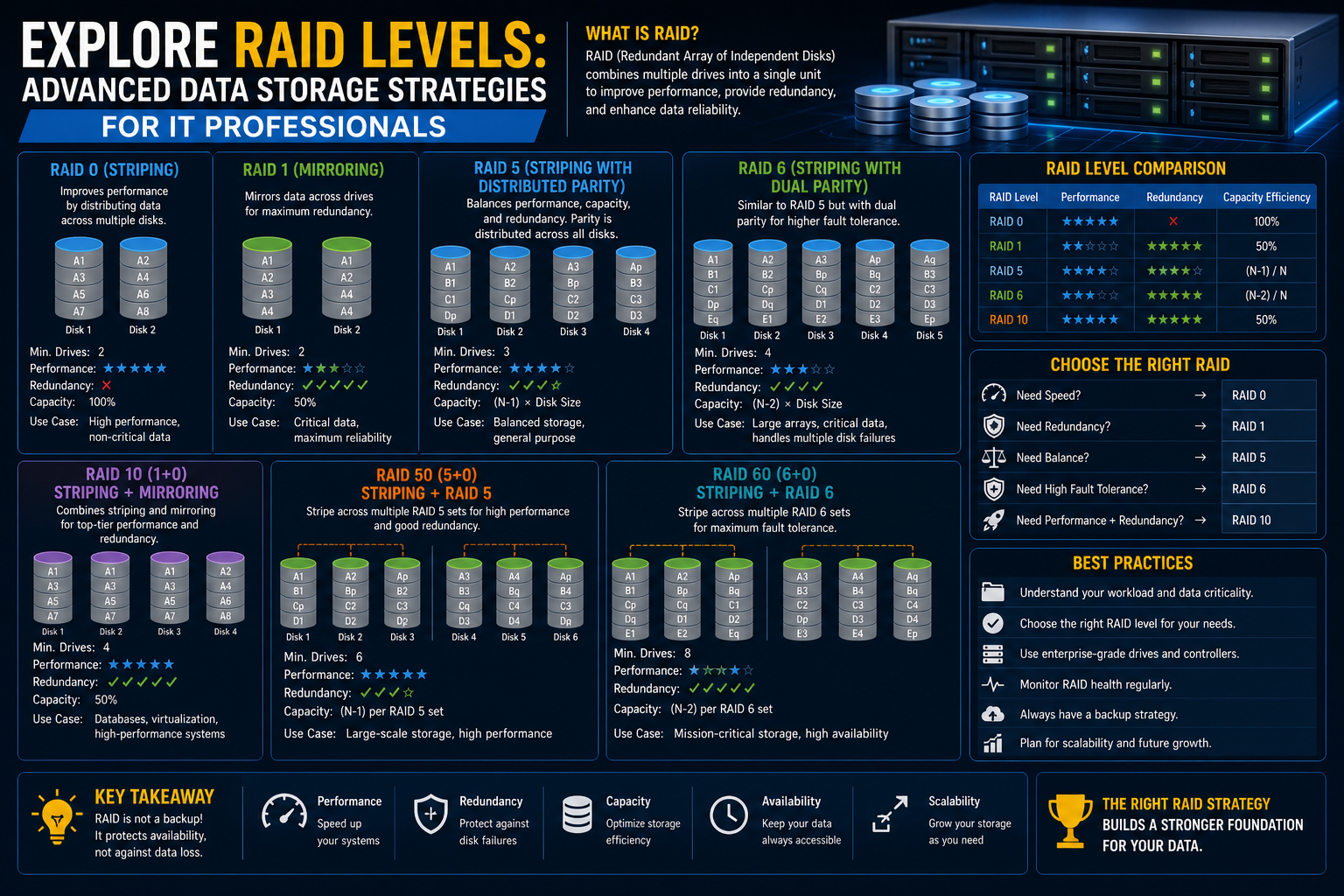
In the world of data storage, reliability and performance are two forces that often work against each other. Systems that prioritize speed sometimes sacrifice safety, while systems designed for maximum protection can introduce delays and inefficiencies. This is where RAID, or Redundant Array of Independent Disks, becomes a foundational concept in modern IT infrastructure.
RAID is not a single technology but rather a collection of techniques that combine multiple physical storage drives into a unified system. The goal is to improve performance, increase data availability, and reduce the risk of data loss. Depending on how the disks are configured, RAID can either focus on speed, redundancy, or a balanced mix of both.
