Modern software rarely performs just one task at a time. Whether it is a web server handling thousands of requests, a mobile app syncing data in the background, or a cloud system distributing workloads across machines, most real-world applications are expected to do many things simultaneously. This expectation has reshaped how programming languages are designed, especially those used in backend systems and cloud infrastructure.
Concurrency is the ability of a system to manage multiple tasks at the same time in a structured way. It does not necessarily mean that everything is executing simultaneously at the exact same instant. Instead, it focuses on making progress on multiple tasks efficiently, often by switching between them or distributing them across available processing resources.
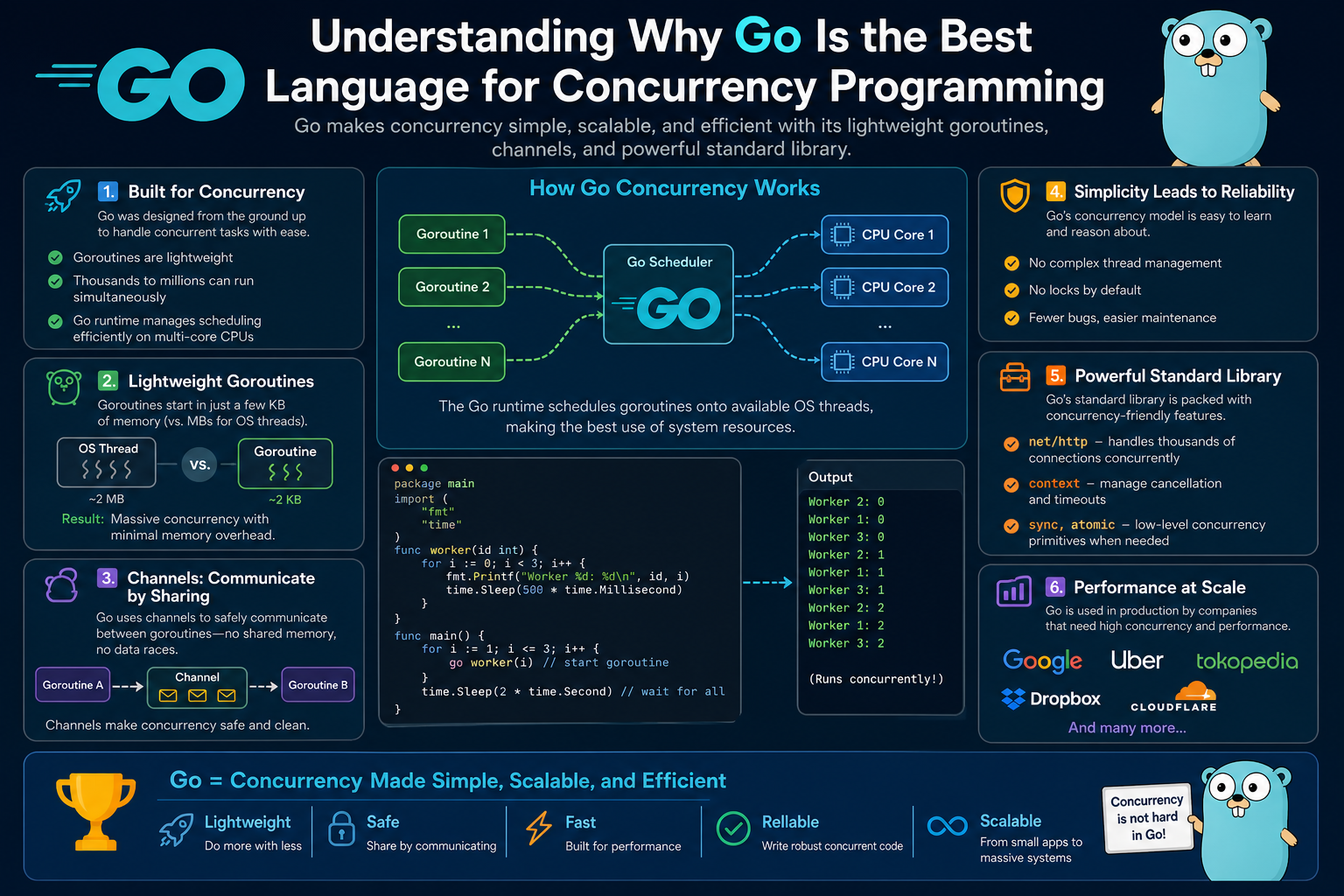
Go was created with this exact challenge in mind. Rather than treating concurrency as an advanced feature or an add-on library, it was built directly into the language’s foundation. This design decision is one of the primary reasons Go is widely recognized for its simplicity and performance in concurrent environments.
