Static routing represents one of the earliest and most fundamental mechanisms used in computer networking to control how data travels between different networks. At its heart, it is based on a very simple idea: instead of allowing routers to automatically discover and update paths, a human administrator defines exact instructions for where traffic should go. These instructions remain fixed until someone manually changes them.
To understand static routing properly, it is important to first understand what routing itself means in a network. When a device such as a computer sends data to another device on a different network, the data is broken into packets. These packets must pass through one or more routers before reaching their destination. Each router acts like a decision point, determining where the packet should go next based on information stored in its routing table.
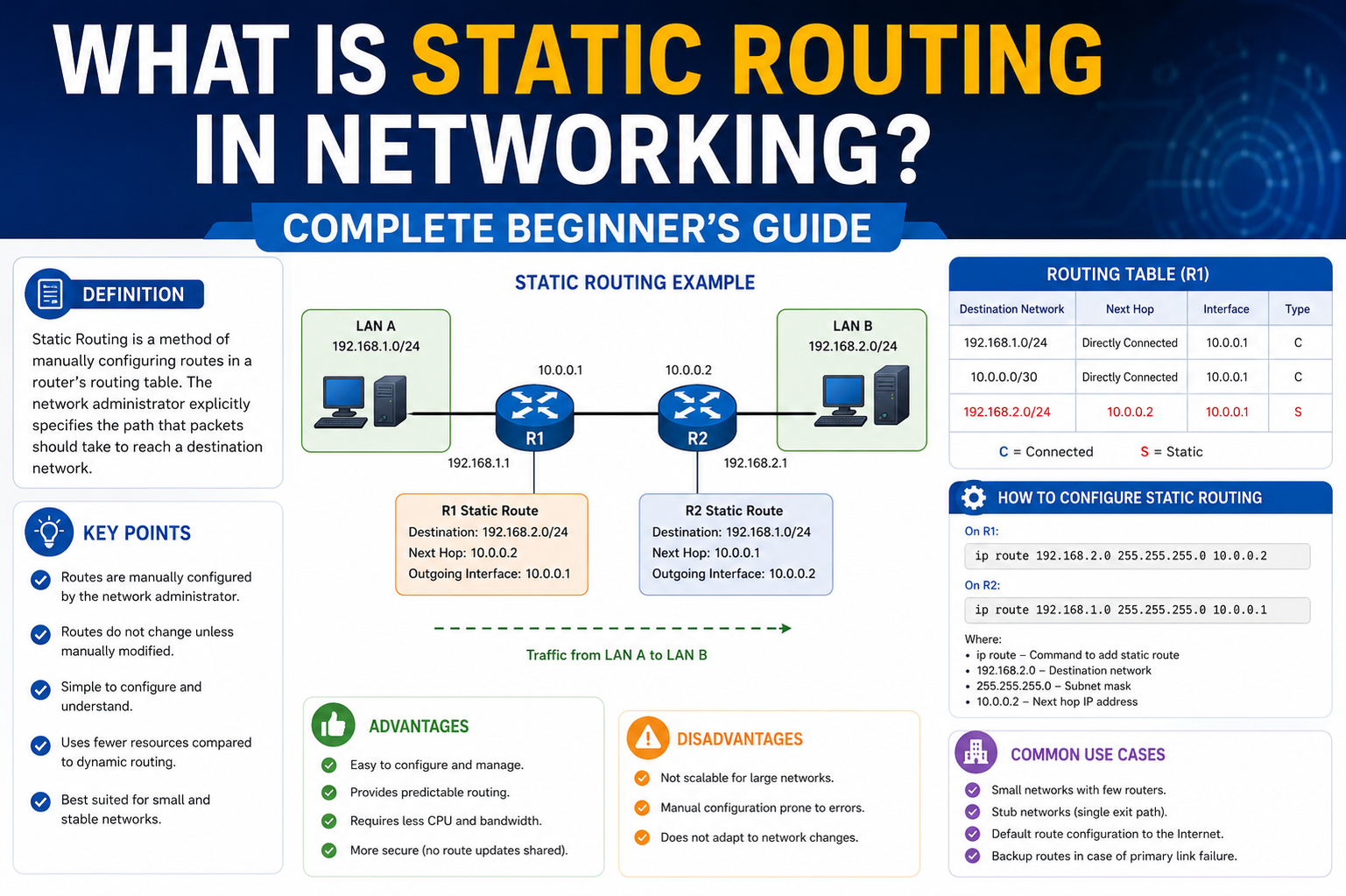
A routing table is essentially a structured list of known destinations and the best paths to reach them. In static routing, these entries are manually inserted. Unlike dynamic systems, where routers exchange information and automatically build these tables, static routing depends entirely on preconfigured knowledge.
