade-offs. Without strict schemas, data consistency can become harder to enforce. It is the responsibility of the application layer to ensure data integrity, which can increase complexity in large systems.
Key-Value Stores and High-Speed Data Access
Key-value databases are among the simplest and fastest types of databases available. They store data as pairs, where each key is associated with a value. This simplicity allows for extremely fast read and write operations.
In serverless applications, key-value stores are often used for caching, session storage, and real-time data retrieval. Their speed makes them ideal for scenarios where low latency is critical.
A well-known example of an in-memory key-value system is Redis. In cloud environments, similar functionality is provided through managed services that scale automatically.
Key-value databases are particularly effective when the application does not require complex querying. For instance, storing user session data or caching API responses does not require relational structure.
Because of their simplicity, key-value stores scale extremely well. They can handle large volumes of requests with minimal overhead, making them a natural fit for serverless systems that require rapid response times.
In-Memory Databases and Performance Optimization
In-memory databases take performance even further by storing data directly in system memory rather than on disk. This eliminates the latency associated with disk I/O and enables extremely fast data access.
These databases are often used as caching layers in serverless architectures. Instead of querying a primary database for every request, applications can retrieve frequently accessed data from memory, significantly improving performance.
However, in-memory databases are typically not used as primary storage systems for critical data. Because memory is volatile, data may be lost in case of failure unless persistence mechanisms are implemented.
In serverless environments, in-memory databases are often combined with other database types to create hybrid architectures. This allows applications to balance speed and durability effectively.
Graph Databases for Relationship-Centric Applications
Graph databases are designed to handle complex relationships between data entities. Instead of tables or documents, they use nodes and edges to represent connections.
This structure is particularly useful in applications such as social networks, recommendation engines, and fraud detection systems. These systems rely heavily on understanding relationships between entities rather than just storing isolated records.
In serverless architectures, graph databases can be used to efficiently process relationship-heavy queries without expensive joins. They allow developers to traverse connections quickly, making them ideal for real-time analytics.
Time-Series and Ledger Databases in Specialized Use Cases
Time-series databases are optimized for storing data that changes over time. This includes metrics, logs, and sensor data. They are commonly used in monitoring systems, IoT applications, and financial analytics.
Ledger databases, on the other hand, are designed for maintaining immutable records. They provide a tamper-proof history of transactions, making them suitable for auditing and compliance systems.
Both of these database types serve specialized roles in serverless architectures. While they are not used in general-purpose applications, they become essential in specific domains where data structure and integrity requirements are unique.
Performance Considerations in Serverless Databases
Performance in serverless databases is influenced by several factors, including cold starts, connection latency, and data distribution. Because resources are allocated dynamically, there may be slight delays when scaling begins.
Another important factor is query optimization. Inefficient queries can lead to increased latency and higher costs. In serverless environments, where billing is often based on usage, optimizing queries becomes even more important.
Data partitioning and indexing also play a critical role. Properly designed indexes can significantly reduce query time, especially in large datasets.
Cost Implications of Serverless Database Usage
One of the most attractive aspects of serverless databases is their pricing model. Instead of paying for fixed capacity, users pay based on actual usage. This includes storage, read/write operations, and data transfer.
However, this model requires careful monitoring. Applications with high traffic or inefficient queries can accumulate significant costs over time. Unlike traditional databases where costs are predictable, serverless databases require continuous optimization.
Understanding usage patterns is essential for managing costs effectively. This includes analyzing read/write ratios, peak usage times, and data growth trends.
Security and Compliance in Serverless Data Systems
Security is a fundamental aspect of any database system, and serverless databases are no exception. Cloud providers implement multiple layers of security, including encryption at rest, encryption in transit, and identity-based access control.
However, responsibility is shared between the provider and the developer. While the infrastructure is secured by the provider, application-level security must still be implemented correctly.
This includes controlling access permissions, validating inputs, and ensuring proper authentication mechanisms. Compliance requirements may also influence database selection, especially in regulated industries such as healthcare and finance.