At its core, RAID works by distributing data across multiple drives in different ways. This distribution can involve splitting data into smaller chunks, duplicating it, or adding error-correcting information known as parity. Each method serves a specific purpose, and each RAID level represents a different configuration strategy.
Understanding RAID is essential for anyone working with servers, storage systems, or enterprise networks. Even in consumer-level systems, RAID concepts influence how data is stored and protected behind the scenes. The following sections explore the most fundamental RAID levels and concepts that form the foundation of more advanced configurations.
The Core Idea Behind Disk Striping and Data Distribution
Before diving into specific RAID levels, it is important to understand the basic principle of disk striping. Striping refers to the process of dividing data into blocks and distributing those blocks across multiple storage drives.
Instead of writing a file entirely to one disk, striping spreads the file across several disks. This allows multiple drives to work simultaneously when reading or writing data. As a result, performance improves significantly because the workload is shared.
However, striping alone does not provide protection. If one disk fails in a striped setup without redundancy, part of the data becomes corrupted or completely lost. This limitation leads directly to the development of different RAID levels, each addressing the balance between speed and data safety in unique ways.
Striping is a building block for many RAID configurations, especially those that focus on performance. It is also one of the reasons RAID systems are widely used in environments where high-speed data access is essential, such as databases, virtualization platforms, and large-scale file systems.
RAID 0: Maximum Performance Without Safety Nets
RAID 0 is one of the simplest RAID configurations, yet it is often misunderstood. It is designed purely for performance. In RAID 0, data is striped across two or more drives without any form of redundancy or backup.
This means that when a file is written to the RAID array, it is split into segments and distributed evenly across all available disks. Because multiple disks are working at the same time, read and write speeds increase dramatically.
For example, if a file is divided into four parts and stored across four drives, each drive handles only a portion of the workload. When the file is accessed, all drives contribute simultaneously, reducing access time.
However, this performance advantage comes with a serious drawback. RAID 0 offers zero fault tolerance. If even one disk fails, the entire dataset becomes corrupted or inaccessible. Since there is no parity or duplication, nothing can be recovered.
This makes RAID 0 suitable only for scenarios where speed is more important than data safety. It is commonly used in temporary processing environments, high-speed caching systems, and gaming setups where performance is prioritized and data loss is not critical.
Another important characteristic of RAID 0 is scalability. As more disks are added, performance continues to improve because data is distributed across a larger number of drives. However, the risk also increases, because the probability of failure rises with each additional disk.
Despite its risks, RAID 0 remains a valuable configuration when used in controlled environments where data is either backed up elsewhere or not essential for long-term storage.
Practical Behavior of RAID 0 in Real Systems
In practical applications, RAID 0 behaves like a single fast storage unit. The operating system sees the array as one logical drive, even though multiple physical disks are involved.
When reading data, RAID 0 retrieves blocks from all disks simultaneously. This parallel access significantly reduces latency. When writing data, the system divides the information and distributes it across all drives at the same time.
This architecture makes RAID 0 extremely efficient for large sequential data operations, such as video editing, rendering, or large file transfers. However, it does not handle small-scale redundancy tasks or error recovery.
One of the key risks in RAID 0 systems is the “single point of failure” problem. Since there is no duplication or parity, the failure of one disk leads to total data loss. This is why RAID 0 is often paired with external backup solutions in environments where it is used.
RAID 1: Mirroring for Maximum Data Protection
While RAID 0 focuses on speed, RAID 1 takes the opposite approach by prioritizing data protection. RAID 1 uses a method called mirroring, where data is duplicated across two or more disks.
In a RAID 1 configuration, every piece of data written to one disk is simultaneously written to another disk. This creates an exact copy of the data at all times. If one disk fails, the system can continue operating using the mirrored disk without interruption.
This redundancy makes RAID 1 one of the simplest and most reliable forms of data protection. It is widely used in systems where data integrity is critical, such as financial systems, small business servers, and essential application storage.
Unlike RAID 0, RAID 1 does not improve performance significantly. Write operations may even be slightly slower because data must be written twice. However, read performance can improve in some configurations because data can be retrieved from either disk.
How RAID 1 Maintains Data Integrity
The strength of RAID 1 lies in continuous duplication. Every write operation is mirrored in real time. This ensures that both disks always contain identical information.
If one disk becomes corrupted or fails completely, the system simply switches to the remaining disk without data loss. Once the failed disk is replaced, the system rebuilds the mirror by copying data from the healthy drive.
This rebuild process ensures that redundancy is restored without requiring downtime in many configurations. However, during the rebuild, system performance may be temporarily reduced.