This manual nature is what defines the essence of static routing. Once a route is added, it does not change unless a network administrator modifies or deletes it. There is no intelligence in the system to detect better paths or respond to network failures automatically. Instead, the system behaves exactly as instructed, without deviation.
One of the most important concepts in static routing is determinism. Every packet follows a predefined path, which makes network behavior predictable. Predictability is extremely valuable in certain environments where stability is more important than adaptability. For example, in tightly controlled internal networks, administrators may prefer to know exactly how traffic flows at all times.
However, this predictability comes at the cost of flexibility. Networks are not static environments in reality. Links may fail, new devices may be added, and traffic demands may change. Static routing does not adapt to any of these changes on its own. If a link goes down, the router continues attempting to send traffic through that path until someone intervenes.
Another important aspect of static routing is how it interacts with the routing table hierarchy. Routers often have multiple sources of routing information, including directly connected networks, dynamically learned routes, and static entries. When multiple routes exist for the same destination, routers must decide which one to use.
This decision is influenced by two major factors: prefix specificity and administrative distance. Prefix specificity refers to how detailed a route is. A more specific route (for example, one that matches a smaller subnet) is preferred over a broader one. Administrative distance, on the other hand, is a trust value assigned to route sources. Static routes are generally considered highly trustworthy and therefore have a very low administrative distance.
Because of this combination, static routes often override dynamically learned routes when both exist for the same destination. This makes them powerful tools for enforcing specific traffic behavior inside a network.
Static routing also plays an important role in defining how unknown traffic is handled. In many networks, not all destinations are explicitly defined. To handle such cases, administrators configure what is known as a default route. This route acts as a catch-all path for any traffic that does not match a more specific entry.
In practice, this means that if a router does not know where to send a packet, it forwards it to a predefined next hop. This is especially common at the edge of a network, where traffic is sent toward an internet gateway or upstream provider.
Another fundamental concept is that static routing is not inherently tied to manual typing or command-line configuration. While manual configuration is the most common method, static routes can also be deployed using automated systems. Network administrators often use configuration tools or scripts to apply static routes consistently across multiple devices. This reduces human error while maintaining the fixed behavior of static routing.
At a conceptual level, static routing can be seen as a rule-based system rather than a learning system. It does not observe network conditions, does not exchange information with neighbors, and does not calculate optimal paths. Instead, it follows a fixed set of instructions that remain unchanged unless externally modified.
This simplicity is one of its most important strengths. In environments where the network topology is stable, static routing provides a clean and efficient way to direct traffic without the overhead of routing protocols. However, the same simplicity becomes a limitation when networks grow in size or complexity.
As the number of routes increases, managing them manually becomes increasingly difficult. Each new network segment requires careful configuration, and every change must be reflected across all relevant devices. This creates a dependency on precise documentation and careful operational discipline.
Despite these challenges, static routing remains a foundational concept in networking because it introduces the core idea of explicit path definition. Even advanced routing systems build upon this basic principle, combining static behavior with dynamic learning to achieve more flexible designs.
Internal Operations, Packet Forwarding Logic, and Configuration Behavior
When examining static routing from an operational perspective, it becomes clear that its behavior is tightly integrated into the packet forwarding process of a router. Every time a packet arrives, the router performs a series of structured checks to determine how it should be handled.
The first step in this process is examining the destination IP address of the incoming packet. The router then compares this address against entries in its routing table. Each entry represents a known path to a network or host. In static routing, these entries have been manually defined and remain unchanged unless updated by an administrator.
If a matching route is found, the router forwards the packet to the next-hop address associated with that route. The next hop is typically another router or gateway that is responsible for continuing the forwarding process until the packet reaches its final destination.
