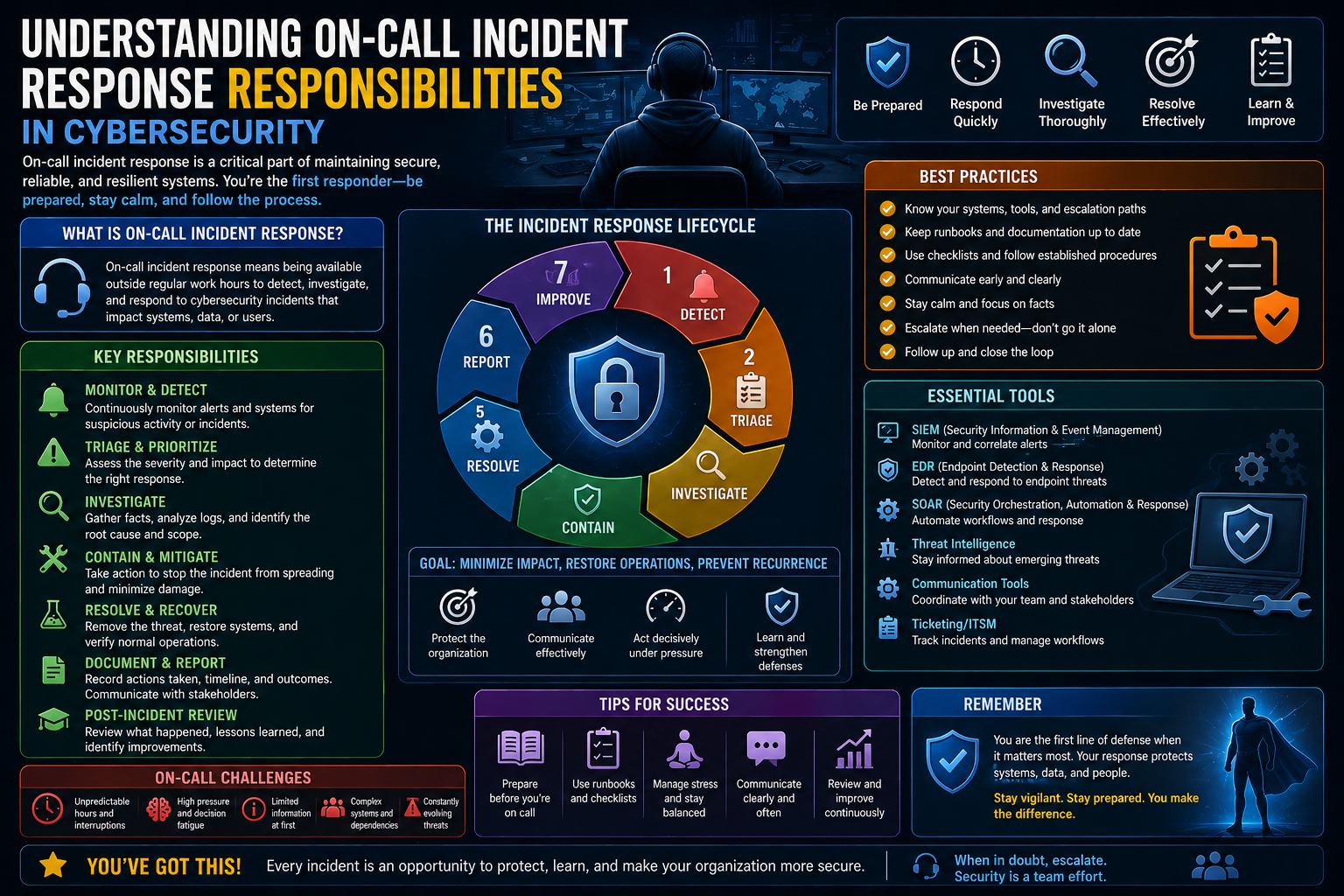
Incident response is a core discipline within modern network security because organizations today operate in environments where systems are constantly exposed to threats, misconfigurations, and operational failures. Whether an organization is running internal enterprise infrastructure, cloud-based services, or hybrid environments, the stability of its digital operations depends on how effectively it can detect, manage, and resolve incidents.
At its foundation, incident response is not only about reacting to cyberattacks. It also includes handling service disruptions, system failures, unauthorized access attempts, and unexpected behavior in applications or infrastructure. These events can directly affect business continuity, customer trust, and financial stability. Even a short disruption in a critical service can lead to cascading effects across departments and customers.