The Design Philosophy That Shapes Go’s Concurrency Model
To understand why Go handles concurrency so well, it is important to understand the philosophy behind its creation. Go was designed to simplify large-scale software development. Traditional programming languages often provide concurrency through complex thread management systems that require careful handling of memory, synchronization, and timing issues.
In contrast, Go takes a different approach. It reduces complexity by providing simple primitives that developers can use without needing to deeply manage system-level threads. This simplicity does not reduce power; instead, it hides complexity behind lightweight constructs that are easy to reason about.
The key idea is to make concurrent programming feel as natural as writing sequential code. Instead of requiring developers to manually manage operating system threads, Go introduces abstractions that are easier to create, control, and coordinate.
This philosophy also focuses heavily on readability and maintainability. As software systems grow, concurrency often becomes one of the most difficult areas to debug and scale. Go attempts to solve this problem by making concurrency a first-class feature rather than an afterthought.
Why Traditional Concurrency Models Are Challenging
Before exploring Go’s approach, it helps to understand why concurrency has traditionally been difficult in other programming environments.
Many languages rely on operating system threads for concurrent execution. While threads are powerful, they come with significant overhead. Each thread consumes memory, requires system resources, and involves complex scheduling decisions handled by the operating system.
As applications scale, managing thousands or millions of threads becomes inefficient. Context switching between threads also introduces performance costs, as the system must pause one thread and load another into execution.
Beyond performance concerns, traditional threading models introduce complexity in synchronization. When multiple threads access shared data, developers must carefully control how that data is modified. Failure to do so can lead to race conditions, deadlocks, or inconsistent system states.
These issues make concurrency powerful but difficult to use safely. Go addresses these challenges by introducing a model that reduces reliance on heavy threads and encourages safer communication patterns.
Goroutines as the Foundation of Go’s Concurrency Model
At the heart of Go’s concurrency system are goroutines. A goroutine is a lightweight unit of execution managed by the Go runtime rather than directly by the operating system.
Unlike traditional threads, goroutines are extremely lightweight. They start with a small memory footprint and can grow dynamically as needed. This allows programs to create thousands or even millions of goroutines without overwhelming system resources.
One of the most important differences between goroutines and traditional threads is how they are scheduled. Instead of relying solely on the operating system, Go uses its own scheduler. This scheduler manages goroutines efficiently by distributing them across available CPU cores and switching between them as needed.
This approach significantly reduces overhead and improves scalability. It allows Go programs to handle high levels of concurrency without requiring complex manual tuning from developers.
How Goroutines Simplify Concurrent Execution
Goroutines are designed to make concurrent execution simple. Instead of defining complex thread structures or managing lifecycle states, developers can create a goroutine with a single instruction.
Once a goroutine is launched, it runs independently of the main program flow. This independence allows multiple tasks to progress simultaneously without blocking each other unnecessarily.
What makes goroutines especially powerful is their ability to scale effortlessly. A single program can run thousands of goroutines performing different tasks such as handling network requests, processing data, or performing background computations.
Despite their simplicity, goroutines are not just lightweight threads. They are tightly integrated with the Go runtime, which manages their execution intelligently. This integration allows Go to optimize performance based on system load and available hardware resources.
The Role of the Go Runtime in Concurrency Management
The Go runtime plays a crucial role in making concurrency efficient. It acts as an intermediary between goroutines and the operating system, managing how tasks are scheduled and executed.
Instead of assigning each goroutine to a dedicated operating system thread, the runtime uses a smaller number of threads to execute many goroutines. This technique significantly reduces overhead and improves performance.
The runtime continuously monitors system conditions and adjusts execution strategies dynamically. If a goroutine becomes blocked, such as waiting for input or data, the runtime can pause it and switch execution to another goroutine.
This dynamic scheduling ensures that CPU resources are used efficiently, minimizing idle time and maximizing throughput.
Multi-Core Processing and Parallel Execution
Modern processors contain multiple cores, allowing true parallel execution of tasks. Go is designed to take full advantage of this hardware capability.
The Go scheduler distributes goroutines across available CPU cores, enabling multiple tasks to run simultaneously in parallel. This distribution allows applications to scale efficiently as hardware resources increase.
Instead of requiring developers to manually assign tasks to specific cores, Go handles this automatically. The runtime evaluates workload distribution and balances execution across cores to maintain optimal performance.