RAID 1 is often considered a foundational redundancy method because of its simplicity and reliability. It does not rely on complex parity calculations or striping logic, which makes it easier to implement and maintain.
Cost and Storage Efficiency Considerations in RAID 1
One of the main drawbacks of RAID 1 is storage inefficiency. Since data is duplicated, only half of the total storage capacity is usable. For example, two 1TB drives in RAID 1 provide only 1TB of usable storage.
This trade-off between redundancy and capacity is a key consideration when designing storage systems. Organizations must decide whether the benefit of full data duplication justifies the loss of available space.
Despite this limitation, RAID 1 remains popular because storage costs are often outweighed by the importance of data protection. Losing critical data can be far more expensive than the cost of additional storage hardware.
Read and Write Behavior in RAID 1 Systems
In RAID 1, write operations are straightforward but duplicated. Every write must be performed on all mirrored disks, ensuring consistency.
Read operations, however, can be optimized. Some RAID implementations allow the system to read from either disk, balancing the load between drives. This can lead to improved read performance compared to a single disk system.
However, the overall performance improvement is not as significant as RAID 0. RAID 1 is designed for reliability, not speed.
Nested RAID: Combining Multiple RAID Levels for Balanced Performance
As storage needs became more complex, engineers began combining different RAID levels to take advantage of multiple benefits at once. This approach is known as nested RAID or hybrid RAID.
Nested RAID configurations layer one RAID type on top of another. This allows systems to balance performance, redundancy, and storage efficiency in more advanced ways.
One of the most well-known examples is RAID 10, also written as RAID 1+0. In this configuration, data is first mirrored (RAID 1) and then striped (RAID 0). This combination provides both high performance and strong fault tolerance.
RAID 10: A Balance Between Speed and Protection
In RAID 10, data is mirrored across pairs of disks, and then those mirrored sets are striped together. This structure allows the system to achieve high read and write speeds while maintaining redundancy.
If a disk fails, its mirrored partner continues to operate, ensuring no data loss. At the same time, striping across multiple mirrored pairs maintains strong performance.
RAID 10 is often used in high-performance environments such as database servers and enterprise applications where both speed and reliability are essential.
However, RAID 10 requires a minimum of four drives and uses half of the total storage capacity for mirroring. Despite this inefficiency, its performance and resilience make it a preferred choice in many critical systems.
Structural Behavior of Nested RAID Systems
Nested RAID systems are more complex than single-level RAID configurations because they combine multiple mechanisms of data handling. The system must manage both striping and mirroring simultaneously, depending on the configuration.
This complexity allows for highly optimized storage architectures but also increases the cost and hardware requirements. More disks are needed, and more sophisticated RAID controllers or software systems are required to manage data flow.
Despite the complexity, nested RAID configurations are widely used in enterprise environments where performance and reliability must coexist without compromise.
Why RAID Fundamentals Are Essential Before Advanced Levels
Understanding RAID 0, RAID 1, and nested RAID structures is critical before exploring more advanced RAID levels. These foundational concepts introduce the key trade-offs in storage design: speed versus redundancy, capacity versus protection, and simplicity versus complexity.
Every advanced RAID level builds upon these ideas. Whether a system uses parity, distributed redundancy, or dual-parity protection, the underlying principles remain rooted in striping and mirroring.
By mastering these foundational RAID concepts, it becomes easier to understand how modern storage systems achieve both high performance and data reliability in demanding environments.
Managing DHCP Relay, Multi-Site Networks, and Enterprise IP Delivery
In large-scale Windows Server environments, DHCP does not operate in a simple single-network structure. Instead, it must function across multiple subnets, VLANs, and sometimes geographically distributed sites. Since DHCP relies on broadcast-based communication, it cannot naturally cross routed boundaries. This limitation makes DHCP relay configuration a critical part of enterprise network design.
A DHCP relay agent acts as an intermediary between DHCP clients and DHCP servers. When a client sends a broadcast request for an IP address, the relay agent intercepts it and forwards it as a unicast message to a designated DHCP server. The server then responds through the relay agent, which delivers the response back to the client.
Without relay agents, every subnet would require its own DHCP server. This would significantly increase infrastructure complexity and administrative overhead. Relay agents solve this problem by allowing centralized DHCP management across distributed networks.
In Windows Server environments, relay functionality is often implemented through routers or dedicated network devices. Proper configuration ensures that DHCP traffic flows efficiently between clients and servers without delay or packet loss.
Relay configuration must also consider network security. Since DHCP requests are forwarded across segments, administrators must ensure that only authorized relay agents are allowed to communicate with DHCP servers. This prevents rogue devices from intercepting or manipulating address assignment traffic.
