The world of networking has changed dramatically over the last decade. What was once considered a field centered mainly on cables, switches, routers, and manual configuration now includes software development, scripting, automation platforms, analytics, and cloud-based infrastructure. Organizations depend on stable, secure, and scalable networks more than ever before. Every business function, from communication and sales to manufacturing and customer support, now relies on digital systems that must remain connected at all times. Because of this dependence, network professionals are expected to move faster, solve problems more efficiently, and manage increasingly complex environments with greater precision.
Traditional networking methods often involved logging in to devices one at a time, checking settings manually, copying configurations, and responding to issues only after users reported them. This approach worked reasonably well when networks were smaller and less dynamic. However, modern environments may include hundreds or thousands of devices spread across branch offices, remote locations, data centers, and cloud platforms. Managing such scale manually is not only slow, but also prone to human error.
As networks grow larger, even simple tasks become difficult when repeated many times. Updating passwords, checking interface status, validating routing tables, collecting logs, or confirming software versions across dozens of devices can consume hours or even days when performed manually. This creates delays, increases operational costs, and leaves less time for strategic improvements. Organizations now seek ways to reduce repetitive tasks while improving reliability. That need has accelerated the rise of network automation.
Automation in networking means using software tools and scripts to perform tasks that previously required manual effort. Instead of typing the same commands into multiple devices, engineers can write logic once and apply it consistently across the environment. Instead of waiting for failures to become visible, systems can continuously monitor device health and alert teams automatically. Instead of guessing configuration drift, tools can compare live states against intended standards.
This shift does not eliminate the need for network engineers. On the contrary, it increases the value of professionals who understand both networking principles and automation methods. Engineers are no longer expected only to configure devices; they are expected to design efficient processes, improve resilience, and make infrastructure more intelligent. Those who learn automation become capable of handling larger responsibilities with greater impact.
Among the technologies supporting this transformation, Python has emerged as one of the most practical and widely adopted programming languages for infrastructure work. Its readable syntax, broad library ecosystem, and strong community support make it especially suitable for engineers entering software-driven operations. Within the Python ecosystem, libraries designed specifically for network interaction have become essential. One such tool is Scrapli, which enables structured communication with network devices through command-line interfaces.
Understanding tools like Scrapli offers a glimpse into how networking is evolving. It represents the meeting point between traditional device management and modern automation practices. By learning how such tools function, engineers can better adapt to current demands and prepare for the future of infrastructure management.
Why Network Automation Became a Necessity
Many technological trends begin as experiments. Automation in networking followed a similar path. Early adopters often used scripts for simple tasks such as backing up configurations or checking uptime. At first, these efforts were viewed as optional conveniences rather than core operational practices. Over time, however, business expectations changed. Networks became more complex, remote work increased, cloud integration expanded, and service availability became critical around the clock. Under these conditions, automation stopped being optional.
One major reason automation became necessary is scale. Even midsize organizations may operate dozens of network devices, wireless controllers, firewalls, VPN endpoints, and cloud gateways. Larger enterprises manage thousands. Manual administration does not scale effectively because every repeated task consumes human time. If a team must check the same setting across 300 devices, the process quickly becomes inefficient.
Another reason is consistency. Human beings naturally make mistakes, especially when repeating tedious procedures. A missed command, incorrect IP address, forgotten save operation, or typo in an access list can create outages or security gaps. Automation helps enforce consistency because the same logic can be applied identically each time. When designed carefully, scripts reduce variability and support predictable results.
Speed is equally important. Businesses expect rapid deployment of new services, branch expansions, wireless changes, policy updates, and security responses. Manual workflows often create bottlenecks because tasks must wait for engineer availability. Automated processes can gather information or perform predefined changes in minutes rather than hours. This speed directly affects productivity and competitiveness.
Visibility also drives automation adoption. Many organizations do not fail because devices are broken; they fail because teams lack timely insight into what devices are doing. Interface flaps, rising error counts, mismatched configurations, routing anomalies, or memory pressure may exist long before users complain. Automated data collection enables proactive management. Engineers can identify trends, detect early warning signs, and respond before disruption spreads.
Staffing pressures add another layer. Skilled network engineers are valuable, but their time is limited. When experienced professionals spend hours on repetitive checks, they are unavailable for architecture, optimization, security planning, or mentoring. Automation allows teams to redirect effort toward higher-value work. Instead of replacing expertise, it amplifies expertise.