This capability is especially important for high-performance systems such as web servers, data processing pipelines, and distributed applications.
Work Scheduling and Efficiency Optimization
One of the most important aspects of Go’s concurrency model is its scheduling system. The scheduler is responsible for determining which goroutine runs at any given time.
It uses a concept often referred to as work distribution or work stealing. When a processor core finishes its assigned tasks or becomes idle, it can take work from other cores that are still busy. This ensures that no processing power is wasted.
This approach improves efficiency in environments with unpredictable workloads. Instead of having some cores overloaded while others remain idle, the system dynamically balances work across all available resources.
This behavior allows Go programs to remain highly responsive even under heavy load.
The Importance of Lightweight Execution
One of the defining characteristics of Go’s concurrency model is its lightweight nature. Goroutines are designed to consume minimal resources compared to traditional threads.
This lightweight design allows developers to scale applications without worrying about exhausting system memory or CPU resources. It also enables the creation of highly concurrent systems that would be impractical in many other languages.
Because goroutines are inexpensive to create and destroy, developers can use them freely for small, short-lived tasks as well as long-running processes.
This flexibility encourages a different style of programming where concurrency is not something to be carefully optimized at every step, but instead something that can be naturally integrated into the structure of an application.
Structured Communication as a Core Principle
While goroutines handle execution, Go also introduces a structured way for them to communicate. This is essential because concurrent tasks often need to exchange data or coordinate actions.
Rather than relying on shared memory and complex locking mechanisms, Go encourages communication-based concurrency. This means that instead of multiple tasks modifying the same data directly, they exchange information in a controlled manner.
This design reduces many of the risks associated with concurrency, such as race conditions or inconsistent state changes. It also makes programs easier to reason about, since data flow is explicit and structured.
The idea of structured communication is deeply tied to Go’s overall philosophy of simplicity and clarity.
Reducing Complexity in Concurrent Programming
One of Go’s most significant contributions to programming is its ability to reduce the complexity of concurrent systems. Traditional approaches often require developers to manage multiple layers of synchronization, locking, and resource sharing.
Go simplifies this by providing a small set of powerful tools that handle most concurrency needs. Developers do not need to manually manage threads or low-level synchronization primitives in most cases.
Instead, they can focus on designing the logic of their application while relying on the language runtime to handle execution details.
This separation of concerns improves productivity and reduces the likelihood of subtle concurrency bugs that are difficult to detect and reproduce.
The Practical Impact of Go’s Concurrency Model
The real strength of Go’s concurrency model becomes clear when applied to real-world systems. Applications such as web services, APIs, data processing systems, and cloud infrastructure often require handling many simultaneous operations.
Go’s model allows these systems to remain responsive under heavy load while maintaining efficient resource usage. It also makes scaling simpler, since increasing workload can often be handled by adding more hardware rather than redesigning the software architecture.
This practicality is one of the main reasons Go has become popular in modern backend development and distributed systems.
Building Toward Scalable System Design
Go’s concurrency model is not just about performance; it is also about enabling scalable system design. By providing simple primitives for concurrent execution and communication, Go allows developers to build systems that naturally scale with demand.
This scalability is achieved without requiring complex architectural patterns or heavy infrastructure overhead. Instead, scalability emerges from the language design itself.
As systems grow, this simplicity becomes increasingly valuable, allowing teams to maintain performance without increasing complexity.
Moving Beyond Basics: Understanding What Makes Goroutines Special
To truly understand why Go is so effective at concurrency, it is not enough to simply know that goroutines are “lightweight threads.” The deeper strength of goroutines lies in how they are implemented, managed, and optimized by the Go runtime.
Unlike traditional threads that are tied closely to operating system scheduling, goroutines exist at a higher abstraction level. They are managed primarily by the Go runtime scheduler, which has been carefully engineered to balance efficiency, responsiveness, and scalability.
This design allows goroutines to behave like independent tasks while avoiding many of the heavy costs associated with system threads. The result is a concurrency model that scales far beyond what is typically possible in many other programming environments.
The Relationship Between Goroutines and the Go Scheduler
At the core of Go’s concurrency system is the scheduler, which determines how goroutines are executed. Instead of mapping each goroutine directly to a system thread, the scheduler uses a multiplexing strategy.
This means that many goroutines share a smaller number of operating system threads. The scheduler continuously assigns, pauses, and resumes goroutines based on system load and availability of CPU resources.
This approach is significantly more efficient than traditional threading models. It reduces memory usage, minimizes context switching overhead, and improves CPU utilization.
