Strings in JavaScript represent one of the most fundamental building blocks of working with text-based data. At their core, strings are simply sequences of characters arranged in a specific order. These characters may include letters, numbers, symbols, punctuation marks, and even spaces. What makes strings especially important in programming is that they allow developers to store, display, and manipulate textual information in a structured way that computers can process.
Unlike spoken language, where meaning can shift depending on tone or context, strings in JavaScript are strictly defined sequences. The language does not infer meaning beyond what is explicitly written. This strict structure is what allows programs to function predictably, but it also introduces limitations when dealing with human-like language interpretation.
In everyday usage, strings often represent names, messages, user input, configuration values, or data retrieved from external sources. Because of this wide usage, string handling becomes a central part of nearly every JavaScript application. Whether building a simple website or a complex web application, understanding how strings behave is essential for ensuring accurate data processing.
One important characteristic of strings is that they are treated as primitive values, yet they behave in some ways like structured collections of characters. This dual nature allows developers to access individual characters, determine length, and perform various transformations. However, even though strings may appear flexible, their underlying behavior remains consistent and rigid.
This rigidity becomes especially noticeable when comparing strings. While humans can easily recognize that two phrases may convey the same meaning despite slight differences, JavaScript does not operate on meaning. Instead, it compares exact character sequences. This distinction forms the foundation for many challenges developers face when working with text comparison.
Why String Comparison is Not as Simple as It Seems
At first glance, comparing two strings appears to be a straightforward task. One might assume that if two pieces of text look similar, they should be considered equal. However, in JavaScript, string comparison is based on strict evaluation of characters rather than interpretation of meaning. This creates a gap between human understanding and machine logic.
Human communication is inherently flexible. People often ignore minor differences in punctuation, capitalization, or spacing when interpreting meaning. For example, a sentence with or without a comma may still be understood in the same way by a reader. However, JavaScript treats these variations as entirely distinct sequences.
This strictness is necessary for computational accuracy. Computers require precise instructions to function correctly, and ambiguity can lead to unpredictable results. As a result, string comparison is designed to ensure that every character matches exactly in order and form.
This behavior can become confusing when developers expect logical equivalence based on meaning rather than structure. Two strings that appear identical to the human eye may still be considered different if even a single character varies. This includes subtle differences such as extra spaces, capitalization changes, or hidden characters that are not immediately visible.
The complexity increases further when strings originate from different sources. User input, database records, and external APIs often introduce inconsistencies in formatting. These inconsistencies make direct comparison unreliable unless carefully controlled.
Understanding why string comparison behaves this way helps set realistic expectations when working with JavaScript. It highlights the importance of recognizing that computers prioritize structure over semantics, which is a key principle in all programming languages.
How JavaScript Interprets Text Data Internally
To understand string comparison more deeply, it is important to explore how JavaScript internally processes text data. Strings are stored as sequences of encoded characters, where each character is represented by a numeric value based on standardized encoding systems.
These numeric representations allow the computer to store and compare text efficiently. Instead of interpreting words or meanings, JavaScript compares numerical values associated with each character. This means that even a slight difference in encoding or character representation can result in two strings being considered unequal.
Because strings are stored in this structured format, JavaScript can quickly evaluate equality by checking each position in the sequence. If every character matches exactly in both order and value, the strings are considered identical. If even one position differs, the comparison fails.
This system is highly efficient for computational purposes, but does not account for linguistic nuances. For example, uppercase and lowercase letters often have different underlying numeric representations. This means that visually similar characters may be treated as distinct entities internally.
Additionally, JavaScript does not automatically normalize text. This means that different ways of representing the same character—such as accented letters or special symbols—may not match unless explicitly standardized. These internal mechanics play a significant role in why string comparison can produce unexpected results.
Understanding this internal structure helps clarify why strict equality is enforced. It also explains why developers often need to preprocess strings before comparison to ensure consistency across different data sources.
The Role of Character Encoding and Case Sensitivity
Character encoding plays a crucial role in how JavaScript handles strings. Each character is assigned a unique numeric value according to encoding standards such as Unicode. These values determine how characters are stored and compared at a machine level.
One of the most noticeable effects of this system is case sensitivity. Uppercase and lowercase letters are treated as completely different characters because they have distinct numeric representations. As a result, two strings that differ only in capitalization are considered unequal in JavaScript.