Compliance requirements have also increased. Many industries must prove that systems meet security and operational standards. Auditing device settings manually is difficult and unreliable. Automated checks can compare live configurations against approved baselines and generate evidence efficiently. This reduces risk and supports governance needs.
Finally, hybrid infrastructure changed everything. Networks no longer live solely inside one building or data center. Organizations now blend physical offices, remote users, cloud services, SaaS platforms, and edge devices. Coordinating these environments requires flexible tools that can gather data from many systems quickly. Automation became the practical answer.
These pressures explain why network automation continues to expand. It is not simply a trend driven by novelty. It solves real operational problems created by modern infrastructure demands.
Python as the Language of Practical Infrastructure
When engineers begin exploring automation, one of the first decisions involves choosing a programming language. Many languages can technically perform automation tasks, but Python became especially popular in infrastructure teams because it balances power with accessibility. For professionals whose primary background is networking rather than software engineering, this matters greatly.
Python is known for readability. Its syntax is relatively clean, which means scripts often resemble logical instructions rather than dense technical code. This lowers the barrier for newcomers. A network engineer can begin by automating small tasks such as reading device output, renaming files, or parsing logs without needing years of software experience.
The language also has excellent support for data handling. Networking increasingly involves structured data such as JSON, YAML, CSV, XML, and API responses. Python includes built-in tools and third-party libraries that make it easier to work with these formats. Engineers can transform raw outputs into useful reports, dashboards, or alerts with comparatively little effort.
Another strength is community adoption. Because many infrastructure teams use Python, a vast amount of documentation, examples, tutorials, and open-source tools exist. This ecosystem reduces learning friction. Engineers often find that a common challenge has already been addressed by others, saving time and effort.
Python is also cross-platform. Scripts can run on Windows, Linux, or macOS, which is useful for teams with mixed environments. Whether someone works from a laptop, server, or automation platform, Python typically fits without major barriers.
From a networking perspective, Python bridges old and new worlds. It can interact with modern APIs offered by cloud services and controllers, but it can also communicate with traditional command-line devices through SSH or similar methods. This flexibility is essential because many organizations operate both legacy and next-generation systems simultaneously.
Importantly, Python encourages gradual adoption. Engineers do not need to become full-time developers overnight. They can start with one useful script, then improve it over time. A script that checks interface status today might later include logging, email alerts, scheduled execution, and dashboard integration. Skills grow through practical use.