The scheduler operates in a cooperative and preemptive manner, ensuring that no single goroutine can monopolize system resources indefinitely. This balance is critical for maintaining responsiveness in large-scale applications.
The M:N Scheduling Model Explained
Go uses what is known as an M:N scheduling model. In this model, M represents goroutines, and N represents operating system threads.
Instead of having a one-to-one mapping between threads and tasks, multiple goroutines are mapped onto a smaller number of threads. This allows the system to handle large numbers of concurrent tasks without overwhelming the operating system.
This model is one of the key reasons Go can efficiently manage thousands or even millions of concurrent operations. It reduces the cost of concurrency to a level where it becomes practical for everyday use in application design.
The scheduler dynamically adjusts how goroutines are distributed across threads depending on system conditions. This adaptability ensures optimal performance across different workloads.
Why Goroutines Are Extremely Lightweight
One of the most important characteristics of goroutines is their extremely small memory footprint. When a goroutine is created, it begins with a very small stack size. This stack can grow or shrink dynamically as needed.
This is fundamentally different from traditional threads, which often allocate large fixed stack sizes upfront. As a result, threads consume more memory even when they are idle or performing simple tasks.
Goroutines avoid this inefficiency by using segmented stacks. These stacks expand only when necessary, which allows the system to conserve memory and support a much larger number of concurrent tasks.
This design is especially important in modern applications where scalability is critical. Systems such as web servers or microservices may need to handle thousands of simultaneous connections, and goroutines make this feasible without excessive resource consumption.
Stack Growth and Memory Efficiency
The dynamic stack system used by goroutines plays a crucial role in Go’s efficiency. When a goroutine starts, it uses a small stack that is sufficient for simple operations. If the goroutine requires more memory—for example, due to deeper function calls or larger local variables—the stack grows automatically.
This growth is handled transparently by the runtime, meaning developers do not need to manually manage memory allocation for goroutines.
Similarly, if a goroutine’s memory usage decreases, the stack can shrink. This flexibility ensures that memory is used efficiently across the system.
This adaptive memory model is one of the reasons Go programs can scale so effectively without requiring complex memory management strategies.
Context Switching and Performance Optimization
Context switching refers to the process of saving and restoring the state of a task when switching between different tasks. In traditional threading models, context switching is expensive because it involves switching between operating system-level threads.
In Go, context switching between goroutines is significantly cheaper because it is handled primarily by the Go runtime rather than the operating system.
The runtime can switch between goroutines quickly because it only needs to save a small amount of state information. This reduces overhead and allows the system to handle a much higher number of concurrent tasks.
This efficiency is critical for high-performance applications where frequent task switching is required.
Preemption and Fair Scheduling
A common problem in concurrency systems is that a single task can sometimes run for too long, preventing other tasks from making progress. Go addresses this issue through preemption.
Preemption allows the scheduler to interrupt a running goroutine and switch execution to another goroutine. This ensures that all tasks receive fair access to CPU resources.
In earlier versions of Go, goroutines were primarily cooperative, meaning they yielded control voluntarily. Modern versions of Go include preemptive scheduling, which improves fairness and responsiveness.
This improvement ensures that long-running computations do not block the entire system, making Go more suitable for complex and unpredictable workloads.
The Role of Logical Processors
Go introduces the concept of logical processors, which are abstraction layers between the scheduler and the operating system.
Logical processors determine how many goroutines can be executed simultaneously. Each logical processor is assigned to an operating system thread, and each thread can run one goroutine at a time.
The number of logical processors can be adjusted based on available CPU cores, allowing Go programs to scale efficiently across different hardware configurations.
This abstraction helps separate hardware complexity from application logic, making it easier for developers to write scalable code without worrying about low-level system details.
How Blocking Operations Are Handled
In many programming languages, blocking operations such as file I/O or network requests can halt execution and reduce system efficiency. Go handles blocking differently.
When a goroutine performs a blocking operation, the runtime does not block the underlying thread. Instead, it parks the goroutine and allows the thread to execute other goroutines.
Once the blocking operation is complete, the goroutine is rescheduled for execution.
This design ensures that system resources are not wasted waiting for slow operations. It also improves responsiveness in applications that rely heavily on I/O operations.
Parallelism vs Concurrency in Go
It is important to distinguish between concurrency and parallelism in the context of Go.
Concurrency refers to the ability to manage multiple tasks at once, while parallelism refers to the actual simultaneous execution of tasks on multiple CPU cores.