In many cases, multiple routes may match a given destination. When this happens, routers apply the longest prefix match rule. This means that the most specific route is selected over more general ones. For example, a route to a /24 subnet will be preferred over a route to a broader /16 network if both match the destination.
Once prefix matching is applied, administrative distance is used as a secondary decision factor. This value represents how much trust the router places in the source of the route. Static routes typically have a very low administrative distance, making them highly preferred compared to many dynamic routing protocols.
A key operational feature of static routing is that it does not generate control traffic. Unlike dynamic protocols that continuously exchange updates between routers, static routing remains silent. There are no advertisements, no neighbor relationships, and no periodic updates. This reduces bandwidth usage and processing overhead.
However, this silence also means that routers are unaware of changes elsewhere in the network. If a link fails, static routes do not disappear or adjust automatically. The router continues to attempt forwarding based on the existing configuration, even if the path is no longer valid.
This behavior makes reachability of the next-hop address critically important. A static route is only effective if the next hop is accessible. If the next-hop device becomes unreachable, the route becomes non-functional even though it still exists in the routing table.
To address failure scenarios, network administrators sometimes configure backup routes known as floating static routes. These routes are assigned a higher administrative distance so that they remain inactive under normal conditions. If the primary route fails, the floating route becomes active and takes over traffic forwarding responsibilities.
From a configuration perspective, static routing is typically implemented by specifying three main elements: the destination network, the subnet mask, and the next-hop address. These elements define the exact path that traffic should follow.
When configured through a command-line interface, the administrator directly enters these values into the router. Once submitted, the router immediately installs the route into its routing table. If the next-hop address is valid and reachable, the route becomes active instantly.
Graphical configuration systems simplify this process by presenting fields for each required parameter. Although the interface is different, the underlying result is identical. A static entry is created and stored in the routing table.
One important operational consideration is consistency across devices. In multi-router environments, static routes must be carefully coordinated. If one router is configured incorrectly, traffic may be misdirected or dropped entirely. This makes accuracy essential.
Another operational aspect is interaction with directly connected networks. Routers automatically know about networks that are physically connected to them. Static routes often extend beyond these directly connected networks, allowing routers to reach remote destinations that are not directly attached.
Static routing also allows for traffic control at a very granular level. Administrators can define specific paths for specific networks, effectively shaping how data flows through the infrastructure. This can be used for performance optimization or policy enforcement.
However, as the number of static routes increases, operational complexity grows. Each additional route introduces another dependency that must be tracked and maintained. Over time, this can lead to configuration drift if documentation is not carefully maintained.
In troubleshooting scenarios, static routing issues are typically identified by checking three key areas: whether the route exists in the routing table, whether the next hop is reachable, and whether there are conflicting routes with higher priority. These checks usually reveal the source of connectivity problems.
Static routing operates on a simple but strict logic model. It does not interpret network conditions or make decisions based on performance metrics. Instead, it follows predefined instructions exactly as configured. This predictability is both its strength and its limitation.
Architectural Role, Deployment Strategies, and Network Design Implications
In practical network architecture, static routing is rarely used as the sole routing method across an entire system. Instead, it is typically applied selectively in specific areas where its characteristics provide clear advantages. Understanding its role in network design requires examining how different environments balance control, scalability, and automation.
In small-scale networks, static routing is often the preferred choice due to its simplicity. These environments usually have limited numbers of routers and stable connectivity patterns. Because the network topology does not change frequently, static routes remain valid for long periods without modification. This reduces operational overhead and simplifies troubleshooting.
In such environments, static routing provides a clear and direct mapping of traffic flow. Administrators can easily understand how packets move through the network because every path is explicitly defined. This transparency is particularly useful in environments where simplicity is more important than adaptability.
As network size increases, design considerations begin to shift. Larger networks introduce redundancy, multiple paths, and more frequent changes. In these cases, static routing alone becomes difficult to maintain. Each change requires manual updates, and the risk of inconsistencies increases.
To address this, many network designs adopt a hybrid approach. Static routing is used at the edges of the network, while dynamic routing protocols manage the core. This allows for stable control points while still benefiting from automatic adaptation in more complex areas.
One of the key architectural roles of static routing is in edge connectivity. Networks often rely on static routes to define how traffic exits toward external systems or internet gateways. These routes provide a clear and controlled exit path for outbound traffic.