For teams managing networks, Python often becomes less about coding theory and more about problem solving. It enables engineers to express logic: gather this information, compare these values, alert if thresholds are exceeded, generate this report, or validate that policy exists everywhere. That practical orientation is why Python remains highly relevant in automation journeys.
Within this ecosystem, libraries tailored to networking simplify even more of the work. Rather than building device communication from scratch, engineers can use specialized tools that understand authentication, sessions, prompts, and command execution. Scrapli is one of those tools, designed specifically to streamline communication with network devices.
Understanding Scrapli in a Real-World Context
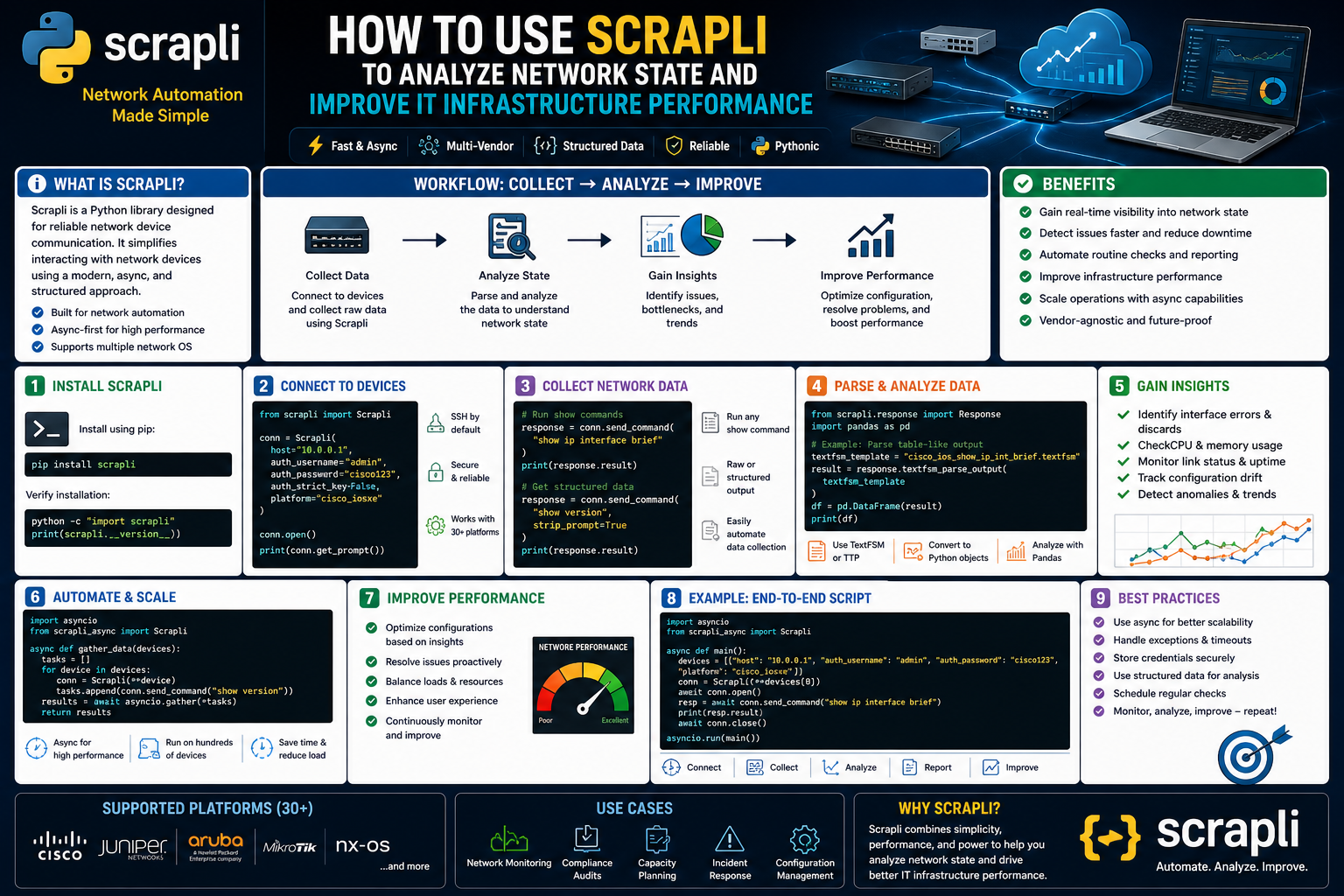
Scrapli is a Python library built to interact with network devices through command-line interfaces. Many routers, switches, and similar platforms still rely heavily on CLI-based management. Even when newer APIs exist, command-line access often remains the most familiar and universally available method for engineers. Scrapli recognizes this reality and provides a structured way to automate those interactions.
At a basic level, Scrapli establishes a connection to a device, authenticates using credentials, sends commands, and returns the resulting output. While that may sound simple, reliable device communication involves many details. Prompts differ between vendors. Session behavior varies. Timing issues occur. Authentication methods may change. Output formatting can be inconsistent. Scrapli helps manage these complexities so engineers can focus on useful tasks instead of low-level connection handling.
The library supports multiple platforms and vendors, making it practical in mixed environments. Many organizations do not standardize on a single network brand. They may operate equipment from several manufacturers due to mergers, budget decisions, specialized requirements, or historical growth. A tool that works across platforms becomes valuable because it reduces fragmentation in automation workflows.
Scrapli is often appreciated for being lightweight and efficient. It aims to provide straightforward connectivity without unnecessary overhead. For engineers building scripts to gather state information, run checks, or validate devices, that simplicity can be an advantage.
Another important concept is driver-based interaction. Different device types may require slightly different handling, so Scrapli uses drivers tailored to platforms. This allows scripts to interact more naturally with supported systems. Rather than forcing one generic method onto every device, it adapts to expected behaviors.
In practical terms, Scrapli is useful whenever engineers need repeatable access to device command output. That includes checking interface status, reviewing routes, examining neighbors, verifying software versions, collecting inventories, confirming policies, or troubleshooting incidents. Because command outputs often contain operational truth, automating access to them creates immediate value.
Scrapli also fits well in broader workflows. Data collected from devices can feed monitoring systems, inventory databases, change validation pipelines, or reporting tools. A script may use Scrapli only for connectivity, while the larger process handles analytics or orchestration.