Designing for Scalability in Serverless Databases
Scalability is one of the core benefits of serverless architecture. However, achieving true scalability requires careful system design. This includes selecting the right database type, optimizing queries, and structuring data efficiently.
Horizontal scaling is often preferred in serverless systems, as it allows the database to distribute workload across multiple nodes. This ensures consistent performance even under heavy load.
Event-driven design also plays a role in scalability. By decoupling components, serverless applications can scale independently, reducing bottlenecks and improving resilience.
Advanced Decision-Making for Serverless Databases in Real-World Systems
As serverless architecture becomes a standard approach for building modern applications, the database layer increasingly determines whether a system feels fast, reliable, and cost-efficient or unpredictable and difficult to maintain. Earlier discussions covered what serverless databases are and how different types behave under workload pressure. The final step is understanding how to bring all of that knowledge together into real-world decision-making.
When applications are built using services like AWS Lambda and Amazon API Gateway within the ecosystem of Amazon Web Services, the database is no longer just a storage layer. It becomes part of an event-driven system where speed, elasticity, and integration matter more than traditional infrastructure control. Choosing the wrong database can lead to scaling bottlenecks, unexpected costs, or unnecessary complexity that slows development.
This part focuses on how to evaluate trade-offs, design database strategies, handle scaling challenges, and align database choices with real application needs rather than theoretical preferences.
Matching Database Types to Application Behavior
The most important principle in serverless database selection is that there is no universal “best” database. Instead, there are only databases that fit specific patterns of behavior. Understanding application behavior is more important than understanding database features in isolation.
Serverless applications are typically built around events. These events can be user actions, system triggers, scheduled tasks, or external integrations. Each event may require different data handling patterns. Some operations demand strict consistency, while others prioritize speed or flexibility.
For example, a user authentication system requires fast and reliable access to user credentials. A product catalog system may need flexible schema evolution. A logging system must handle massive write volumes efficiently. Each of these requires a different storage strategy.
Relational systems such as Amazon RDS or Amazon Aurora are best suited for structured and consistent data models. Meanwhile, document-oriented systems like Amazon DocumentDB or MongoDB are more flexible and adapt well to evolving application requirements.
Key-value and in-memory systems such as Redis are ideal for performance-critical use cases where speed matters more than complex relationships.
The key idea is not to choose one database for everything, but to match each part of the application to the most suitable storage model.
The Rise of Polyglot Persistence in Serverless Systems
Modern serverless applications rarely rely on a single database type. Instead, they use multiple databases together in what is often called polyglot persistence. This approach allows each component of the system to use the most appropriate data storage model.
For example, an e-commerce system might use a relational database for orders and payments, a document database for product catalogs, and an in-memory database for caching user sessions. Each system is optimized for its specific workload.
This separation improves performance and scalability, but it also introduces complexity. Developers must manage multiple data sources, ensure consistency across systems, and design workflows that coordinate between databases.
Serverless architecture actually makes this easier because services are loosely coupled. Each function can interact with a specific database without being tightly bound to others. However, this requires careful design of data flows and event handling.
A key challenge in polyglot systems is ensuring data consistency. Since different databases may update independently, synchronization strategies must be implemented at the application level. This is often done through event-driven communication or asynchronous processing.
Designing Data Flow in Event-Driven Architectures
In serverless systems, data does not flow through a single centralized pipeline. Instead, it moves through a series of independent functions and services. This creates a distributed data flow model where each component performs a small task.
For example, when a user places an order, the request may trigger a serverless function that writes order data to a relational database. Another function may update inventory in a separate system. A third function may send confirmation notifications.
Each of these steps may interact with different databases. This means the database design must support distributed workflows rather than centralized control.
One of the most important design principles in this model is eventual consistency. Unlike traditional systems that enforce immediate consistency across all data, serverless systems often allow temporary inconsistencies that are resolved over time.