This behavior is intentional and allows for precise control over text data. However, it also introduces challenges when working with user-generated content, where capitalization is often inconsistent. For example, names, titles, or messages may be entered in different formats depending on user preference or input method.
Encoding also affects how special characters are interpreted. Symbols, accented letters, and non-English characters may have multiple valid representations. Without standardization, these differences can lead to mismatches during comparison.
Another important aspect is normalization. Some characters can be represented in multiple ways within Unicode, even if they appear identical. JavaScript does not automatically resolve these differences, which means that visually identical strings may not match internally.
Because of these factors, character encoding and case sensitivity must be carefully considered when comparing strings. They form the technical foundation that determines how text is evaluated and why small differences can have significant consequences in comparison outcomes.
Human Language vs Machine Interpretation of Text
One of the most significant challenges in string comparison arises from the difference between human language understanding and machine interpretation. Humans naturally interpret language based on context, tone, and intent. Computers, on the other hand, process text as structured data without any understanding of meaning.
This fundamental difference creates a gap in expectations. A human reader can easily understand that two sentences with slight variations may still convey the same idea. However, JavaScript evaluates strings purely based on character-by-character matching.
Human language is inherently flexible and adaptive. It allows for variations in grammar, punctuation, and structure while still preserving meaning. This flexibility is essential for communication but difficult to replicate in computational systems.
Machines cannot infer intent unless explicitly programmed to do so. As a result, they rely on strict rules to ensure consistency. This means that even minor differences that humans might overlook become significant in string comparison.
This limitation is particularly evident in natural language processing scenarios, where systems must attempt to bridge the gap between rigid data structures and fluid human expression. Without additional processing layers, JavaScript remains strictly literal in its interpretation.
Understanding this difference is essential for recognizing why string comparison often requires preprocessing or normalization. It also highlights the importance of designing systems that account for human variability while maintaining computational accuracy.
Common Real-World Scenarios Where String Comparison Fails
String comparison issues frequently appear in real-world applications, often in situations where data originates from multiple sources. One common scenario involves user authentication systems, where small differences in input can lead to mismatches even when credentials appear correct.
Another example occurs in search functionality. Users may enter queries with varying capitalization, spacing, or punctuation, which can affect how results are matched. Without proper handling, relevant data may be overlooked due to strict comparison rules.
Data synchronization between systems is another area where string comparison challenges arise. Different platforms may store or format text differently, leading to inconsistencies when comparing records. These inconsistencies can result in duplicate entries or failed matches.
Form validation also frequently encounters string comparison issues. User input may include accidental spaces or formatting variations that prevent accurate validation. This is especially common in fields such as names, addresses, and email inputs.
Even simple applications like messaging systems can be affected. Messages that appear identical to users may contain hidden differences that affect processing logic. These subtle inconsistencies can lead to unexpected behavior if not properly managed.
These real-world scenarios highlight the importance of understanding string behavior in JavaScript. They demonstrate that comparison is not just a theoretical concept but a practical concern that affects everyday application performance and reliability.
The Impact of Punctuation, Spacing, and Formatting Differences
Punctuation, spacing, and formatting play a surprisingly large role in string comparison outcomes. While these elements may seem insignificant from a human perspective, they are treated as meaningful characters in JavaScript.
A single extra space can completely change the result of a comparison. Similarly, the presence or absence of punctuation marks such as commas or periods can cause two strings to be considered different. These small variations are often difficult to detect visually but are significant at the character level.
Formatting differences can also arise from how text is generated or stored. For example, text copied from different sources may include hidden formatting characters or inconsistent spacing patterns. These invisible differences can lead to unexpected comparison failures.
Line breaks and tab characters further complicate the situation. They are often not visible in standard display formats but are still part of the string data. As a result, they must be considered when evaluating equality.
These factors demonstrate that string comparison is sensitive not only to visible content but also to structural details that may not be immediately apparent. This sensitivity reinforces the importance of careful data handling when working with text in JavaScript.
Cultural and Linguistic Variations in String Comparison Challenges
Language diversity introduces additional complexity into string comparison. Different languages use unique character sets, accents, and writing systems, all of which must be accurately represented in digital form.
JavaScript relies on standardized encoding systems to handle this diversity, but variations in representation can still lead to inconsistencies. For example, characters with accents may be represented differently depending on input methods or system configurations.
Cultural differences in formatting also play a role. Date formats, name structures, and punctuation conventions vary widely across regions. These differences can affect how strings are interpreted and compared.