Go supports both concurrency and parallelism. Goroutines provide concurrency, while the scheduler and logical processors enable parallel execution when multiple CPU cores are available.
This combination allows Go programs to efficiently utilize modern multi-core processors without requiring manual configuration from developers.
The Importance of Efficient Resource Utilization
One of the primary goals of Go’s concurrency system is efficient resource utilization. Instead of dedicating a large amount of memory and processing power to each task, Go shares resources intelligently among many goroutines.
This efficiency allows systems to scale vertically and horizontally without requiring significant architectural changes.
It also reduces operational costs in cloud environments, where resource usage directly impacts expenses.
By minimizing overhead and maximizing throughput, Go provides a practical solution for building high-performance systems.
The Lifecycle of a Goroutine
Understanding the lifecycle of a goroutine helps clarify how Go manages concurrency internally.
A goroutine begins when it is created and scheduled for execution. It then runs until it either completes its task, becomes blocked, or is preempted by the scheduler.
If the goroutine completes its work, it is removed from the scheduler. If it becomes blocked, it is paused and stored until it can resume execution. If it is preempted, it is temporarily suspended and later resumed.
This lifecycle is managed entirely by the runtime, freeing developers from manual thread management.
Error Isolation and Stability in Concurrent Execution
One of the advantages of Go’s concurrency model is that goroutines are isolated from each other in terms of execution state. This isolation helps improve system stability.
If one goroutine encounters an error or panic, it does not necessarily affect other goroutines. This separation ensures that failures are contained and do not cascade through the system.
This design is particularly useful in large distributed systems where reliability is critical.
Reducing Complexity Through Simplicity
Despite the internal complexity of the Go runtime, the external programming model remains simple. Developers interact with goroutines using minimal syntax and straightforward constructs.
This simplicity is intentional. It allows developers to focus on application logic rather than system-level details.
By hiding complexity behind simple abstractions, Go makes concurrent programming more accessible and less error-prone.
Practical Implications for Real-World Applications
The internal mechanics of goroutines directly translate into real-world benefits. Applications built with Go can handle high levels of concurrency without significant performance degradation.
This makes Go particularly well-suited for systems such as APIs, microservices, messaging systems, and distributed architectures.
Its ability to efficiently manage thousands of concurrent operations allows developers to build scalable systems with relatively simple code structures.
The Continuous Evolution of Go’s Concurrency System
Go’s concurrency model continues to evolve as computing environments become more complex. Improvements in scheduling, memory management, and runtime efficiency ensure that goroutines remain highly effective in modern systems.
These enhancements reflect Go’s commitment to maintaining a balance between simplicity and performance.
As hardware evolves and workloads become more demanding, Go’s concurrency model is designed to adapt without requiring fundamental changes to application code.
Why Communication Matters as Much as Execution in Concurrency
In concurrent programming, running multiple tasks at the same time is only half of the problem. The other half is how those tasks communicate safely and predictably.
Many concurrency issues do not come from execution itself but from shared data access. When multiple tasks try to read and write the same memory at the same time, unexpected behavior can occur. These issues are often difficult to detect and even harder to reproduce.
Go addresses this challenge with a simple but powerful idea: instead of sharing memory to communicate, communicate to share memory. This shift in thinking is central to how Go achieves safe and scalable concurrency.
Rather than relying heavily on locks and shared variables, Go encourages structured communication between concurrent tasks using channels.
The Concept of Channels in Go
Channels are one of the most important features in Go’s concurrency model. They provide a safe and controlled way for goroutines to exchange data.
A channel can be thought of as a pipeline or conduit through which data flows. One goroutine sends data into the channel, while another goroutine receives that data.
This mechanism ensures that communication between concurrent tasks is explicit, synchronized, and safe.
Channels are strongly typed, meaning they are designed to carry only a specific type of data. This type safety helps prevent errors and ensures consistency in communication.
By enforcing structured communication, channels eliminate many of the risks associated with shared memory concurrency models.
How Channels Control Data Flow
One of the most important characteristics of channels is that they synchronize communication automatically.
When a goroutine sends data into a channel, it may be blocked until another goroutine is ready to receive that data. Similarly, a receiving goroutine may wait until data becomes available.
This built-in synchronization ensures that data is transferred safely between goroutines without requiring explicit locking mechanisms.
This behavior also introduces natural coordination between concurrent tasks, making it easier to design predictable workflows.
Channels therefore serve both as a communication mechanism and a synchronization tool.
Buffered vs Unbuffered Channels
Channels in Go can be either buffered or unbuffered, and this distinction affects how they behave.