Static routing is also commonly used in stub networks. A stub network is a network with only one connection to other networks. Since there is only one possible route for external traffic, dynamic routing offers no additional benefit. A single static default route is sufficient to handle all outbound communication.
Another important architectural consideration is redundancy. While static routing does not inherently support automatic failover, designers can implement backup paths using floating static routes. These routes remain inactive under normal conditions but become active when primary paths fail. This provides a limited form of redundancy without requiring full dynamic routing.
Security is another area where static routing influences design decisions. Because static routes are not advertised across the network, they reduce the exposure of internal routing information. This limits the visibility of network topology to potential attackers and reduces certain attack surfaces associated with routing protocol manipulation.
Static routing also plays a role in traffic engineering. By explicitly defining paths, administrators can control how traffic flows through the network. This can be used to avoid congestion, enforce policy-based routing, or direct specific types of traffic through preferred links.
However, this level of control requires careful planning. Misconfigured static routes can lead to traffic black holes, routing loops, or inefficient paths. As a result, documentation and design consistency become essential components of any static routing strategy.
Scalability remains the most significant limitation in large environments. As the number of routes increases, manual management becomes increasingly difficult. This is why static routing is typically avoided as the primary routing mechanism in large-scale infrastructures.
Despite this, static routing continues to serve as an important foundational tool. It provides deterministic behavior, minimal overhead, and precise control over traffic flow. These qualities make it valuable in specific scenarios even in highly advanced network architectures.
Across all design contexts, static routing represents a fundamental trade-off between simplicity and adaptability. It prioritizes explicit control over automatic intelligence, making it a stable but rigid component of network design strategies.
Advanced Static Routing Strategies, Enterprise Integration, and Modern Network Environments
As networks evolve into more complex, distributed, and hybrid environments, static routing does not disappear—it changes its role. Instead of being a standalone routing method, it becomes part of a larger architectural toolkit that includes automation, dynamic protocols, cloud networking models, and policy-driven traffic control. Understanding static routing in modern contexts requires looking beyond basic configuration and into how it interacts with advanced infrastructure designs.
One of the most important developments in modern networking is the integration of static routing with dynamic routing systems. In many enterprise environments, static and dynamic routing are not competing technologies but complementary ones. Static routes are often used to define fixed boundaries or special-purpose paths, while dynamic routing handles large-scale adaptability and real-time decision-making.
This hybrid approach is especially useful in environments where certain paths must remain fixed regardless of network conditions. For example, traffic destined for a secure management network might always be forced through a specific gateway, even if alternative paths exist. Static routing ensures this deterministic behavior, while dynamic routing manages the rest of the network efficiently.
In such hybrid designs, route interaction becomes a critical concept. When both static and dynamic routes exist for the same destination, routers must decide which route to prefer. This decision is influenced by administrative distance, prefix specificity, and routing policies. Static routes, because of their typically low administrative distance, often override dynamically learned routes unless explicitly configured otherwise.
However, enterprise environments sometimes intentionally adjust administrative distance values to change this behavior. By increasing or decreasing preference values, administrators can influence traffic flow without removing routes entirely. This allows static routing to function as a flexible policy tool rather than just a fixed path definition mechanism.
Another advanced use case involves route redistribution environments. In networks where multiple routing domains exist, static routes are sometimes injected into dynamic routing protocols. This allows static definitions to be shared across larger network segments without manually configuring every device. While this introduces more complexity, it enables centralized control of certain routing behaviors.
In modern data centers, static routing is often used in very targeted ways. Even though large-scale environments rely heavily on dynamic protocols or overlay networks, static routes still play a role in defining edge behavior, service access paths, and fallback connectivity. In particular, static routes are commonly used to define default gateways for isolated segments or specialized service networks.
Cloud networking introduces another dimension to static routing usage. In cloud-based environments, virtual networks often require explicit routing definitions to connect subnets, availability zones, or hybrid connections between on-premises infrastructure and cloud services. Static routing becomes a foundational tool for defining these controlled communication paths.