Designing DHCP for Multi-Site Enterprise Environments
In enterprise networks with multiple physical locations, DHCP design becomes more complex. Each site may have different network requirements, bandwidth limitations, and device densities. A centralized DHCP strategy must account for these differences while maintaining consistent address management.
One common approach is centralized DHCP with distributed relay agents. In this model, a single or small number of DHCP servers handle all address assignments, while relay agents at each site forward client requests. This simplifies management but requires reliable connectivity between sites.
Another approach is distributed DHCP, where each site has its own local DHCP server. This reduces dependency on WAN connectivity but increases administrative overhead. Each server must be independently managed, and configuration consistency must be maintained manually or through automation.
A hybrid approach is often used in large organizations, combining centralized control with local redundancy. In this setup, primary DHCP services are centralized, while secondary servers provide failover support at remote sites.
When designing DHCP for multi-site environments, administrators must carefully plan scope allocation. Each site should have its own defined IP range to avoid overlap and conflicts. Subnetting plays a critical role in ensuring that address spaces remain organized and scalable.
DHCP Failover and High Availability Strategies
Network reliability is a key requirement in modern enterprise systems. DHCP is a critical service, and any downtime can prevent devices from joining the network. To address this, Windows Server supports DHCP failover configurations that provide redundancy and high availability.
DHCP failover allows two servers to share responsibility for a scope. In this configuration, both servers maintain synchronized lease information. If one server becomes unavailable, the other continues to provide IP addresses without interruption.
There are two primary failover modes: load sharing and hot standby. In load sharing mode, both servers actively distribute IP addresses, balancing the workload between them. In hot standby mode, one server remains passive while the other handles all requests until a failure occurs.
Lease synchronization between failover partners ensures consistency in address allocation. This prevents conflicts and ensures that clients receive the same IP address even if they switch between servers.
Failover configuration requires careful planning of communication intervals, state transitions, and replication timing. Improper configuration can lead to inconsistencies or delayed failover responses.
High availability is especially important in environments where continuous connectivity is required, such as data centers, financial systems, and large corporate networks.
Securing DHCP Infrastructure in Windows Server
Security is a critical aspect of DHCP management. Since DHCP controls IP assignment across the entire network, unauthorized access can lead to serious disruptions, including IP conflicts, traffic interception, and network downtime.
One of the primary security mechanisms is DHCP authorization in Active Directory. Only authorized DHCP servers are allowed to operate within a domain environment. This prevents rogue DHCP servers from distributing incorrect or malicious network configurations.
Another important security feature is DHCP snooping, which is typically implemented at the network switch level. DHCP snooping filters unauthorized DHCP messages and ensures that only trusted servers can respond to client requests.
Access control within Windows Server also plays a significant role. Administrative permissions should be strictly controlled using role-based access control. Only authorized personnel should be able to modify scopes, reservations, or DHCP options.
Logging and auditing are also essential for security monitoring. DHCP logs provide detailed records of IP address assignments, renewals, and releases. These logs can be used to investigate suspicious activity or diagnose network issues.
In addition to internal security, external threats must also be considered. DHCP starvation attacks, for example, attempt to exhaust the available IP address pool by sending大量 fake requests. Rate limiting and monitoring mechanisms help mitigate such threats.
Monitoring DHCP Performance and Network Health
Continuous monitoring is essential for maintaining a healthy DHCP environment. Without proper monitoring, issues such as address exhaustion, scope misconfiguration, or service failure may go unnoticed until they cause significant disruption.
Windows Server provides built-in tools for monitoring DHCP performance. These tools display real-time statistics about active leases, available addresses, and request rates.
Administrators must regularly review scope utilization to ensure that address pools are not approaching exhaustion. If a scope becomes full, new devices will be unable to obtain IP addresses, resulting in connectivity failures.
Performance monitoring also includes tracking request latency and response times. Delays in DHCP responses can indicate network congestion or server performance issues.
Event logs are another important source of diagnostic information. These logs record DHCP service events, including errors, warnings, and informational messages. By analyzing these logs, administrators can identify patterns and proactively address issues before they escalate.
In larger environments, centralized monitoring systems are often used to aggregate DHCP data from multiple servers. This provides a unified view of network health across the entire infrastructure.
Maintaining IP Address Integrity with IPAM Governance
IP Address Management introduces a governance layer that ensures IP infrastructure remains structured, consistent, and compliant with organizational policies. Unlike DHCP, which focuses on real-time assignment, IPAM focuses on long-term control and visibility.