For engineers transitioning from manual CLI work, Scrapli can feel intuitive. Instead of abandoning familiar commands, they leverage existing knowledge programmatically. Commands they already trust can be executed at scale through software. This lowers resistance to automation because learning starts from known territory.
The broader significance of Scrapli is that it demonstrates how legacy operational methods and modern automation can coexist. Many networks cannot instantly move to entirely API-driven architectures. Tools that automate CLI access help organizations progress now, using the infrastructure they already have.
The Meaning of Network State
To understand why a tool like Scrapli matters, it helps to define network state clearly. Network state refers to the current condition of devices, interfaces, protocols, services, and paths that make up the network. It answers the question: what is happening right now?
At the simplest level, network state can mean whether something is up or down. Is an interface operational? Is a router reachable? Is a switch forwarding traffic? These binary checks remain important because outages still begin with unavailable components.
However, modern network state goes far beyond simple availability. A link may be up but saturated with traffic. A routing protocol may be established but unstable. CPU usage may be high enough to threaten performance. Error counters may indicate failing cables or optics. Wireless clients may connect but experience poor quality. Security policies may exist but not match intended standards.
State also includes relationships. Which devices are neighbors? Which routes are preferred? Which VLANs exist on which trunks? Which access points serve which clients? Which tunnels are active? Understanding relationships often matters more than isolated metrics.
Another layer involves drift. A network may function today while silently diverging from approved design. Someone may change an access list, disable logging, alter spanning tree settings, or modify NTP sources. The network remains “up,” yet risk increases. State analysis helps detect these hidden deviations.
Time matters as well. Network state is dynamic. Conditions change minute by minute as users connect, traffic patterns shift, updates occur, and failures emerge. Therefore, one-time checks are useful but insufficient. Repeated observation reveals trends and intermittent issues.
From an operations standpoint, state awareness enables smarter decisions. Instead of troubleshooting blindly after complaints, engineers can compare current conditions with historical norms. Instead of guessing whether a change succeeded, they can validate resulting state. Instead of reacting to complete failure, they can intervene during early degradation.
This is where automation becomes powerful. Collecting network state manually from many devices is slow and inconsistent. Automated tools can retrieve data rapidly, repeatedly, and in standardized formats. Scrapli helps make that collection process efficient by communicating directly with devices.
Understanding network state is ultimately about visibility. Networks become easier to trust when teams can clearly see their real condition rather than assume it.
Building Practical Network Visibility Through Automated Observation
Knowing that a network exists is very different from understanding how it behaves. Many organizations operate environments that appear healthy on the surface because users can access core services most of the time. Yet beneath that surface, hidden problems may be growing quietly. Interfaces may be accumulating errors, routing paths may be changing unexpectedly, devices may be running low on memory, or unauthorized changes may have altered security posture. These conditions often remain unnoticed until performance drops or outages occur. This is why network visibility has become one of the most important goals of modern operations.
Visibility means more than seeing a dashboard with green indicators. Real visibility involves understanding the real-time condition of devices, links, services, and dependencies across the infrastructure. It includes knowing what has changed, what is unstable, what is overloaded, and what no longer matches intended design. Achieving this level of awareness manually is difficult, especially in growing environments where engineers manage many locations and technologies simultaneously.
Automation changes this situation by allowing systems to observe the network continuously and consistently. Instead of relying on occasional manual checks, engineers can use tools that gather operational data regularly. Scrapli is especially useful in this context because many devices still expose their most valuable operational information through command-line interfaces. Rather than replacing those familiar commands, automation enables them to be used at scale.
When engineers log in manually to inspect a router or switch, they usually run commands that reveal status. They may check interfaces, routes, neighbors, logs, software versions, uptime, spanning tree states, or CPU usage. These same commands can be executed programmatically through an automated workflow. The difference is not the information itself, but the speed, frequency, and consistency of collection.
For example, imagine an environment with eighty branch routers. Manually checking WAN interface health across all of them would consume substantial time. Even if done carefully, results might already be outdated by the time the last device is reviewed. With automation, the same task can happen quickly and repeatedly. Engineers gain a near-current picture of branch connectivity without exhausting valuable hours.
Visibility also improves when outputs are normalized. Human readers can interpret device text, but comparing many outputs manually is difficult. Automated processes can convert command results into structured records, making trends easier to analyze. Instead of scanning pages of text, engineers can identify which devices have changed, which interfaces are unstable, or which sites are approaching capacity.