Multilingual applications must account for these variations to ensure accurate processing. Without proper handling, strings that appear equivalent in one context may be treated as different in another.
This complexity highlights the importance of understanding global text representation standards. It also emphasizes the need for careful design when building applications that operate across multiple languages and cultural contexts.
Data Entry, User Input, and Inconsistency Problems
User input is one of the most common sources of inconsistency in string comparison. Unlike controlled data environments, user-generated content is unpredictable and varies widely in format and structure.
Typing errors, accidental spacing, and inconsistent capitalization are common issues that affect string accuracy. Even small mistakes can lead to mismatches during comparison if not properly accounted for.
Different input devices and methods can also introduce variations. Mobile keyboards, voice input, and copy-paste actions may produce slightly different results, even when users intend to enter the same text.
These inconsistencies make it difficult to rely on raw string comparison in practical applications. Instead, additional processing steps are often necessary to ensure consistency across inputs.
Understanding these challenges is essential for designing robust systems that can handle real-world data effectively. It highlights the importance of anticipating variability in user behavior and accounting for it in application logic.
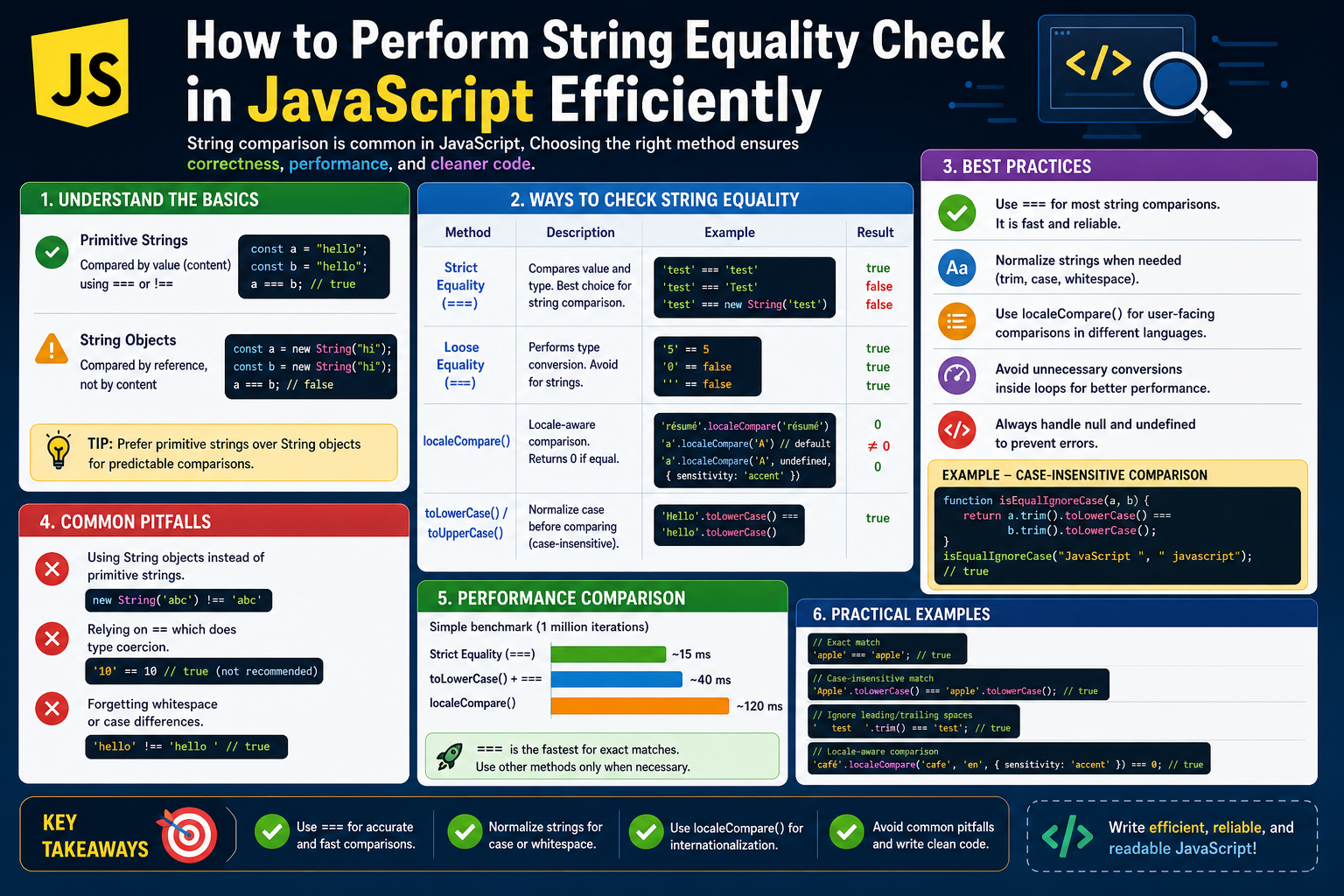
Exact Matching and the Nature of Strict Equality in JavaScript
One of the most fundamental ways JavaScript compares strings is through strict equality. This approach evaluates whether two strings are identical in every possible way, down to the smallest character detail. It does not attempt to interpret meaning, ignore formatting, or adjust for linguistic differences. Instead, it performs a direct, literal comparison of the underlying character sequences.