An unbuffered channel requires both the sender and receiver to be ready at the same time. This creates a strict synchronization point between goroutines.
A buffered channel, on the other hand, allows a limited number of values to be stored in the channel without requiring immediate reception. This introduces flexibility in how goroutines interact.
Buffered channels are useful when tasks need to be decoupled slightly, allowing one goroutine to continue working without waiting for immediate processing by another.
Unbuffered channels are useful when strict coordination is required.
This flexibility allows developers to design communication patterns that match the needs of their applications.
Channels as Coordination Tools
Beyond simple data transfer, channels play a critical role in coordinating complex workflows.
In many concurrent systems, tasks must happen in a specific order or depend on the completion of other tasks. Channels provide a natural way to express these dependencies.
Instead of using complex synchronization primitives, developers can structure workflows so that goroutines wait for signals or data from other goroutines.
This creates a clear and readable flow of execution, even in highly concurrent systems.
Channels therefore act as both communication mechanisms and coordination structures.
Eliminating Shared Memory Complexity
One of the most difficult aspects of traditional concurrency models is shared memory management. When multiple threads access the same memory, developers must carefully use locks, semaphores, or other synchronization techniques.
These mechanisms are powerful but often complex and error-prone. Mistakes can lead to deadlocks, race conditions, or unpredictable behavior.
Go reduces this complexity by encouraging a different approach. Instead of sharing memory directly, goroutines communicate through channels.
This means that data is passed explicitly between tasks rather than being accessed simultaneously.
As a result, many of the common pitfalls of concurrent programming are avoided entirely.
How Channels Improve System Safety
Safety in concurrent programming refers to the ability of a system to avoid incorrect or inconsistent states when multiple tasks operate simultaneously.
Channels improve safety by enforcing controlled access to data. Since data is transferred explicitly between goroutines, there is no ambiguity about ownership or modification.
At any given time, only one goroutine interacts with a piece of data being transmitted through a channel.
This reduces the risk of race conditions and ensures that data integrity is maintained across the system.
This safety model allows developers to build complex concurrent systems with greater confidence.
Synchronization Without Explicit Locks
In many programming languages, synchronization is achieved through locks such as mutexes. While effective, locks require careful handling to avoid issues like deadlocks or contention.
Go reduces the need for explicit locking by using channels as synchronization primitives.
When goroutines communicate through channels, synchronization happens automatically. There is no need to manually acquire or release locks.
This simplifies code and reduces the likelihood of synchronization-related bugs.
However, Go still provides traditional locking mechanisms when needed, allowing developers to choose the most appropriate tool for each situation.
The Role of Select in Channel Management
Go provides a powerful construct that allows goroutines to wait on multiple channel operations simultaneously.
This mechanism enables flexible decision-making in concurrent systems. A goroutine can listen to multiple communication paths and respond to whichever becomes available first.
This capability is especially useful in systems where multiple events may occur independently, such as network servers or event-driven applications.
By allowing multiple channels to be monitored simultaneously, Go enables more dynamic and responsive concurrency patterns.
Building Pipelines with Channels
One of the most powerful uses of channels is in building pipelines. A pipeline is a sequence of processing stages where data flows from one stage to the next.
Each stage of the pipeline is typically handled by a separate goroutine, and channels are used to pass data between stages.
This design allows complex processing tasks to be broken down into smaller, manageable components.
Pipelines improve modularity, readability, and scalability. They also allow different stages to operate concurrently, improving overall performance.
This pattern is widely used in data processing systems and streaming applications.
Fan-In and Fan-Out Patterns
Channels enable advanced concurrency patterns such as fan-in and fan-out.
In a fan-out pattern, a single input is distributed across multiple goroutines for parallel processing. This allows workloads to be divided and processed simultaneously.
In a fan-in pattern, multiple goroutines send their results into a single channel, combining outputs into one stream.
These patterns are essential for building scalable systems that process large volumes of data efficiently.
They allow developers to distribute work dynamically and collect results in a coordinated manner.
Handling Backpressure in Concurrent Systems
Backpressure occurs when a system is overwhelmed by more data than it can process. Without proper handling, this can lead to memory exhaustion or system instability.
Channels help manage backpressure by naturally blocking senders when receivers are not ready.
This built-in flow control prevents uncontrolled data accumulation and ensures that systems remain stable under heavy load.
Buffered channels can also be used to absorb temporary spikes in workload, providing additional flexibility in system design.
Error Handling in Concurrent Workflows
Error handling in concurrent systems can be challenging because multiple tasks may fail independently.