One of the key governance functions of IPAM is tracking IP address utilization. It provides detailed reports on which addresses are in use, which are available, and which are reserved. This helps administrators optimize address allocation and prevent waste.
IPAM also enforces compliance by detecting unauthorized or out-of-policy IP configurations. For example, if a device is manually assigned an address outside the authorized range, IPAM can flag it as non-compliant.
Another important governance feature is historical tracking. IPAM maintains records of address assignments over time, allowing administrators to trace changes and identify patterns in network usage.
This historical data is particularly useful for troubleshooting and capacity planning. It helps organizations understand how their network is evolving and when expansion may be required.
IPAM Integration with Active Directory and DNS Infrastructure
IPAM does not operate in isolation. It integrates deeply with Active Directory and DNS systems to provide a complete view of network identity and configuration.
Through Active Directory integration, IPAM can identify which users and devices are associated with specific IP addresses. This enhances accountability and simplifies troubleshooting in environments with large numbers of devices.
DNS integration allows IPAM to map IP addresses to hostnames. This makes it easier to identify devices and understand network communication patterns. Instead of relying solely on numerical IP addresses, administrators can work with meaningful hostnames.
This integration also improves change tracking. When DNS records are updated, IPAM records the changes and links them to corresponding IP address updates.
Together, these integrations create a unified network intelligence system that combines addressing, naming, and identity into a single framework.
Role-Based Administration and Delegated IPAM Control
In large organizations, it is not practical for a single administrator to manage all IP-related tasks. IPAM supports delegated administration through role-based access control, allowing responsibilities to be distributed across teams.
Different roles can be assigned based on operational needs. For example, helpdesk staff may be granted read-only access to view IP assignments, while network engineers may have permissions to modify scopes and reservations.
Security administrators may have access to audit logs and compliance reports but not to configuration settings. This separation of duties helps maintain security while enabling operational efficiency.
Delegated control also reduces the risk of accidental misconfiguration. By limiting access to specific functions, organizations can ensure that only qualified personnel make critical changes.
Role-based administration is particularly important in regulated industries where network changes must be carefully controlled and audited.
Address Optimization and Long-Term IP Planning Strategies
Effective IP management is not only about current operations but also about long-term planning. As organizations grow, their IP infrastructure must scale accordingly.
Address optimization involves analyzing current usage patterns and identifying inefficiencies. IPAM provides insights into underutilized ranges, overallocated subnets, and fragmented address spaces.
By consolidating or reorganizing these ranges, administrators can improve efficiency and extend the lifespan of existing IP infrastructure.
Long-term planning also involves preparing for IPv6 adoption. While IPv4 remains dominant, IPv6 is increasingly important for modern network architectures. IPAM helps organizations manage both addressing schemes simultaneously.
Planning also includes forecasting future growth. By analyzing historical usage trends, administrators can predict when additional address space will be required and plan accordingly.
Troubleshooting Integrated DHCP and IPAM Environments
When DHCP and IPAM are integrated, troubleshooting becomes both more powerful and more complex. Issues may originate in DHCP configuration, IPAM synchronization, or network communication between services.
One common issue is data mismatch between DHCP and IPAM. This occurs when IPAM fails to synchronize with DHCP servers, resulting in outdated or incorrect address information.
To resolve this, administrators must verify service connectivity, check synchronization schedules, and ensure that credentials are properly configured.
Another issue is incomplete discovery. If IPAM fails to detect certain DHCP or DNS servers, it may indicate network segmentation issues or permission problems.
In such cases, administrators must verify firewall settings, network routes, and Active Directory permissions.
IP conflicts may also appear in integrated environments. While DHCP helps prevent conflicts, manually configured static addresses can still cause issues. IPAM helps identify these conflicts by comparing DHCP records with actual network usage.
Operational Best Practices for DHCP and IPAM in Windows Server
Maintaining a stable and efficient DHCP and IPAM environment requires consistent operational practices. Regular review of scope utilization ensures that address pools remain sufficient for network demand.
Consistent documentation of IP configurations helps maintain clarity across teams and reduces troubleshooting time. Changes to DHCP scopes or IPAM settings should always be recorded and reviewed.
Regular auditing ensures that unauthorized changes are detected early. This is especially important in environments with multiple administrators or delegated access.
Backup and recovery procedures must also be in place. DHCP and IPAM configurations should be backed up regularly to prevent data loss in case of system failure.
Finally, continuous training and awareness ensure that network administrators remain familiar with best practices and emerging technologies in IP management.