In hybrid cloud architectures, static routes are often used to establish predictable connectivity between internal corporate networks and cloud gateways. These routes ensure that traffic destined for cloud-hosted services follows a specific path, often through secure tunnels or dedicated connections. This predictable behavior is essential for maintaining security and compliance requirements.
Another important aspect of modern static routing is automation. While static routing is traditionally associated with manual configuration, modern network operations rarely rely on manual processes alone. Instead, automation tools and configuration management systems are used to deploy static routes consistently across large infrastructures.
This automation reduces human error, which is one of the primary weaknesses of static routing. In large environments, even a small misconfiguration can lead to traffic loss or routing inconsistencies. By using automated deployment systems, administrators ensure that static routes are applied uniformly and can be updated at scale when necessary.
Automation also enables dynamic generation of static routes based on predefined templates or policies. For example, when a new network segment is created, automation tools can automatically insert the required static routes into relevant devices. This allows static routing to scale more effectively than traditional manual methods.
Despite these improvements, the fundamental limitation of static routing remains: it does not adapt to real-time network conditions. This is where monitoring and operational intelligence become essential. Modern networks often pair static routing with advanced monitoring systems that detect failures and trigger automated responses.
For example, if a primary link fails, monitoring systems may initiate scripts that adjust static route configurations or activate backup routes. While this does not make static routing inherently dynamic, it introduces a layer of external responsiveness that compensates for its limitations.
Security considerations also become more advanced in modern deployments. Static routing inherently reduces exposure to routing protocol attacks because it does not rely on route advertisements. However, it does not eliminate all security risks. Misconfigured static routes can still create unintended access paths or bypass security controls.
In secure network designs, static routing is often used to enforce strict traffic segmentation. By explicitly defining allowed paths, administrators can ensure that sensitive networks remain isolated from general traffic flows. This is particularly important in environments handling regulated data or critical infrastructure.
Another advanced security use case involves traffic blackholing. Static routes can be configured to direct unwanted or malicious traffic to null destinations, effectively discarding it before it reaches sensitive systems. This technique is used as part of broader defense strategies to mitigate denial-of-service conditions or isolate suspicious traffic patterns.
From a performance perspective, static routing continues to offer benefits in specialized scenarios. Because it does not require computational overhead for route calculation or protocol processing, it can reduce CPU load on routing devices. While this advantage is less significant in modern high-performance hardware, it can still be relevant in constrained environments or edge devices.
Edge computing environments provide another interesting context for static routing. In distributed systems where compute resources are deployed closer to data sources, network simplicity becomes important. Static routing is often used to maintain predictable communication paths between edge nodes and central systems.
In these environments, stability is often more important than adaptability. Edge nodes may operate in environments with limited connectivity or intermittent links. Static routing provides a predictable framework for maintaining connectivity without requiring constant routing recalculations.
Another advanced consideration is troubleshooting complexity in mixed environments. When static and dynamic routing coexist, identifying the source of traffic issues requires a deep understanding of route selection logic. Problems may arise from unexpected administrative distance interactions, incorrect next-hop configurations, or missing return paths.
In such environments, troubleshooting often involves analyzing routing tables in detail and tracing packet flows step by step. Unlike dynamic routing issues, which may involve protocol states or neighbor relationships, static routing issues are usually configuration-based. This makes them simpler in concept but potentially more time-consuming to identify in large networks.
Policy-based routing also intersects with static routing in advanced designs. While policy-based routing allows traffic to be directed based on conditions such as source address or application type, static routes define the underlying paths that this traffic follows. Together, they create layered routing logic where policies determine decisions and static routes define execution paths.
Another emerging area where static routing remains relevant is in virtualized network environments. Virtual routers and software-defined networking platforms often still rely on static route definitions for specific control functions. Even in highly abstracted environments, the need for fixed routing behavior does not disappear.
In service provider environments, static routing is frequently used at network edges to manage customer connections or define upstream routing behavior. While core networks rely heavily on dynamic protocols, static routes provide stability at boundary points where predictability is essential.
Over time, the role of static routing has shifted from being a primary routing mechanism to a specialized tool within a broader ecosystem. It is no longer the backbone of large-scale routing design, but it remains essential for specific functions that require explicit control.