Strict equality is highly reliable in environments where data is controlled and consistent. If two strings originate from the same source and are expected to remain unchanged, strict comparison works efficiently and predictably. However, its strength is also its limitation. Any deviation, no matter how small, results in inequality.
This includes differences in spacing, capitalization, punctuation, or even invisible characters. From a machine perspective, every character contributes to the identity of a string. As a result, strict comparison behaves like a precise measuring tool that detects even the slightest variation.
While this method is fast and computationally inexpensive, it is not designed for human-like interpretation. It does not understand that two differently formatted phrases might still represent the same idea. This makes it essential to use strict equality only when absolute precision is required, and data consistency is guaranteed.
Lexicographic Ordering and Character-by-Character Evaluation
Beyond simple equality, JavaScript also relies on lexicographic comparison when determining the order of strings. This method evaluates strings based on the sequential value of their characters, comparing them one position at a time.
Lexicographic comparison works similarly to dictionary ordering, where words are arranged based on the sequence of letters. However, instead of linguistic rules, JavaScript uses internal character encoding values to determine order. This means that the comparison is purely numerical at its core.
When two strings are compared lexicographically, JavaScript begins at the first character of each string. If they differ, the comparison is resolved immediately. If they are identical, the process continues to the next character until a difference is found or one string ends.
This system is efficient and predictable, but it does not account for language rules or cultural conventions. For example, uppercase characters may be considered “less than” lowercase characters due to their encoding values, which can lead to unexpected ordering results.
Lexicographic comparison is commonly used in sorting operations, where lists of strings must be arranged in a consistent sequence. However, without additional processing, the results may not align with human expectations, especially in multilingual contexts.
Locale-Aware Comparison and Cultural Sensitivity in Sorting
To address limitations in basic string comparison, JavaScript provides mechanisms that consider linguistic and regional rules. Locale-aware comparison introduces the concept of cultural context into how strings are evaluated.
Unlike strict or lexicographic comparison, locale-aware methods take into account language-specific rules for sorting and equivalence. This includes handling accented characters, regional alphabet structures, and case sensitivity rules that vary across languages.
For example, certain languages treat accented characters as variations of the same base letter, while others consider them distinct. Locale-aware comparison adjusts behavior based on these rules, resulting in more culturally appropriate outcomes.
This type of comparison is especially important in applications that serve global audiences. Without it, sorting and matching operations may appear incorrect or inconsistent to users from different linguistic backgrounds.
However, even locale-aware comparison has limitations. It still operates within predefined linguistic rules and does not interpret meaning. It improves alignment with human expectations but does not achieve true semantic understanding.
As a result, it is often used as a middle ground between strict machine comparison and human-like interpretation.
The Role of Case Normalization in String Matching
Case differences are one of the most common sources of mismatches in string comparison. JavaScript treats uppercase and lowercase letters as distinct characters, which means that even visually similar strings may not match.
Case normalization is the process of converting all characters in a string to a uniform case before comparison. This ensures that differences in capitalization do not affect the outcome.
By standardizing cases, strings such as names, keywords, or user input can be compared more consistently. However, this process must be applied carefully, as some contexts require case sensitivity for accuracy or security.
Case normalization is particularly useful in search functionality, where users may enter queries in unpredictable formats. It helps ensure that results remain consistent regardless of input style.
Despite its usefulness, case normalization alone is not sufficient to guarantee accurate comparison. It must be combined with other normalization techniques to handle spacing, punctuation, and encoding differences.