Network security plays a particularly important role because many incidents originate or spread through interconnected systems. A compromised endpoint, for example, can quickly become a gateway into broader infrastructure if not contained. Similarly, misconfigured network rules or firewall policies can unintentionally expose sensitive systems. Incident response ensures that such issues are not only addressed but also analyzed to prevent recurrence.
In professional environments, incident response is structured, meaning it follows predefined processes rather than improvised reactions. These processes define how alerts are evaluated, how severity is determined, and how teams collaborate during high-pressure situations. Without structure, response efforts can become chaotic, leading to delays, miscommunication, or incomplete resolution.
The increasing complexity of IT systems has made incident response more important than ever. With cloud computing, remote work, distributed applications, and third-party integrations, the number of potential failure points has expanded significantly. As a result, organizations must rely on skilled professionals who understand both the technical and procedural aspects of responding to incidents effectively.
How On-Call Fits Into Operational Security Models
On-call responsibilities are a key operational mechanism used to ensure that incident response capabilities are available outside standard working hours. In many organizations, IT systems operate continuously, but staffing every hour of the day with full teams is not always practical. On-call models bridge this gap by assigning responsibility to designated individuals who can respond when incidents occur.
Within operational security models, on-call functions as an extension of the incident response framework. It ensures that when alerts are triggered—whether during business hours or in the middle of the night—there is always someone responsible for initial assessment and action. This structure is particularly important for services that require high availability or have strict uptime expectations.
On-call integration also supports distributed responsibility. Instead of centralizing all incident handling within a single group, responsibilities are shared across teams or specialties. For example, network engineers may handle connectivity issues, while system administrators manage server failures, and security analysts focus on potential breaches. This distribution improves efficiency and ensures that incidents are handled by individuals with relevant expertise.
Operational models typically define clear rules for how on-call engagement works. These include response time expectations, communication channels, and escalation rules. When properly implemented, on-call systems reduce the time between incident detection and initial response, which is critical for minimizing impact.
However, on-call is not just a technical arrangement. It is also an organizational commitment. It requires coordination between teams, proper training, and clearly defined responsibilities. Without these elements, on-call systems can become ineffective, leading to delays in response or confusion during critical events.
Understanding What Triggers an Incident Response
Not every system alert or user complaint qualifies as an incident requiring full response activation. Organizations define specific criteria to determine when an incident response process should be initiated. These criteria are usually based on business impact, severity, and urgency rather than technical issues alone.
A minor issue affecting a single user may not require escalation if it does not impact broader operations. However, if the same issue affects a critical system or multiple users, it may escalate into a high-priority incident. The distinction lies in understanding how much disruption the issue causes to essential business functions.
Triggers for incident response can include system outages, performance degradation, data integrity issues, security breaches, or unusual system behavior. Security-related triggers are particularly sensitive because they may indicate unauthorized access attempts or active exploitation of vulnerabilities. In such cases, rapid response is essential to prevent further compromise.
Business context also plays a significant role in determining triggers. A system failure during peak operational hours may be more critical than the same failure during low activity periods. Similarly, issues affecting executive operations or financial systems are often prioritized higher due to their broader impact.
Automated monitoring tools often generate alerts that feed into incident response systems. However, not all alerts require immediate action. Part of the on-call responsibility is to evaluate whether an alert represents a genuine incident or a false positive. This requires both technical knowledge and situational judgment.
Proper classification of triggers ensures that response efforts are focused on the most impactful issues. It also prevents unnecessary escalation, which can lead to alert fatigue among teams. A well-defined triggering mechanism helps maintain balance between responsiveness and operational efficiency.
Defining On-Call Responsibilities in Practice
On-call responsibilities involve more than simply being available outside regular working hours. They require active readiness to respond, assess, and coordinate resolution efforts for incidents as they arise. This includes both technical intervention and communication responsibilities.
When an on-call engineer receives an alert, the first responsibility is typically triage. This involves quickly understanding the nature of the issue, identifying affected systems, and determining the severity level. Based on this assessment, the responder decides whether immediate action is required or whether escalation to another team is necessary.
Another key responsibility is maintaining communication. Incident response is a collaborative process, and effective communication ensures that all relevant stakeholders are informed. This may include technical teams, management, or other departments, depending on the scope of the incident. Clear communication helps prevent duplication of effort and ensures alignment during resolution.