What makes static routing enduring is its simplicity. Despite advances in automation, cloud computing, and dynamic routing systems, there are still situations where a fixed, unchanging path is the most appropriate solution. Whether for security, stability, or design clarity, static routing continues to provide value in modern network architectures.
Even as networks become more intelligent and self-adjusting, the concept of explicitly defined paths remains foundational. Static routing represents the most direct expression of this concept, serving as a reminder that not all network behavior needs to be learned or computed dynamically.
Troubleshooting Deep Dive, IPv6 Static Routing, Failure Scenarios, and Real-World Design Patterns
As static routing continues to exist alongside modern automated networking systems, its behavior in real operational environments becomes increasingly important to understand at a deeper level. While earlier discussions focus on fundamentals, configuration, and architectural role, real-world usage introduces complexities that only appear under failure conditions, mixed routing environments, and large-scale deployments. Static routing may look simple on the surface, but its behavior in production networks often reveals subtle interactions that can significantly impact connectivity.
One of the most critical aspects of working with static routing in operational environments is troubleshooting. Unlike dynamic routing, where issues may involve protocol states, neighbor relationships, or route convergence delays, static routing problems are almost always tied to configuration accuracy and reachability. This makes the troubleshooting process conceptually simple but practically demanding, especially in large networks where many static routes exist.
A common failure scenario occurs when the next-hop address becomes unreachable. Since static routes do not actively monitor network health, they continue to exist in the routing table even if the next-hop device is offline. This creates a situation where the route appears valid on paper but fails in practice. Packets are forwarded to a destination that can no longer respond, resulting in silent traffic loss.
In such cases, administrators often begin troubleshooting by verifying layer-by-layer connectivity. First, they confirm whether the static route exists in the routing table. Next, they check whether the next-hop address can be reached using basic connectivity tests. Finally, they analyze whether return traffic is properly routed back to the source. In static routing environments, return path issues are particularly common because routes must be explicitly defined in both directions.
Another frequent issue arises from misconfigured subnet masks. Because static routes rely on precise network definitions, even a small mismatch in subnet information can result in traffic being forwarded incorrectly or not at all. This type of issue is often difficult to detect immediately because the route may still appear valid in the routing table, even though it does not match actual network topology.
Administrative distance conflicts also play a role in troubleshooting complexity. In environments where static and dynamic routes coexist, unexpected route selection can occur if administrative distance values are not carefully understood. A dynamically learned route might unintentionally override a static route if its preference value is lower than expected. This can lead to confusion, especially when multiple routing sources advertise overlapping networks.
To resolve such issues, network engineers often inspect the routing table in detail, examining not just the presence of routes but also their origin, metric values, and selection priority. Understanding why a specific route was chosen becomes just as important as identifying whether it exists.
Beyond IPv4, static routing in IPv6 environments introduces additional considerations. IPv6 static routing follows the same conceptual model as IPv4 but operates with longer address formats and different subnetting structures. Instead of dotted decimal notation, IPv6 uses hexadecimal representation, which can make manual configuration more error-prone.
In IPv6 networks, static routes are often used for default routing and inter-subnet communication in controlled environments. The logic remains the same: a destination prefix is mapped to a next-hop address. However, because IPv6 networks are often designed with hierarchical addressing schemes, static routing must be carefully aligned with address allocation strategies.
A key difference in IPv6 static routing is the increased importance of link-local addresses in next-hop configuration. Instead of relying solely on global addresses, routers often use link-local identifiers to determine immediate forwarding paths. This adds another layer of complexity when diagnosing routing issues, as link-layer reachability becomes essential for proper operation.
Another important area in static routing analysis involves failure propagation. In dynamic routing environments, failures are automatically detected and propagated through the network. In static routing, however, failure impact is localized and persistent until manually corrected. This can lead to partial outages where some parts of the network remain functional while others become unreachable.
These partial failures are particularly challenging because they do not always present as complete outages. Instead, traffic may flow correctly in one direction but fail in the reverse direction. This asymmetry often points to missing or incorrect static routes on one side of the communication path.
In larger environments, static routing is often combined with monitoring systems that detect reachability issues and alert administrators. However, monitoring alone does not resolve the issue; it only highlights the existence of a problem. Resolution still requires manual or automated intervention to correct routing definitions.