Whitespace Normalization and Hidden Formatting Issues
Whitespace is often overlooked in string comparison, yet it plays a significant role in determining equality. Spaces, tabs, and line breaks are all considered valid characters in JavaScript strings.
Even when two strings appear identical, differences in whitespace can cause comparison failures. This is especially common when data is copied from external sources or entered manually by users.
Whitespace normalization involves standardizing or removing unnecessary spacing to ensure consistency. This may include trimming leading or trailing spaces or reducing multiple spaces to a single standardized format.
Hidden whitespace characters can be particularly problematic because they are not visually obvious. These characters may originate from formatting systems, text editors, or automated data processing tools.
Without normalization, these hidden differences can lead to unexpected mismatches in string comparison. This makes whitespace handling an essential part of any robust text-processing system.
Punctuation Handling and Structural Variability in Text
Punctuation introduces another layer of complexity in string comparison. Characters such as commas, periods, exclamation marks, and quotation marks can significantly alter string identity in JavaScript.
From a computational perspective, punctuation is treated as part of the string structure. This means that even minor differences in punctuation can result in completely different comparison outcomes.
In many real-world scenarios, punctuation does not affect meaning in a way that should influence equality. However, JavaScript does not interpret meaning, so punctuation must be handled explicitly when necessary.
Removing or standardizing punctuation is a common preprocessing step in text normalization pipelines. This helps ensure that the comparison focuses on core textual content rather than stylistic differences.
However, punctuation cannot always be ignored. In some contexts, it carries essential meaning that must be preserved. This makes punctuation handling a context-dependent decision rather than a universal rule.
Unicode Representation and the Complexity of Character Encoding
Modern JavaScript relies on Unicode to represent a vast range of characters from different languages and symbol systems. While this allows for global text support, it also introduces complexity in string comparison.
Unicode characters can sometimes be represented in multiple valid ways. For example, certain accented characters may exist as a single combined character or as a base character followed by a combining accent mark.
Although these representations may appear identical, they are not always treated as equal in raw comparison. This discrepancy arises because JavaScript compares underlying code units rather than visual appearance.
This issue highlights the importance of understanding how characters are encoded rather than how they are displayed. Without normalization, visually identical strings may fail to match due to differences in encoding structure.
Unicode complexity is one of the primary reasons why string comparison can behave unpredictably in multilingual environments. It requires careful handling to ensure consistency across different input sources.
Normalization Forms and Standardizing Text Representation
To address inconsistencies in Unicode representation, text normalization techniques are often applied. These techniques transform strings into a standardized format before comparison.
Normalization ensures that different representations of the same character are treated as equivalent. This helps eliminate discrepancies caused by encoding variations.
There are multiple normalization forms, each designed to handle specific types of encoding differences. Some forms combine characters into single representations, while others decompose them into base components.
Choosing the appropriate normalization approach depends on the nature of the data being processed. For multilingual applications, normalization is essential for maintaining consistent behavior.
Without normalization, string comparison may produce inconsistent results even when strings appear identical. This makes it a critical step in reliable text processing workflows.
Hidden Characters and Invisible Data Challenges
Not all characters in a string are visible to the user. Some characters exist purely for formatting, control, or encoding purposes. These hidden characters can significantly affect string comparison outcomes.
Examples include zero-width spaces, non-printing control characters, and formatting markers. While invisible in most display contexts, they are still part of the string’s structure.
These characters often originate from copy-paste actions, external data imports, or system-generated text. Because they are not easily detectable, they can introduce subtle bugs in comparison logic.
Detecting and handling hidden characters requires careful inspection of string data. In many cases, preprocessing steps are used to remove or standardize these elements before comparison.
Failure to account for hidden characters can lead to confusing mismatches, where strings appear identical but fail to match in practice.
Performance Considerations in String Comparison Operations
String comparison is generally fast, but performance can vary depending on the method used and the size of the data being processed. Simple equality checks are highly efficient because they stop evaluation as soon as a mismatch is found.
However, more advanced comparison methods, such as locale-aware or normalized comparisons, require additional processing. This includes character transformation, encoding evaluation, and rule-based sorting logic.
In large-scale applications, repeated string comparisons can become performance-sensitive operations. This is especially true in sorting algorithms, search systems, and real-time data processing.
Optimizing string comparison often involves balancing accuracy with efficiency. In some cases, pre-processing strings before comparison can reduce repeated computation costs.