The Expanding Role of RAID in Modern Data Infrastructure
As storage demands continue to grow across industries, RAID systems have evolved far beyond simple disk grouping techniques. What began as a method to improve reliability and performance in early computing environments has become a foundational layer in enterprise storage architecture, cloud infrastructure, and large-scale data processing systems.
Modern RAID implementations are no longer just about combining disks. They are about managing risk, optimizing workload distribution, and ensuring data availability under extreme conditions. With the rise of big data, virtualization, and high-availability services, RAID has become deeply integrated into how storage systems are designed and maintained.
This final exploration of RAID concepts focuses on advanced design considerations, performance behavior under stress, rebuild dynamics, failure scenarios, and how RAID continues to adapt in contemporary storage environments.
Understanding Performance Trade-Offs Across RAID Levels
Every RAID level represents a deliberate trade-off between three major factors: performance, redundancy, and storage efficiency. These factors are often in conflict, and no single RAID level can maximize all three simultaneously.
RAID 0 prioritizes performance but offers no redundancy. RAID 1 prioritizes redundancy but sacrifices storage efficiency. RAID 5 and RAID 6 attempt to balance both but introduce computational overhead. Nested RAID configurations attempt to blend advantages but increase complexity and cost.
In real-world systems, choosing a RAID level is not about finding the “best” option but about selecting the most appropriate compromise for a specific workload.
For example, transactional databases require fast read/write performance and strong reliability, while archival systems prioritize storage efficiency and long-term durability over speed. Each of these environments demands a different RAID strategy.
Write Amplification and Its Impact on RAID Performance
One of the most important performance considerations in RAID systems is write amplification. This refers to the extra work required to complete a write operation beyond simply storing the new data.
In RAID 5 and RAID 6, write amplification occurs because parity must be recalculated every time data changes. This involves reading existing data, reading old parity, computing new parity, and writing both updated data and parity back to disk.
This multi-step process increases latency and reduces write throughput, especially in systems with frequent small writes. Over time, this can significantly impact performance in workloads such as database logging or virtual machine storage.
Even in RAID 10, write amplification exists due to mirroring. Every write must be duplicated across multiple disks. While this is simpler than parity calculations, it still doubles the write workload.
Understanding write amplification is essential when designing storage systems because it directly affects scalability and responsiveness under load.
RAID Rebuild Behavior and System Stress
When a disk fails in any RAID configuration, the system enters a rebuild phase. This is one of the most critical and vulnerable periods in the lifecycle of a RAID array.
During rebuild, the system must reconstruct lost data using either mirrored copies or parity calculations. This process consumes significant disk bandwidth and CPU resources, often reducing overall system performance.
In RAID 5, rebuild requires recalculating missing data from parity and remaining disks. In RAID 6, the process is even more complex due to dual parity recovery. In RAID 1, rebuild is simpler but still requires full data copying from the surviving disk.
The risk during rebuild is not just performance degradation but also increased vulnerability. In RAID 5, if another disk fails during rebuild, data loss can occur. RAID 6 reduces this risk by allowing a second failure, but rebuild times are still a critical factor.
As disk capacities increase, rebuild times have become longer. Large modern drives can take many hours or even days to fully rebuild, increasing the window of exposure to additional failures.
The Concept of Degraded Mode Operation
When a RAID system loses one or more disks but continues operating, it enters what is known as degraded mode. In this state, the system is functional but running without full redundancy.
In RAID 1, degraded mode means one mirror is missing. In RAID 5, one disk is unavailable, and parity is actively being used to reconstruct missing data on demand. In RAID 6, two disks may be missing, but the system can still operate using dual parity.
Degraded mode significantly reduces performance because every read or write operation may require additional calculations or disk access to reconstruct missing data.
Operating in degraded mode is inherently risky. While it allows continued access to data, it places additional strain on remaining disks, increasing the likelihood of further failures.
Nested RAID in Enterprise Storage Architecture
Nested RAID configurations combine multiple RAID levels to achieve more advanced performance and redundancy characteristics. These configurations are widely used in enterprise environments where neither simple mirroring nor basic parity is sufficient.
One of the most common nested configurations is RAID 10, which combines mirroring and striping. This provides both high performance and strong fault tolerance, making it ideal for mission-critical applications.
Another example is RAID 50, which combines RAID 5 and RAID 0. In this setup, multiple RAID 5 groups are striped together. This improves performance while maintaining parity-based redundancy within each group.
Similarly, RAID 60 combines RAID 6 and RAID 0, offering even greater fault tolerance by allowing multiple disk failures within each RAID 6 group.