This approach improves scalability and performance but requires careful handling of failure scenarios. If one part of the system fails, retry mechanisms and event tracking must ensure that data eventually reaches a consistent state.
Handling Connection Scaling in Serverless Databases
One of the most common technical challenges in serverless database design is connection management. Serverless functions can scale rapidly, creating hundreds or thousands of simultaneous connections in a short period of time.
Traditional databases are not designed to handle this kind of burst behavior. If each function opens a new connection, the database can quickly become overwhelmed.
To solve this, modern serverless databases often use connection pooling or proxy layers. These systems reuse existing connections instead of creating new ones for each request. This reduces overhead and improves performance.
Some systems also introduce serverless-native connection models, where the database itself is designed to handle ephemeral connections efficiently. This is particularly important in environments where functions scale up and down frequently.
Proper connection handling is essential for maintaining stability in serverless systems. Without it, even a well-designed application can suffer from performance degradation under load.
Data Modeling Strategies for Serverless Environments
Data modeling in serverless applications differs significantly from traditional systems. Because of the distributed nature of the architecture, models must be designed for independent access rather than centralized querying.
In relational systems, normalization is often used to reduce redundancy. However, in serverless systems, excessive normalization can lead to performance issues due to frequent joins across distributed components.
Instead, denormalization is often used strategically. Data is duplicated in certain areas to reduce the need for cross-database queries. While this increases storage usage, it improves speed and scalability.
In document databases, data is often modeled around access patterns rather than strict structure. Developers design documents based on how the data will be used rather than how it is logically related.
This shift in mindset is important. Instead of asking “How should this data be structured?”, serverless developers often ask “How will this data be accessed?”
Managing Latency in Distributed Database Systems
Latency is a critical factor in serverless applications. Because functions are often short-lived and triggered by user interactions, even small delays can impact user experience.
Database latency can come from multiple sources, including network delays, cold starts, query complexity, and scaling operations.
To minimize latency, developers often use caching layers, in-memory databases, and optimized indexing strategies. Placing data closer to compute resources also reduces network overhead.
In global applications, data may need to be replicated across multiple regions. This introduces additional complexity but ensures faster access for users in different geographic locations.
Serverless databases are designed to handle many of these challenges automatically, but application design still plays a major role in overall performance.
Security Architecture in Serverless Databases
Security in serverless databases is a shared responsibility between the cloud provider and the application developer. While providers handle infrastructure security, developers must secure access patterns and application logic.
Most serverless databases include built-in encryption, both at rest and in transit. They also integrate with identity and access management systems that control who can access data and under what conditions.
However, misconfigured permissions remain one of the most common security risks. Overly broad access policies can expose sensitive data, even in managed environments.
Another important aspect of security is input validation. Serverless applications often interact with external sources, making them vulnerable to injection attacks if inputs are not properly sanitized.
Because serverless systems are highly distributed, monitoring and logging are also essential. Security events must be tracked across multiple services to ensure visibility into system behavior.
Cost Optimization Strategies for Serverless Databases
While serverless databases eliminate the need for fixed infrastructure costs, they introduce variable pricing models that depend on usage. This makes cost optimization an important part of system design.
One of the most effective strategies is optimizing query patterns. Inefficient queries not only slow down applications but also increase costs due to higher resource consumption.
Another strategy is using caching layers to reduce database reads. By storing frequently accessed data in memory, applications can reduce the number of database operations.
Data lifecycle management is also important. Older or unused data can be archived or moved to lower-cost storage tiers.
Understanding usage patterns helps identify cost-saving opportunities. For example, applications with predictable traffic may benefit from reserved capacity options, while highly variable workloads are better suited to pure pay-per-use models.
Migration Challenges When Moving to Serverless Databases
Migrating from traditional databases to serverless systems is not always straightforward. One of the biggest challenges is adapting existing schemas and queries to new data models.
Applications that rely heavily on relational joins may need to be redesigned for distributed data access. This can require significant architectural changes.