Understanding performance implications helps developers choose appropriate comparison strategies based on application requirements.
Security Implications of String Comparison Behavior
String comparison is also relevant in security-sensitive contexts, such as authentication systems, data validation, and access control mechanisms. In these scenarios, precision is critical.
Even small inconsistencies in string comparison can lead to security vulnerabilities or unintended access behavior. This is why strict and predictable comparison methods are often preferred in secure environments.
However, security systems must also handle real-world input variability. This creates tension between strict accuracy and practical usability.
Improper handling of string comparison in security contexts can lead to issues such as failed authentication attempts or unintended mismatches. Careful design is required to ensure both reliability and resilience.
Building Reliable Comparison Logic Through Layered Processing
Given the complexity of string behavior, reliable comparison often requires multiple layers of processing rather than a single operation. These layers may include case normalization, whitespace handling, encoding standardization, and punctuation management.
Each layer addresses a specific type of inconsistency that may arise in real-world data. When combined, they create a more stable and predictable comparison system.
This layered approach helps bridge the gap between raw machine evaluation and human expectations. It ensures that comparisons are both technically accurate and practically meaningful.
However, designing such systems requires careful consideration of context, as over-processing can sometimes remove meaningful distinctions between strings.
Understanding how to balance these layers is essential for building robust applications that handle text effectively in diverse environments.
Advanced String Comparison Techniques in JavaScript
As applications become more complex, simple string comparison methods are often no longer sufficient. Real-world data is rarely clean, consistent, or uniform. It comes from different sources, user inputs, external APIs, and legacy systems, all of which introduce subtle variations. Because of this, developers often need more advanced approaches to string comparison that go beyond direct equality or basic normalization.
Advanced string comparison is not just about checking whether two strings match. It is about understanding how close they are, how they differ, and whether those differences matter in context. This introduces the idea that comparison can be flexible rather than absolute.
One of the most common needs for advanced comparison is handling fuzzy matches. Fuzzy comparison allows two strings to be considered similar even if they are not identical. This is especially useful in search systems, typo correction, and user input matching.
Instead of requiring exact character-by-character equality, fuzzy logic evaluates similarity based on patterns, substitutions, insertions, and deletions. This allows systems to tolerate human error while still producing meaningful matches.
However, fuzzy comparison is inherently more computationally expensive and conceptually complex. It requires defining thresholds for similarity and deciding how much difference is acceptable before two strings are considered unrelated.
Pattern-Based Comparison and Partial Matching
Another important technique in advanced string comparison is pattern-based matching. Unlike strict comparison, which evaluates entire strings, pattern-based approaches focus on whether a string contains or follows a specific structure.
This is useful when exact equality is not necessary, but structural similarity is important. For example, checking whether a string contains a keyword or follows a specific format can be more meaningful than comparing full text.
Pattern-based comparison allows developers to extract meaningful information from strings without requiring them to be identical. It supports flexible matching logic where only certain parts of a string matter.
This approach is widely used in filtering systems, validation processes, and text extraction workflows. It helps reduce noise from irrelevant differences and focuses on the core structure.
However, pattern matching must be designed carefully. Overly broad patterns can produce false positives, while overly strict patterns may miss valid matches. Balancing precision and flexibility is key to effective implementation.
Similarity Scoring and Distance-Based Comparison
Beyond simple matching, strings can also be compared using similarity scoring systems. These systems assign a numerical value representing how closely two strings resemble each other.
Instead of returning a simple true or false result, similarity scoring provides a gradient of similarity. This allows developers to rank results or determine degrees of closeness between strings.
One common approach involves measuring the number of edits required to transform one string into another. These edits may include inserting, deleting, or replacing characters.
The fewer changes required, the more similar the strings are considered. This concept allows systems to handle misspellings, variations, and inconsistent formatting more gracefully.
Distance-based comparison is particularly useful in search engines and recommendation systems. It enables more intuitive matching where exact wording is not required.
However, similarity scoring introduces complexity in interpretation. Developers must decide what level of similarity is acceptable for a match, which can vary depending on context.
Case Folding and Language-Aware Standardization
While basic case normalization converts all characters to a uniform format, case folding goes further by addressing language-specific case rules. Different languages may have unique rules for how uppercase and lowercase letters behave.
Case folding ensures that comparisons remain consistent across linguistic boundaries. It is a more robust form of normalization that accounts for international text behavior.