Another advantage is consistency of timing. Human checks usually occur only when someone remembers, has time, or notices symptoms. Automated observation can run on schedules. Morning checks, hourly checks, or triggered checks after changes provide predictable insight. This regular cadence often reveals patterns that isolated troubleshooting sessions would miss.
In many organizations, operational maturity begins not with advanced artificial intelligence or complex orchestration, but with reliable visibility. Teams first need trustworthy awareness of their network state. Scrapli can support that journey because it helps engineers gather the raw truth directly from devices already in production.
Using Existing CLI Knowledge as an Automation Advantage
One reason many network engineers hesitate to begin automation is the assumption that they must abandon familiar methods and start from zero. In reality, one of the strongest advantages engineers already possess is deep command-line knowledge. Years of troubleshooting often build intuition around which commands reveal useful information. That expertise becomes even more valuable when paired with automation tools.
Experienced professionals know where truth lives inside device outputs. They understand which command exposes interface flaps, which one confirms routing convergence, which one reveals environmental alarms, and which one uncovers neighbor instability. This knowledge cannot be replaced by a script alone. Automation becomes most effective when it captures and scales human expertise.
Scrapli aligns naturally with this mindset because it works through command-line interactions. Engineers do not need to discard the operational habits they trust. Instead, they can translate those habits into repeatable workflows. A command once typed manually during an outage can become part of a daily health check. A sequence once used for change validation can become a post-maintenance routine executed every time.
This reduces the emotional barrier to learning automation. Instead of seeing programming as something separate from networking, engineers begin to see it as a way to amplify what they already know. The command remains familiar; only the execution model changes. Rather than logging into one device, the same logic can inspect fifty. Rather than remembering to check after each change, the process runs automatically.
Another benefit of reusing CLI expertise is trust. Teams are often cautious about new systems that produce unclear results. But when automation uses commands engineers already recognize, outputs feel credible. If a script checks interface status using the same command an engineer would use manually, confidence grows faster. Adoption tends to increase when tools feel transparent rather than mysterious.
This approach also helps with team collaboration. Senior engineers who may not consider themselves programmers often possess valuable operational wisdom. Junior engineers may have stronger coding backgrounds but less device intuition. Combining these strengths creates powerful results. One person identifies meaningful checks, another helps automate them, and both contribute to a more capable operations model.
Even as APIs and controller-based systems expand, CLI knowledge remains relevant. Many environments still contain devices where command-line access is the primary or most practical management method. Hybrid infrastructures may mix legacy hardware with modern platforms. Engineers who can automate across both worlds gain flexibility.
The transition to automation becomes easier when framed correctly. It is not a rejection of established expertise. It is a method for multiplying that expertise across time, scale, and consistency. Scrapli often serves as a bridge because it allows existing operational intelligence to be expressed in software without forcing teams to start from unfamiliar ground.
Detecting Small Problems Before They Become Major Outages
Some of the most disruptive outages do not begin dramatically. They start as small signals that go unnoticed. A rising number of CRC errors on an uplink may indicate a failing cable. A memory leak may slowly reduce available resources over weeks. A route flap may occur intermittently before becoming constant. A fan warning may appear long before hardware shutdown. These early indicators are easy to miss in busy environments.
Manual operations often prioritize visible emergencies. If users are productive and major services respond, teams naturally focus elsewhere. The challenge is that subtle warnings continue developing in the background. By the time symptoms become obvious, remediation is harder and impact is larger.
Automated state analysis helps catch these early signs. When devices are checked regularly, even small deviations become visible. A script can note that interface errors increased since yesterday, that CPU levels remain above normal for several runs, or that a tunnel repeatedly reconnects overnight. Individually these issues may seem minor, but together they provide advance notice.
Scrapli supports this model by enabling consistent retrieval of device data that contains such indicators. Many operational commands reveal counters, resource usage, timestamps, logs, and protocol conditions. Automation can gather these details and compare them over time. Engineers no longer depend solely on memory or ad hoc spot checks.
Trend analysis becomes especially valuable. A single reading may not matter, but repeated measurements tell a story. If latency rises gradually each week, if wireless associations fail more often after office hours, or if route convergence slows after every maintenance window, patterns emerge only through ongoing observation.
Early detection also improves planning. If branch devices are nearing capacity, teams can budget upgrades before performance suffers. If environmental temperatures rise seasonally in a wiring closet, cooling improvements can be scheduled proactively. If recurring configuration drift appears after contractor work, change processes can be tightened.