From a design perspective, static routing failure scenarios highlight the importance of redundancy planning. One common pattern is the use of dual static routes, where a primary path and a backup path are configured simultaneously. The backup path is typically assigned a higher administrative distance so that it remains inactive unless the primary path fails.
This design pattern provides a basic form of resilience without introducing full dynamic routing complexity. However, it requires careful planning to ensure that both routes are properly configured and tested. If the backup route is incorrect, failover scenarios may result in complete connectivity loss rather than recovery.
Another design pattern involves segmented static routing, where different static routes are used for different types of traffic. For example, management traffic may be routed through a separate path than user data traffic. This allows for greater control over network behavior but increases configuration complexity.
Static routing also plays a role in controlled traffic isolation. In some environments, administrators intentionally design routing tables so that certain networks cannot communicate directly. This is achieved by simply not defining routes between those networks. While simple in concept, this method is highly effective for enforcing strict segmentation.
A common misconception about static routing is that it is inherently more secure than dynamic routing. While it is true that static routing reduces exposure to routing protocol attacks, it does not eliminate security risks entirely. Incorrect static routes can still expose sensitive networks or bypass intended security controls. Security in static routing depends entirely on correct configuration and ongoing validation.
Another misconception is that static routing is outdated or no longer relevant. In reality, it continues to be widely used in modern networks, especially at edges, in small environments, and in specialized control scenarios. Its role has shifted rather than disappeared. It is no longer the primary mechanism for large-scale routing, but it remains an essential tool in network design.
Automation has significantly changed how static routing is managed. In modern infrastructures, static routes are often generated and deployed through automated systems rather than manual entry. This allows organizations to maintain the benefits of static routing while reducing the risk of human error.
Automated systems can also validate static route consistency across devices, ensuring that routing definitions match intended design policies. This reduces the likelihood of misconfigurations that could lead to outages. In some cases, automation systems can even detect unreachable routes and adjust configurations accordingly, although this introduces a semi-dynamic behavior on top of static foundations.
In software-defined networking environments, static routing still exists but is often abstracted behind higher-level policy definitions. These systems translate policy decisions into actual static or dynamic routing entries behind the scenes. Even in highly automated environments, the concept of fixed path definition remains relevant.
Another advanced consideration is scaling static routing in distributed environments. As networks span multiple geographic locations, maintaining consistent static routing becomes increasingly difficult. Each location may have unique connectivity requirements, making centralized configuration essential. Without centralized management, static routing can quickly become inconsistent and difficult to maintain.
One of the more subtle challenges in large static routing deployments is route documentation drift. Over time, network changes may occur without corresponding updates to documentation. This leads to discrepancies between actual routing behavior and expected design. In complex environments, this can significantly complicate troubleshooting efforts.
Static routing also interacts closely with network address planning. Poorly structured IP addressing schemes can make static routing more difficult to implement and maintain. Conversely, well-designed hierarchical addressing simplifies static route definition and reduces configuration overhead.
In modern hybrid environments, static routing continues to serve as a stable anchor point. Even as networks become increasingly dynamic, there is still a need for fixed, predictable routing behavior in certain parts of the infrastructure. Static routing provides that stability, ensuring that critical paths remain consistent regardless of broader network changes.
Ultimately, the deeper understanding of static routing lies not in its simplicity, but in how that simplicity behaves under real-world conditions. It is a system defined by precision, predictability, and manual control, yet it interacts with complex environments in ways that require careful planning and continuous attention.
Static Routing in Modern Hybrid Networks, Automation Evolution, and Future Relevance
Static routing today exists in a very different networking landscape compared to its early usage. Modern infrastructures are no longer simple collections of routers connected in fixed topologies. Instead, they are distributed systems that span data centers, cloud platforms, branch networks, and virtualized environments. In this context, static routing has evolved from a standalone configuration method into a precise tool used within larger, highly automated systems.
One of the most important developments affecting static routing is the rise of hybrid network architectures. These architectures combine static routing with dynamic routing protocols and policy-driven networking. Rather than choosing one approach over another, modern designs integrate multiple routing strategies, each serving a specific purpose.
In hybrid environments, static routing is often used to define structural boundaries within the network. For example, it may be used to establish fixed exit points for branch networks, while dynamic routing handles internal traffic distribution. This separation of responsibilities allows static routing to provide stability at the edges while dynamic systems handle variability in the core.