This is especially important in multilingual applications where users may input text in different languages or scripts. Without case folding, comparisons may behave inconsistently across regions.
However, case folding must be applied carefully, as some transformations may not be reversible. Once text is normalized in this way, original formatting may be lost.
Despite this limitation, case folding remains an essential tool for building consistent string comparison systems in global applications.
Cultural Context in String Equivalence
String comparison is not purely technical; it is also influenced by cultural expectations. Different cultures interpret text formatting, spacing, and punctuation differently, which affects how equivalence is perceived.
For example, name formatting conventions vary widely across regions. In some cultures, family names appear first, while in others they appear last. This can lead to mismatches if strings are compared without considering cultural structure.
Similarly, punctuation usage varies across languages. What may be considered optional punctuation in one language may be essential in another. These differences must be considered when designing comparison logic.
Cultural context introduces an additional layer of complexity because it requires understanding how users interpret text rather than just how it is stored.
Ignoring cultural differences can lead to systems that appear inconsistent or incorrect to users, even if they are technically accurate.
Real-Time Comparison in Interactive Applications
In modern applications, string comparison often occurs in real time. This includes search suggestions, form validation, chat systems, and dynamic filtering interfaces.
Real-time comparison requires efficient algorithms because results must be generated instantly as users type or interact with the system.
This creates a challenge: balancing accuracy with speed. More advanced comparison techniques may produce better results but require more processing time.
To address this, many systems use staged comparison approaches. Initial filtering may use simple methods, followed by more complex evaluation for refined results.
This layered approach ensures responsiveness while still maintaining meaningful comparison logic.
Real-time comparison also requires handling incomplete input. Users may type partial strings, making it necessary to compare fragments rather than full values.
Edge Cases and Unexpected Comparison Behavior
String comparison often behaves unpredictably in edge cases. These are situations where standard rules do not produce expected results due to unusual input patterns.
Examples include empty strings, strings containing only whitespace, or strings with hidden or non-standard characters. These cases can produce surprising outcomes if not explicitly handled.
Another common edge case involves extremely long strings. Performance and memory constraints may affect comparison behavior in these scenarios.
Edge cases highlight the importance of robust testing and validation in string handling systems. Without careful consideration, rare input patterns can lead to unexpected bugs.
Understanding edge cases helps developers design systems that behave consistently even under unusual conditions.
Security-Focused String Comparison Strategies
In security-sensitive systems, string comparison must be handled with extreme care. Even small inconsistencies can lead to vulnerabilities or unintended access behavior.
One important consideration is timing consistency. Some naive comparison methods may reveal information based on how long comparisons take, which can be exploited in certain attack scenarios.
To prevent this, secure comparison methods aim to ensure consistent execution time regardless of input differences. This reduces the risk of information leakage.
Another concern is input sanitization. Strings must be carefully validated to ensure they do not contain unexpected characters or formats that could affect system behavior.
Security-focused comparison often prioritizes predictability and resistance to manipulation over flexibility or convenience.
Data Consistency Across Systems and Platforms
String comparison becomes even more complex when data is shared across multiple systems or platforms. Each system may handle encoding, formatting, and normalization differently.
These inconsistencies can lead to mismatches when comparing data from different sources. Even if values appear identical, underlying representations may differ.
To address this, data standardization practices are often used. These ensure that all systems follow consistent rules for storing and transmitting text data.
Without standardization, cross-system comparison becomes unreliable and prone to errors.
This is particularly important in distributed systems, where data is constantly moving between services and databases.
Human Perception vs Computational Equality
One of the most important concepts in string comparison is the difference between human perception and computational equality. Humans interpret meaning, context, and intent, while computers evaluate structure and data.
This difference explains why strings that appear identical to users may not match in code, and why seemingly different strings may sometimes be treated as equal after processing.
Bridging this gap requires careful design of comparison logic that considers both technical accuracy and human expectations.
In many cases, developers must decide whether the goal is strict equality or meaningful similarity. This decision shapes how comparison systems are implemented.
Understanding this distinction is essential for building applications that behave intuitively while still maintaining computational precision.
Designing Robust String Comparison Systems
Building a reliable string comparison system requires combining multiple techniques into a cohesive approach. No single method is sufficient for all scenarios.
A robust system typically includes normalization, case handling, whitespace management, encoding standardization, and optional similarity evaluation.