Security benefits as well. Operational anomalies sometimes reflect unauthorized or accidental changes. Unexpected new neighbors, disabled logging, altered access rules, or unexplained interface state changes may signal deeper concerns. Automated checks can highlight these deviations quickly.
There is also a psychological benefit for operations teams. Constant firefighting creates stress and burnout. When teams gain tools that surface issues earlier, work becomes more deliberate and less reactive. Engineers spend more time preventing incidents and less time recovering from them.
No system can prevent every outage. Hardware fails, providers experience disruptions, and mistakes still happen. But many incidents become less severe when warning signs are recognized early. Automated network state analysis turns scattered clues into actionable awareness, allowing organizations to respond while options remain open.
Turning Raw Device Output Into Actionable Insight
One of the most common misunderstandings about automation is believing that collecting data alone solves problems. In reality, raw information is only the first step. Device outputs often contain valuable details, but unless those details are interpreted, prioritized, and connected to operational goals, they remain noise. The true value lies in transforming raw output into insight.
Traditional CLI outputs were designed primarily for human reading. They display lines of text containing counters, statuses, identifiers, timestamps, and technical messages. Skilled engineers can interpret this information quickly when focused on one device. The challenge appears when data arrives from dozens or hundreds of devices simultaneously. Human attention becomes the bottleneck.
Automation helps by converting outputs into usable signals. For example, instead of storing pages of interface text, a workflow can identify only interfaces that are down unexpectedly, exceeding errors, or operating near capacity. Instead of collecting entire routing tables, it can flag missing critical routes or unexpected next hops. Instead of reviewing all logs, it can isolate repeated failures or recent critical events.
This filtering matters because operations teams need relevance, not endless data dumps. If every automated task creates more clutter, adoption suffers. Effective state analysis reduces noise and highlights what deserves attention.
Another important step is contextual comparison. Many metrics mean little in isolation. High CPU during backup windows may be normal, while the same CPU during business hours may be alarming. A link at ninety percent utilization may be acceptable for one circuit and dangerous for another. Good automation considers context such as device role, schedule, historical baseline, or expected design.
Scrapli can act as the collection layer in these workflows. It retrieves the operational truth from devices, while surrounding logic interprets the results. This separation is useful because connectivity and analysis can evolve independently. Teams may refine thresholds, reporting, or dashboards without changing how data is gathered.
Visualization often follows interpretation. Once data is structured, it can feed dashboards, summaries, or reports. Leaders may want service-level views, while engineers need detailed technical indicators. Both can originate from the same automated collection process, tailored for different audiences.
Documentation quality improves too. Many environments suffer from outdated inventories or unclear records. Automated state collection can verify hostnames, versions, serial details, interfaces, and neighbors directly from devices. This helps maintain living documentation rather than static spreadsheets forgotten after creation.
Insight also supports better change management. Before and after maintenance windows, teams can compare device state. Did routing neighbors return? Did interface descriptions remain intact? Did policy counts change unexpectedly? Rather than relying on guesswork, engineers validate results using evidence.
Ultimately, collecting information is easy. Creating clarity is harder. The strongest automation practices focus not on gathering everything possible, but on extracting what matters most. That is how raw device outputs become operational intelligence.
The Role of Standardization in Reliable Operations
As organizations grow, one hidden source of instability is inconsistency. Different sites may use different naming conventions. Similar devices may run different software releases. Interface descriptions may vary widely. Authentication settings may drift. Logging destinations may differ by region or by whoever last configured the device. These inconsistencies create friction during troubleshooting and increase risk during change execution.
Standardization is the process of defining and maintaining consistent patterns across infrastructure. It does not mean every environment must be identical, but it means common elements should behave predictably. Automation greatly strengthens this effort because it can check actual device state against expected standards repeatedly.
Without automation, standardization often depends on memory, documentation, and occasional audits. These methods rarely scale well. Busy teams may intend to align devices but postpone reviews. New deployments may follow current standards while older locations remain untouched. Over time, drift accumulates quietly.
Scrapli can support standardization by helping gather the current state of devices quickly. Engineers can inspect whether logging is enabled everywhere, whether time synchronization sources are correct, whether management interfaces use approved settings, or whether software versions meet baseline policy. Once visibility exists, remediation becomes easier to plan.