Another challenge is data migration itself. Large datasets must be transferred without disrupting application availability. This often involves phased migration strategies where both systems run in parallel during transition.
Testing is also critical. Because serverless systems behave differently under load, performance testing must simulate real-world traffic patterns.
Despite these challenges, migration can offer significant long-term benefits in scalability and operational efficiency.
Building Resilient Serverless Data Architectures
Resilience is a key goal in serverless system design. Since components are distributed, failure in one part of the system should not bring down the entire application.
Databases play a central role in resilience strategies. Many serverless databases are designed with built-in redundancy, replication, and automatic failover mechanisms.
However, application-level resilience is equally important. This includes retry logic, fallback mechanisms, and event replay systems.
By designing for failure rather than assuming reliability, serverless systems can achieve high availability even under unpredictable conditions.
Designing for Long-Term Scalability
Scalability in serverless databases is not just about handling more traffic. It is also about maintaining performance and manageability as systems grow in complexity.
As applications evolve, data models often become more complex. Without proper planning, this can lead to performance degradation.
A scalable design considers not only current requirements but also future growth. This includes anticipating new features, increasing user loads, and expanding data relationships.
Serverless databases provide the infrastructure for scalability, but architecture design determines whether that scalability is effectively realized.
The Strategic Role of Databases in Serverless Ecosystems
In modern serverless architecture, databases are no longer passive storage systems. They are active components that influence application behavior, performance, and cost.
Every decision—from choosing between relational and document models to designing caching strategies—affects how the entire system behaves under load.
Understanding this strategic role is essential for building applications that are not only functional but also efficient, scalable, and sustainable in the long term.
Conclusion
Choosing a database for a serverless application is ultimately less about finding a single “perfect” solution and more about understanding how different systems behave under modern, distributed workloads. Serverless computing changes the way applications operate by removing the need to manage servers directly, but it does not remove the need for thoughtful architecture. In fact, it makes architectural decisions—especially around data storage—even more important.
Across serverless environments built with services such as AWS Lambda and Amazon API Gateway within platforms like Amazon Web Services, the database becomes the foundation that supports scalability, performance, and reliability. Whether you choose relational systems like Amazon Aurora, flexible document systems like Amazon DocumentDB, or high-speed caching layers such as Redis, each option plays a distinct role in shaping application behavior.
The key takeaway is that serverless databases are designed around abstraction and automation. They remove the burden of provisioning, patching, scaling, and maintaining infrastructure, allowing developers to focus more on application logic and user experience. However, this convenience comes with a shift in responsibility. Instead of managing servers, developers must now understand workloads, access patterns, data relationships, and cost behavior.
One of the most important lessons in serverless database selection is alignment with use case rather than feature lists. Structured and transactional systems benefit from relational databases, while rapidly evolving or flexible applications often perform better with document-based models. Performance-critical components frequently rely on in-memory or key-value stores to reduce latency. Many real-world applications combine several of these systems in a single architecture, forming a polyglot persistence strategy where each database serves a specific purpose.
Another crucial consideration is scalability behavior. Serverless databases excel in handling unpredictable workloads, but they still require careful design to avoid inefficiencies such as excessive connections, poorly optimized queries, or unnecessary data duplication. Similarly, cost management becomes an ongoing concern, since usage-based pricing can scale quickly if systems are not properly tuned.
Security and reliability also remain central responsibilities. Even though cloud providers handle infrastructure protection, developers must still ensure correct access control, secure data handling, and proper monitoring across distributed components.
Ultimately, the decision is not just technical—it is architectural. A well-chosen database strategy enables serverless applications to scale effortlessly, respond quickly to demand changes, and remain maintainable as they grow in complexity. A poorly chosen one can introduce friction that undermines many of the benefits serverless computing is meant to provide.
In the end, the best serverless database is the one that fits naturally into your application’s behavior, evolves with your data needs, and supports your long-term vision without becoming a bottleneck.