These nested structures allow system designers to fine-tune storage behavior based on workload requirements. However, they also increase complexity, hardware requirements, and management overhead.
RAID Controller Role and Hardware vs Software Implementation
RAID can be implemented in hardware or software, and the choice significantly impacts performance and flexibility.
Hardware RAID uses a dedicated controller to manage disk operations, parity calculations, and data distribution. This offloads processing from the main system CPU and can improve performance, especially in high-throughput environments.
Software RAID, on the other hand, relies on the operating system to manage RAID logic. While this approach is more flexible and cost-effective, it consumes system resources and may not perform as efficiently under heavy workloads.
Modern systems often use hybrid approaches where software RAID is optimized with hardware acceleration features built into CPUs or storage controllers.
The choice between hardware and software RAID depends on budget, performance requirements, and system complexity.
Failure Domains and Risk Distribution in RAID Arrays
A failure domain refers to the scope of impact when a component in a system fails. In RAID systems, understanding failure domains is essential for designing resilient storage architectures.
In simple RAID arrays, all disks belong to the same failure domain. If multiple disks fail beyond the RAID level’s tolerance, data loss occurs.
In nested RAID systems, failure domains are more distributed. For example, in RAID 50, each RAID 5 group acts as a separate failure domain. A failure in one group does not necessarily affect others.
This segmentation improves resilience and reduces the risk of total array failure. However, it also requires careful planning of disk distribution and system layout.
The Impact of Disk Size Growth on RAID Reliability
As storage technology has advanced, individual disk capacities have increased dramatically. While this provides more storage per device, it also introduces new risks for RAID systems.
Larger disks take longer to rebuild after failure. This increases the time a system spends in degraded mode, raising the probability of a second failure during recovery.
Additionally, the amount of data that must be reconstructed increases with disk size, placing more strain on remaining drives.
This has led to a reevaluation of traditional RAID strategies in some environments, with increased emphasis on redundancy levels such as RAID 6 or nested RAID configurations that offer greater fault tolerance.
RAID and the Rise of Solid-State Storage
The introduction of solid-state drives (SSDs) has changed the performance dynamics of RAID systems. SSDs offer significantly faster read and write speeds compared to traditional mechanical drives, but they also behave differently in RAID environments.
In RAID 0 and RAID 10 configurations, SSDs can deliver extremely high performance due to parallel access. However, parity-based RAID levels such as RAID 5 and RAID 6 can experience increased write amplification, which affects SSD longevity due to wear from repeated write cycles.
Despite this, RAID remains relevant in SSD-based systems because it still provides redundancy and fault tolerance. The design focus shifts from mechanical failure to managing write endurance and maintaining performance consistency.
Data Consistency and RAID Integrity Mechanisms
Ensuring data consistency is a critical aspect of RAID systems. In complex configurations, especially those involving parity, there is always a risk of inconsistencies during power failures or unexpected shutdowns.
To address this, RAID systems often use mechanisms such as write-ahead logging, parity checks, and consistency checks during startup or rebuild operations.
These mechanisms ensure that parity information remains synchronized with data blocks and that any corruption can be detected and corrected.
Consistency checks are especially important in RAID 5 and RAID 6 systems, where parity calculations must remain accurate across all disks.
RAID in Virtualized and Cloud Environments
In modern computing environments, RAID is often implemented beneath layers of virtualization. Virtual machines and cloud storage systems rely on underlying RAID configurations to ensure data durability.
In these environments, RAID is not always visible to end users but plays a crucial role in maintaining system stability. Cloud providers often combine RAID with distributed storage systems that span multiple physical locations.
This adds additional redundancy layers beyond traditional RAID, creating highly resilient storage architectures capable of surviving hardware failures, network disruptions, and even data center outages.
The Evolution of RAID Thinking in Modern Storage Design
RAID is no longer viewed as a standalone solution but as part of a broader storage strategy. Modern systems integrate RAID with replication, erasure coding, distributed storage, and cloud-based redundancy models.
While traditional RAID focuses on disk-level redundancy, modern systems extend these principles across clusters, regions, and global infrastructures.
Despite these advancements, the core concepts of RAID—striping, mirroring, and parity—remain fundamental. They continue to influence how data is structured, protected, and accessed in virtually every storage system today.
Operational Risks, Monitoring, and RAID Decision Strategy in Real Systems
Beyond architecture and theoretical performance, RAID systems introduce ongoing operational responsibilities that significantly influence how storage behaves in production environments. One of the most overlooked aspects is continuous monitoring. RAID is not a “set and forget” technology; it requires active observation to ensure that disks remain healthy and that redundancy is intact.