Go encourages explicit error handling through channel-based communication. Errors can be transmitted through channels just like regular data, allowing centralized handling of failures.
This approach ensures that errors are not lost or ignored in complex concurrent workflows.
It also allows systems to gracefully recover or shut down when necessary.
Combining Goroutines and Channels Effectively
The true power of Go’s concurrency model emerges when goroutines and channels are used together.
Goroutines provide the execution model, while channels provide the communication and coordination layer.
Together, they enable developers to build systems that are both highly concurrent and safe.
This combination allows for clean separation of concerns, where each goroutine focuses on a specific task while channels handle interaction between tasks.
Avoiding Common Concurrency Pitfalls
Many concurrency issues arise from improper synchronization or uncontrolled shared state. Go’s design helps reduce these risks, but developers still need to follow best practices.
One common issue is leaking goroutines, where goroutines continue running indefinitely without being properly terminated.
Channels can help manage lifecycle control by signaling completion or cancellation between tasks.
Another issue is overusing buffered channels without understanding their impact on system flow. While buffering can improve performance, it can also hide synchronization problems if not used carefully.
Understanding how channels influence execution flow is essential for building reliable systems.
Real-World Impact of Channel-Based Concurrency
The channel-based concurrency model is widely used in real-world systems that require high reliability and scalability.
Examples include web servers handling thousands of simultaneous requests, data processing systems analyzing large streams of information, and distributed services coordinating across multiple machines.
In these environments, clarity and safety are just as important as performance. Channels provide a structured way to manage complexity without sacrificing efficiency.
This balance is one of the reasons Go is often chosen for cloud-native and distributed systems.
How Go Encourages a Different Way of Thinking
Perhaps the most important aspect of Go’s concurrency model is how it changes the way developers think about system design.
Instead of focusing on shared state and synchronization, developers focus on data flow and communication.
This shift leads to clearer, more modular, and more maintainable systems.
It also encourages designing systems as networks of independent components rather than tightly coupled structures.
This architectural mindset aligns well with modern software design principles such as microservices and event-driven systems.
The Lasting Value of Go’s Concurrency Model
Go’s approach to concurrency is not just a technical implementation detail. It represents a broader philosophy of simplicity, clarity, and efficiency.
By combining goroutines for execution and channels for communication, Go provides a complete concurrency toolkit that is both powerful and easy to use.
This design allows developers to build systems that scale naturally while remaining understandable and maintainable.
As software systems continue to grow in complexity, this balance between simplicity and power becomes increasingly valuable.
Understanding Time Behavior in Channel Communication
One of the most subtle but important aspects of Go’s concurrency model is how time behaves inside channel-based communication. Unlike sequential programs where operations occur in a strict linear order, concurrent systems introduce timing variability. In Go, channels help stabilize this unpredictability by enforcing structured waiting points between goroutines.
When a goroutine sends data into an unbuffered channel, it does not simply “push and continue.” Instead, it enters a waiting state until another goroutine receives that data. This waiting behavior introduces a form of synchronization that aligns two independent execution paths at a shared point in time.
This time-based coordination is what makes channels powerful beyond simple data transfer. They act as timing anchors in a concurrent system, ensuring that certain operations cannot proceed until specific conditions are met. This eliminates the need for manual timing controls or complex coordination logic.
In distributed systems or high-throughput servers, this kind of predictable timing behavior is essential for maintaining consistency under load.
Channel Ownership and Data Flow Discipline
Another important concept in Go concurrency is the idea of implicit channel ownership. While channels can be passed between goroutines, it is usually clear in well-designed systems which goroutine is responsible for sending data and which is responsible for receiving it.
This implicit ownership model helps enforce a disciplined data flow architecture. Instead of multiple parts of a program randomly reading and writing shared data, each goroutine plays a defined role in the communication pipeline.
This clarity reduces confusion in large systems. It also makes debugging easier, because developers can trace the flow of data through a series of well-defined communication steps.
By structuring programs around ownership and responsibility rather than shared access, Go encourages more predictable system design.
Designing Long-Running Concurrent Systems
In real-world applications, concurrency is not just about executing tasks in parallel; it is about managing long-running processes that must remain stable over time.
Go’s concurrency model is particularly well-suited for these kinds of systems. Goroutines can remain active for long durations, continuously processing data from channels without requiring manual intervention.
This makes it possible to design systems that behave like continuous pipelines. Data flows in, is processed in stages, and flows out in a transformed state, all without restarting or reinitializing components.