Standardization also improves incident response. When devices share common structures, engineers waste less time figuring out unique quirks during emergencies. If naming conventions are consistent, locating interfaces is faster. If authentication methods are uniform, access issues are reduced. If monitoring thresholds are standardized, alerts become more meaningful.
Training benefits as well. New team members onboard faster when environments follow predictable patterns. Instead of learning ten different ways to configure similar systems, they learn one approved approach with documented exceptions. This lowers mistakes and builds confidence.
Security posture often depends heavily on consistency. In many breaches or near misses, the issue is not that standards were absent, but that they were applied unevenly. One forgotten device with weak credentials or missing logging can create outsized risk. Automated checks help identify such gaps before they are exploited.
Standardization should be practical rather than rigid. Environments sometimes require legitimate differences based on geography, hardware capability, or business function. Good governance distinguishes between approved exceptions and accidental drift. Automation can document both.
Another overlooked advantage is smoother modernization. Organizations planning migrations, cloud integration, or controller adoption often struggle because legacy environments are chaotic. Standardizing first creates cleaner foundations for future change. Data is easier to trust, dependencies easier to map, and rollout strategies easier to execute.
Reliable operations rarely emerge from heroics alone. They emerge from repeatable systems where expected conditions are clear and deviations are visible. Standardization, reinforced by automated state checks, is one of the most effective ways to build that reliability over time.
Making Network Teams More Strategic
A common frustration in infrastructure teams is spending most of the week on tasks that feel necessary but low value. Engineers may repeatedly check device health, gather the same logs, confirm similar statuses, update records manually, or respond to avoidable alerts. These activities matter, but when they dominate schedules, strategic work gets delayed.
Strategic work includes architecture improvement, resilience planning, security enhancement, lifecycle upgrades, documentation cleanup, mentoring, and process redesign. These efforts often produce the largest long-term gains, yet they require uninterrupted attention that reactive workloads rarely allow.
Automation helps rebalance this equation. By reducing repetitive effort, teams reclaim time for higher-impact initiatives. Scrapli contributes by automating a category of work many engineers know well: gathering device state through CLI interaction. If health checks, inventories, and routine validations happen automatically, human attention can shift elsewhere.
This does not mean engineers become less hands-on. Rather, their hands-on time becomes more valuable. Instead of logging into thirty devices to confirm routine status, they can investigate why a recurring pattern exists at all. Instead of manually compiling upgrade readiness lists, they can design a safer lifecycle process. Instead of reacting to every symptom, they can strengthen root causes.
Morale often improves when teams feel progress rather than endless maintenance. Talented professionals usually want to solve meaningful problems and develop new skills. When every day is consumed by repetitive tasks, engagement declines. Automation can create room for growth and innovation.
Leadership benefits too. Managers gain more predictable operations and clearer capacity planning when manual workloads shrink. Rather than relying on constant overtime or informal heroics, teams operate through sustainable systems. This supports retention and reduces burnout.
Strategic maturity also affects how the business perceives the network team. If the group is known only for fixing outages after they occur, it may be viewed as reactive support. If the group delivers reliable data, faster deployments, stronger resilience, and proactive improvements, it becomes a trusted partner in business progress.
Importantly, the journey does not require massive transformation at once. Even small automations create leverage. A daily device summary, an interface drift report, or an automated version inventory can save hours each month. Those hours compound into larger opportunities.
Technology continues to accelerate, and expectations on infrastructure teams will likely keep rising. The teams that thrive will not be those who simply work harder. They will be those who design smarter operating models where expertise is amplified through automation and guided toward strategic outcomes.
Growing From Simple Scripts to Mature Network Operations
Many engineers assume automation must begin with a large project, expensive platforms, or advanced software skills. In reality, most successful automation journeys start small. A single useful task, repeated often enough, can justify the effort immediately. In network operations, even modest improvements save time, reduce mistakes, and create momentum for larger changes later.
A practical starting point is routine visibility. Teams often check the same information every day: interface status, device reachability, uptime, routing neighbors, software versions, or hardware alarms. These checks are necessary, but repeating them manually consumes valuable time. By using a tool such as Scrapli, engineers can automate collection of this data while keeping the familiar command-line workflows they already understand.
Once basic checks are automated, the next stage is reliability. A useful script should not depend entirely on one person remembering to run it. Mature operations improve simple scripts by scheduling them regularly, storing results, and alerting the right people only when attention is required. This changes automation from a personal convenience into a team capability.