On-call responsibilities also include documentation. Every action taken during an incident must be recorded for future analysis. This documentation helps teams understand what happened, how it was resolved, and what improvements can be made to prevent recurrence. Accurate records are essential for post-incident reviews.
In some cases, on-call engineers may be required to coordinate multiple teams. Complex incidents often involve overlapping systems, meaning no single team can resolve the issue independently. Coordination ensures that efforts are aligned and that resolution steps do not conflict with each other.
On-call duty also requires decision-making under pressure. Time-sensitive situations may require quick judgment without complete information. This makes experience and familiarity with systems highly valuable in on-call roles.
Structure of On-Call Rotations and Coverage Models
Organizations implement on-call rotations in different ways depending on their size, operational needs, and service criticality. A rotation system ensures that responsibility is shared among qualified individuals, reducing the burden on any single team member.
One common model is the weekly rotation, where responsibility shifts from one individual to another on a scheduled basis. This approach provides predictability and allows team members to plan their personal time around on-call duties. It also ensures that no single person is continuously exposed to after-hours responsibilities.
In larger organizations, specialized rotations may exist. Different teams may handle different types of incidents. For example, infrastructure teams may manage server issues, while application teams handle software-related incidents. This specialization improves response accuracy and efficiency.
Some organizations implement tiered on-call structures. In such models, initial alerts are handled by a first-line responder who performs triage. If the issue is complex or beyond their scope, it is escalated to a second or third level responder with deeper expertise. This layered approach helps manage workload and ensures appropriate expertise is applied.
Coverage models also define overlap strategies to prevent gaps in responsibility. Transition periods between on-call shifts are often structured to ensure continuity. Incoming responders are briefed on ongoing issues so that no incident is left unmanaged during handover.
The effectiveness of a rotation model depends on clear documentation, consistent communication, and well-defined expectations. Without these, transitions can become unclear, leading to delays or missed responses.
The Human Impact of On-Call Duties in IT Teams
On-call responsibilities can have a significant impact on individuals working in IT and security roles. While these duties are essential for maintaining system reliability, they also introduce challenges related to workload, stress, and work-life balance.
One of the primary challenges is unpredictability. Incidents can occur at any time, including nights, weekends, and holidays. This unpredictability can make it difficult for individuals to fully disconnect from work responsibilities during their on-call period.
Repeated interruptions during rest periods can lead to fatigue, which may affect performance during both on-call and regular working hours. Over time, this can contribute to burnout if not properly managed through rotation policies and workload distribution.
However, structured on-call systems can help mitigate these effects. By ensuring fair rotation and providing adequate recovery time after incidents, organizations can reduce the strain on individuals. Some environments also provide compensation or time-off adjustments to acknowledge the additional responsibility.
Team culture also plays a role in managing the human impact. Supportive environments where team members assist each other during incidents can reduce pressure on individuals. Shared responsibility and collaboration help distribute the workload more evenly.
Training and preparation further reduce stress. When individuals are confident in their ability to respond effectively, they are less likely to experience anxiety during incidents. Familiarity with systems and procedures increases confidence and reduces uncertainty.
Ultimately, balancing operational needs with human sustainability is essential for maintaining an effective on-call system over the long term.
Communication Expectations During On-Call Situations
Communication is one of the most critical aspects of effective on-call incident response. When an incident occurs, timely and accurate communication ensures that all relevant parties understand the situation and can contribute effectively to resolution efforts.
The first communication responsibility is acknowledgment. Once an alert is received, the on-call responder must confirm awareness and begin initial assessment. This prevents unnecessary escalation and assures monitoring systems that the incident is being handled.
Internal communication with technical teams follows quickly after triage. Depending on the severity, multiple teams may need to be involved simultaneously. Clear communication ensures that each team understands its role and avoids duplicated effort.
Status updates are also essential during ongoing incidents. Stakeholders need regular updates on progress, impact, and expected resolution timelines. Even when no immediate fix is available, providing updates helps maintain transparency and manage expectations.
Communication must also be structured. Informal or unclear messages can lead to confusion, especially during high-pressure situations. Effective communication focuses on facts, current status, and next steps.
In addition to technical communication, coordination with non-technical stakeholders may be necessary. This includes management teams or customer-facing departments that need to relay information externally. Ensuring consistent messaging across all channels is important for maintaining trust.
Documentation of communication is equally important. Keeping records of decisions, updates, and actions taken during incidents supports post-incident analysis and helps improve future response efforts.