Modern systems frequently monitor SMART (Self-Monitoring, Analysis, and Reporting Technology) attributes of disks to detect early warning signs of failure. Indicators such as rising bad sectors, increased read latency, or abnormal temperature fluctuations often precede actual disk failure. In RAID environments, identifying these early signals is critical because proactive replacement can prevent the system from entering degraded mode.
Another operational concern is the timing of disk replacement. In many enterprise environments, administrators do not wait for a full failure. Instead, they replace disks preemptively when risk thresholds are reached. This approach reduces the probability of multiple simultaneous failures, which is especially important in RAID 5 configurations where a second failure during rebuild can be catastrophic.
RAID also requires careful consideration of workload type. Sequential workloads, such as media streaming or large file transfers, benefit significantly from striping-based RAID levels. Random workloads, such as transactional databases or virtual machine environments, behave differently and may experience performance penalties in parity-heavy configurations due to frequent small writes and constant parity recalculations.
Caching layers further complicate RAID behavior. Many systems introduce write-back or write-through caching at the controller level. Write-back caching can dramatically improve performance by temporarily storing data in faster memory before committing it to disk. However, it introduces risk if power loss occurs before data is written permanently. To mitigate this, enterprise RAID controllers often include battery-backed or flash-backed cache protection mechanisms.
Another important operational factor is rebuild prioritization. During rebuild, systems must decide how to balance user workload against reconstruction speed. A faster rebuild reduces vulnerability but can degrade system performance. A slower rebuild maintains responsiveness but prolongs the risk window. This trade-off is often configurable, and administrators must tune it based on system criticality and workload demands.
Thermal behavior also plays a role in RAID stability. As multiple disks operate simultaneously under heavy load—especially during rebuild—heat generation increases. Elevated temperatures can accelerate hardware degradation and contribute to cascading failures in poorly ventilated environments. Proper cooling design is therefore an indirect but essential component of RAID reliability.
From a strategic perspective, RAID selection is increasingly influenced by lifecycle economics rather than just technical performance. Factors such as disk replacement cost, downtime tolerance, data criticality, and rebuild frequency all contribute to decision-making. In some cases, organizations may even prefer simpler RAID configurations combined with external replication strategies instead of highly complex nested RAID setups.
Ultimately, RAID remains a foundational but evolving concept. While newer storage technologies introduce distributed redundancy and cloud-based replication, the underlying principles of balancing performance, redundancy, and efficiency continue to shape how data systems are designed and maintained.
Conclusion
RAID has remained one of the most influential concepts in data storage because it directly addresses a problem that never goes away: how to store data efficiently while keeping it safe and accessible. Across all its levels and variations, RAID represents a set of design choices that balance speed, redundancy, and storage efficiency in different ways depending on system needs.
From the simplicity of RAID 0, which prioritizes performance through striping alone, to the reliability of RAID 1, which focuses on complete data duplication, the foundational ideas are straightforward but powerful. These early configurations demonstrate the core trade-offs that define all storage systems: faster access often comes at the cost of protection, while stronger protection often reduces usable capacity or performance.
As systems evolved, parity-based RAID levels such as RAID 3, RAID 4, RAID 5, and RAID 6 introduced more efficient ways to protect data without fully duplicating it. By using mathematical parity, these configurations reduced storage overhead while still allowing recovery from disk failures. However, they also introduced complexity, particularly in write performance and rebuild operations. The shift from dedicated parity to distributed parity in RAID 5 marked a major improvement in balancing workload and eliminating bottlenecks.
Advanced configurations like nested RAID further expanded flexibility by combining multiple RAID levels. These hybrid approaches allow systems to fine-tune performance and redundancy characteristics, making them suitable for demanding enterprise environments where workloads are diverse and failure tolerance is critical.
In modern storage ecosystems, RAID is no longer an isolated solution but part of a broader reliability strategy. It works alongside technologies like replication, distributed storage, and cloud redundancy to ensure data durability across multiple layers. Despite the rise of newer storage architectures, RAID continues to play a crucial role at the hardware and system level.
What makes RAID especially enduring is its adaptability. Whether used in small-scale systems for basic redundancy or in large data centers for high availability, the underlying principles remain relevant. Understanding RAID is not just about memorizing levels; it is about understanding how systems manage risk, performance, and capacity under real-world constraints.
As storage demands continue to grow, RAID will continue to evolve, but its core ideas will remain central to how data is protected and accessed in computing environments.