Such designs are common in network servers, logging systems, streaming platforms, and monitoring tools.
The stability of long-running goroutines is supported by the Go runtime, which ensures efficient scheduling and memory management even under sustained workloads.
Coordinated Shutdown in Concurrent Systems
One of the challenges in concurrent programming is safely shutting down a system without losing data or leaving tasks incomplete.
Go provides patterns for coordinated shutdown using channels as signaling mechanisms. Instead of abruptly terminating processes, systems can use channels to broadcast shutdown signals to all active goroutines.
Each goroutine can listen for this signal and complete its current work before exiting gracefully. This ensures that resources are cleaned up properly and no partial operations are left unresolved.
Coordinated shutdown is especially important in server environments, where abrupt termination could lead to data corruption or inconsistent states.
By using channels for shutdown coordination, Go enables controlled and predictable system termination.
Channel Directionality and Communication Safety
Go also allows channels to be defined with directional constraints. A channel can be restricted to only sending or only receiving data within a specific context.
This design feature adds another layer of safety to concurrent programming. By restricting channel usage, developers can prevent unintended misuse of communication pathways.
For example, a function responsible only for processing data might be given a receive-only channel, ensuring it cannot accidentally send data back into the system.
This enforcement of directionality improves code clarity and reduces the risk of logical errors in complex systems.
It also reinforces the idea that communication paths should have clearly defined roles within a system.
Dynamic Work Distribution Using Channels
In advanced concurrency designs, channels are often used to dynamically distribute work across multiple goroutines.
Instead of assigning fixed tasks to fixed workers, a central channel can act as a task queue. Multiple worker goroutines then pull tasks from this channel as they become available.
This creates a flexible and scalable system where workload distribution adjusts automatically based on processing capacity.
If more workers are added, the system naturally processes tasks faster without requiring changes to the overall architecture.
This pattern is widely used in job processing systems, task schedulers, and background processing engines.
Channel-Based Event Systems
Channels are also well-suited for building event-driven systems. In such systems, events are represented as messages that flow through channels to interested goroutines.
Each goroutine can act as an event handler, responding to specific types of messages.
This model allows systems to react dynamically to changing conditions without relying on rigid control structures.
Event-driven concurrency is particularly useful in applications such as user interfaces, real-time analytics, and distributed monitoring systems.
It enables loose coupling between components, improving modularity and scalability.
The Importance of Predictability in Concurrent Design
One of the biggest challenges in concurrency is unpredictability. When multiple tasks execute simultaneously, the order of operations can vary, leading to inconsistent results if not carefully managed.
Go’s concurrency model addresses this challenge by introducing structured communication through channels. Because data transfer between goroutines is explicit and synchronized, the flow of execution becomes more predictable.
This predictability is critical for debugging and maintaining complex systems. Developers can reason about system behavior more easily when communication pathways are clearly defined.
Predictability also improves reliability in production environments, where unpredictable behavior can lead to system failures or data inconsistencies.
Conclusion
Go’s approach to concurrency represents a clear shift in how modern software systems are designed and built. Instead of treating concurrency as an advanced or optional feature, Go places it at the center of the language. This decision fundamentally changes how developers think about running multiple tasks, handling workloads, and designing scalable systems.
At the heart of Go’s concurrency model are goroutines and channels, two simple yet powerful constructs that work together to manage complexity. Goroutines provide a lightweight and efficient way to execute multiple tasks simultaneously, while channels offer a structured and safe mechanism for communication between those tasks. This combination replaces many of the traditional challenges associated with threads, locks, and shared memory.
What makes Go especially powerful is not just its ability to run many tasks at once, but how efficiently it does so. The Go runtime manages scheduling, memory, and execution in a way that maximizes performance while minimizing overhead. This allows applications to scale to thousands or even millions of concurrent operations without the heavy resource costs typically seen in other programming environments.
Equally important is the clarity that Go brings to concurrent programming. By encouraging communication over shared state, it reduces the risk of common issues such as race conditions and deadlocks. This leads to systems that are easier to reason about, debug, and maintain over time. Developers can focus more on application logic rather than low-level synchronization details.
In real-world use, this design proves especially valuable in cloud computing, distributed systems, APIs, and high-performance backend services. These environments demand both speed and reliability, and Go delivers both through its concurrency model.
Ultimately, Go’s concurrency design is not just a technical feature but a thoughtful engineering philosophy. It prioritizes simplicity without sacrificing power, and structure without adding unnecessary complexity. This balance is what makes Go stand out as a modern language built for the demands of scalable, concurrent computing systems.