Another key role of static routing in modern networks is in controlled traffic enforcement. Even in highly dynamic environments, certain traffic flows must remain predictable. Security-sensitive systems, management networks, and infrastructure services often rely on static routes to ensure that communication paths remain unchanged regardless of network conditions. This guarantees that critical services always follow approved paths.
As networks have become more complex, automation has become essential to managing static routing at scale. Manual configuration alone is no longer practical in environments with hundreds or thousands of devices. Instead, static routes are now frequently deployed through automated configuration systems that generate and distribute routing entries based on predefined templates and policies.
This automation introduces a new dimension to static routing. While the underlying behavior remains static, the deployment process becomes dynamic. Routes can be created, updated, or removed automatically in response to changes in network design. This reduces human error and ensures consistency across large infrastructures.
However, even with automation, static routing retains its fundamental characteristic: once a route is installed on a device, its behavior is fixed until explicitly changed. This distinction is important because it preserves the predictability of static routing while improving its manageability.
In large-scale environments, static routing is often integrated into infrastructure-as-code practices. In these systems, network configurations are defined in structured templates and version-controlled repositories. Static routes become part of a broader configuration model that can be reviewed, tested, and deployed systematically. This approach brings software engineering principles into network management.
Another important evolution is the interaction between static routing and virtualized networks. In virtual environments, networks are no longer tied to physical hardware. Instead, virtual routers and software-defined constructs handle traffic flow. Static routing in these environments is often used to define internal service communication paths or to connect virtual networks to external systems.
In such setups, static routing may not always be directly visible at the hardware level. Instead, it is abstracted within virtual routing instances. This abstraction allows static routing to be applied consistently across physical, virtual, and cloud-based environments without requiring fundamental changes to its logic.
Cloud networking has also expanded the use of static routing in new directions. In cloud-based systems, networks are often segmented into virtual private environments that require explicit routing definitions to communicate with each other or with on-premises infrastructure. Static routing plays a critical role in establishing these connections.
For example, when connecting an internal corporate network to a cloud environment, static routes may be used to define which traffic is allowed to pass through secure gateways or tunnels. These routes ensure that only intended traffic follows specific paths, maintaining both security and predictability.
At the same time, cloud environments often rely on dynamic scaling and elastic network behavior. This creates an interesting contrast: while the infrastructure changes dynamically, certain routing paths remain static to maintain control and stability. This balance between flexibility and structure is a defining feature of modern network design.
Conclusion
Static routing remains one of the most fundamental building blocks in computer networking, even as modern systems increasingly rely on automation and dynamic decision-making. At its core, it represents a simple but powerful idea: network paths are explicitly defined rather than discovered automatically. This fixed nature gives static routing a level of predictability that is difficult to achieve with more complex routing protocols.
Throughout its use in different environments, static routing consistently demonstrates its strengths in stability, control, and simplicity. It allows administrators to precisely define how traffic should move through a network, ensuring that data follows intended paths without deviation. This makes it especially valuable in environments where network behavior must remain consistent, such as small networks, edge systems, and security-sensitive infrastructures.
At the same time, static routing clearly shows its limitations when applied to large or rapidly changing networks. Because it does not adapt to topology changes, any modification in the network requires manual intervention. This can introduce operational overhead and increase the risk of configuration errors if not carefully managed. For this reason, static routing is rarely used alone in modern enterprise environments.
Instead, its true value today lies in how it integrates with other networking approaches. In hybrid designs, static routing works alongside dynamic routing protocols, automation tools, and policy-based systems. It provides fixed reference points within a constantly changing environment, ensuring that critical traffic flows remain stable even when other parts of the network adapt dynamically.
Modern advancements such as cloud computing, virtualization, and network automation have not replaced static routing but have reshaped how it is used. It is now often deployed through automated systems, embedded within larger orchestration frameworks, and applied selectively where deterministic behavior is required.
Ultimately, static routing continues to serve as a reminder that not all network intelligence needs to be dynamic. In many cases, simplicity and direct control are more valuable than adaptability. Its enduring presence in modern networking highlights its importance as both a practical tool and a foundational concept that supports more advanced networking technologies.