Each layer addresses a different type of inconsistency. Together, they create a structured pipeline that transforms raw input into comparable data.
However, over-processing can sometimes remove meaningful differences. This is why context plays a critical role in determining how much transformation is appropriate.
The goal is not to eliminate all variation but to control which variations matter for comparison.
Practical Considerations for Developers
Developers working with string comparison must consider several practical factors. These include data source reliability, user behavior patterns, performance constraints, and application requirements.
Different applications require different levels of strictness. Some systems demand exact matches, while others prioritize flexibility and user convenience.
Choosing the right comparison strategy depends on understanding the purpose of the data and how it will be used.
Testing is also essential. String comparison systems must be validated against real-world data to ensure they behave as expected under diverse conditions.
Ultimately, effective string comparison is not just a technical challenge but also a design decision that shapes user experience and system reliability.
Conclusion
String comparison in JavaScript is far more than a simple check for equality between two pieces of text. At a surface level, it may appear to be a straightforward operation—either two strings match, or they do not. However, as explored throughout the discussion, the reality is significantly more complex. Strings behave in a strictly literal manner, while human language operates in a flexible, context-driven way. This difference creates one of the most important challenges in programming: reconciling machine precision with human interpretation.
JavaScript treats strings as exact sequences of characters, where every detail matters. Capital letters are distinct from lowercase letters, spaces are meaningful characters, and punctuation is part of the data structure. Even invisible elements such as hidden whitespace or encoding differences can alter the outcome of a comparison. This strictness ensures computational accuracy but often conflicts with human expectations. People naturally interpret meaning rather than structure, which means they tend to overlook minor differences that computers cannot ignore.
Because of this gap, string comparison cannot rely on a single universal approach. Instead, it requires multiple strategies depending on the context. In some situations, strict equality is necessary, especially when dealing with security-sensitive data such as passwords or authentication tokens. In these cases, even the smallest variation must be treated as a mismatch to preserve integrity and prevent errors or vulnerabilities.
In other situations, flexibility is more important than precision. User input, search functionality, and data filtering systems often need to account for inconsistencies such as capitalization differences, extra spaces, or punctuation variations. In these cases, normalization techniques such as case conversion, whitespace trimming, and punctuation handling help create a more consistent basis for comparison. These adjustments allow systems to better align with how users naturally input and interpret text.
Beyond basic normalization, more advanced methods such as locale-aware comparison and similarity scoring introduce additional layers of intelligence. These approaches recognize that language is not universal and that cultural and linguistic differences influence how text should be interpreted. For example, alphabetical ordering rules may differ across languages, and accented characters may need special handling to ensure fair comparison. Similarly, similarity-based techniques allow systems to evaluate how closely two strings resemble each other rather than forcing a strict yes-or-no decision.
These advanced techniques highlight an important shift in how string comparison is approached in modern development. Instead of treating comparison as a binary operation, it is increasingly viewed as a spectrum of similarity. This perspective allows developers to build more intuitive and user-friendly systems that better reflect real-world language behavior. However, it also introduces new challenges, such as determining thresholds for similarity and balancing performance with accuracy.
Another critical insight is that string comparison is deeply influenced by data quality. Inconsistent input from users, external systems, or stored databases can significantly affect comparison outcomes. Hidden characters, encoding mismatches, and formatting inconsistencies often lead to unexpected results. As a result, preprocessing and normalization are not optional steps but essential parts of any reliable string-handling system. Without them, even the most advanced comparison logic can produce unreliable results.
Security considerations further emphasize the importance of careful string comparison design. In sensitive applications, predictable and consistent behavior is essential to prevent vulnerabilities. This often requires strict comparison methods that avoid ambiguity and ensure uniform execution. At the same time, developers must remain aware of performance implications, especially in systems that handle large volumes of text or require real-time responsiveness.
Ultimately, string comparison in JavaScript reflects a broader theme in software development: the tension between precision and flexibility. Computers excel at exactness, while humans rely on interpretation. Bridging this gap requires thoughtful design, layered processing, and a clear understanding of context. No single method can handle all scenarios, which is why developers must combine multiple techniques to achieve reliable results.
By understanding how strings behave internally, recognizing the limitations of strict equality, and applying appropriate normalization and comparison strategies, developers can create systems that are both accurate and user-friendly. String comparison is not just a technical operation—it is a reflection of how machines interpret human language, and mastering it is essential for building effective, real-world applications.