Documentation often improves at the same time. Many organizations struggle with outdated records because network environments change faster than spreadsheets or manuals are updated. Automated data gathering can refresh inventories continuously. Device names, software releases, interfaces, neighbors, and hardware details can be validated directly from live systems rather than guessed from old notes. Accurate records reduce confusion during incidents and speed up decision-making.
Building Confidence Through Repeatable Processes
One of the biggest benefits of automation is consistency. Human beings naturally vary from day to day. People become tired, distracted, rushed, or interrupted. Even highly skilled engineers can overlook details when performing repetitive work. Software, when designed correctly, performs the same logic every time.
This consistency is especially valuable during maintenance windows and operational changes. Before a planned change, teams can automatically gather the current state of devices and services. After the change, the same checks can run again to confirm that important functions remain healthy. Instead of relying only on quick spot checks, engineers compare evidence before and after implementation.
Confidence grows when teams see predictable results. If automated checks repeatedly detect issues early, validate successful changes, or save hours of manual work, trust in the process increases. That trust matters because many organizations hesitate to automate critical environments until they feel sure the outputs are dependable.
Repeatable processes also improve collaboration. When health checks exist only in one engineer’s memory, operations become fragile. If that person is unavailable, knowledge gaps appear immediately. Automation helps convert personal habits into shared workflows the whole team can use. This reduces dependence on individual heroes and strengthens operational resilience.
Using Data to Make Better Decisions
Networks generate enormous amounts of operational information, but raw data alone has limited value. The real advantage comes from using that information to guide decisions. Once automated collection becomes normal, teams can compare historical trends, identify recurring weak points, and prioritize upgrades more intelligently.
For example, repeated interface errors may indicate aging cabling. Memory pressure across a group of devices may justify hardware replacement sooner than expected. Frequent instability at one branch may reveal provider issues rather than internal faults. Instead of relying on assumptions, engineers can act based on evidence.
Capacity planning also becomes stronger. Many organizations only react when users complain about slowness. Historical utilization patterns help teams recognize growth early and prepare before service quality declines. This proactive approach is usually less expensive and less disruptive than emergency expansion.
Leadership teams benefit as well. Clear operational reports based on real device state help explain risks, justify budgets, and support project planning. Technical teams often know where problems exist, but decision-makers need visible evidence. Automated reporting helps bridge that gap.
Preparing for the Future of Networking
The future of networking will likely involve more cloud integration, more distributed users, stronger security expectations, and faster service delivery demands. At the same time, many organizations will continue running traditional routers, switches, and firewalls for years. This means hybrid environments will remain common.
Tools like Scrapli are valuable because they help bridge old and new operational models. Engineers can automate current infrastructure today while gradually adopting newer management methods over time. There is no need to wait for a complete technology refresh before improving efficiency.
Learning automation also develops broader professional skills. Engineers begin thinking in systems, workflows, validation logic, and scalable design rather than isolated manual tasks. These habits remain useful regardless of future platforms or vendors. The specific tools may evolve, but the mindset of repeatability and intelligent operations will remain highly relevant.
Another future advantage is adaptability. Organizations frequently change direction through growth, mergers, remote work expansion, security requirements, or cloud migration. Teams that already use automation can usually respond faster because they have processes for gathering data, enforcing standards, and implementing repeatable actions.
Conclusion
The shift toward network automation reflects a broader transformation in how modern infrastructure is designed, operated, and maintained. As networks continue to grow in size and complexity, manual methods alone can no longer provide the speed, accuracy, or consistency that organizations require. Automation introduces a structured way to manage this complexity by reducing repetitive tasks, improving visibility, and enabling faster response to operational changes.
Tools like Scrapli play an important role in this evolution by allowing engineers to interact with network devices using familiar command-line methods while applying the power of Python-based automation. This combination helps bridge the gap between traditional networking skills and modern software-driven operations, making it easier for professionals to adopt automation without losing their foundational expertise.
As engineers move from manual checks to automated workflows, they gain more than efficiency—they gain insight. Continuous monitoring of network state helps identify issues earlier, maintain consistency across devices, and support better decision-making. Over time, this leads to more stable systems and more strategic use of engineering effort.
Ultimately, automation is not about replacing network engineers but empowering them to work at a higher level, focusing on design, optimization, and long-term resilience rather than repetitive operational tasks. It enables faster decision-making, reduces human error, improves consistency, and allows engineers to dedicate more energy toward innovation and strategic infrastructure improvements.