Core Skills Required for On-Call Incident Response
Effective on-call incident response requires a combination of technical knowledge and practical problem-solving skills. Technical expertise allows responders to understand systems and identify root causes, while analytical skills help in diagnosing unfamiliar issues quickly.
One essential skill is system familiarity. On-call responders must understand the architecture, dependencies, and configurations of the systems they support. Without this knowledge, identifying the source of an issue becomes significantly more difficult.
Another important skill is troubleshooting under pressure. Incidents often occur unexpectedly and require rapid analysis. The ability to remain methodical while working under time constraints is critical for effective resolution.
Communication skills are equally important. Clear and concise communication ensures that teams remain aligned during incidents. Miscommunication can lead to delays or incorrect actions, worsening the situation.
Decision-making is another core requirement. On-call responders often need to make quick decisions with incomplete information. Knowing when to act, when to escalate, and when to monitor is a key part of the role.
Familiarity with monitoring tools and diagnostic systems is also essential. These tools provide the data needed to understand system behavior and identify anomalies. Efficient use of these tools can significantly reduce response time.
Adaptability is important as well, since no two incidents are the same. Responders must be able to adjust their approach based on the nature of the issue and available information.
The Relationship Between On-Call Teams and Escalation Paths
Escalation paths define how incidents move from initial responders to more specialized or senior teams when necessary. On-call teams are typically the first point of contact in this structure, responsible for assessing whether escalation is required.
The escalation process begins when an on-call responder determines that an issue exceeds their ability to resolve it within a reasonable timeframe or requires specialized expertise. This ensures that complex problems are handled by the most appropriate resources.
Escalation paths are usually hierarchical. Initial responders may escalate to senior engineers, specialized teams, or management depending on the severity and nature of the incident. Each level provides additional expertise or authority to resolve the issue.
Clear escalation rules are essential for preventing delays. Without predefined paths, responders may hesitate or choose incorrect escalation points, leading to inefficiencies.
Effective escalation also depends on communication. When an issue is escalated, the receiving team must be provided with complete context, including what has been tried and what remains unresolved. This reduces duplication of effort and speeds up resolution.
Escalation is not a failure of the on-call responder but a structured part of the process. It ensures that incidents are handled efficiently and that resources are used appropriately based on complexity.
Preparing for On-Call Shifts: Operational Readiness
Preparation is a critical part of successful on-call performance. Before entering an on-call shift, individuals must ensure they are operationally ready to respond to incidents at any time.
This includes ensuring access to necessary tools and systems. Responders must be able to connect to monitoring platforms, logs, and infrastructure systems without delay. Any access issues can significantly slow down response time.
Understanding the current system status is also important. Awareness of ongoing maintenance, deployments, or known issues helps responders distinguish between expected behavior and true incidents.
Mental readiness is another aspect of preparation. On-call shifts require attention and availability, meaning individuals should be prepared for potential interruptions during their shift period.
Reviewing recent incidents can also be beneficial. Understanding previous issues and their resolutions helps build familiarity with recurring patterns and potential weak points in systems.
Coordination with previous on-call personnel ensures continuity. If incidents are ongoing, incoming responders must be fully briefed to avoid gaps in response.
Preparation ultimately ensures that when an alert occurs, the responder can act quickly, confidently, and effectively without unnecessary delay.
Building an Effective Escalation Matrix for Incident Handling
An escalation matrix is a structured framework that defines how incidents move between different levels of support and authority when they cannot be resolved at the initial stage. In on-call operations, this structure ensures that no incident remains stalled due to uncertainty about who should be involved next.
A well-designed escalation matrix assigns clear ownership at each level of severity. The first layer typically includes on-call engineers responsible for immediate triage. If the issue requires deeper expertise, it moves to specialized technical teams. Beyond that, senior engineers or architects may become involved when system-wide impact or complex root causes are suspected.
Escalation matrices also define timing rules. These rules determine how long a responder should attempt resolution before escalating. This prevents incidents from lingering too long at one level, especially when resolution requires expertise beyond the current responder’s scope.
In addition to technical escalation, organizational escalation is also part of the structure. This includes notifying management, business stakeholders, or executive teams when incidents reach a threshold of business impact. These escalations are not about technical resolution but about decision-making and risk awareness.
A strong escalation matrix reduces confusion during high-pressure situations. Instead of debating who should be contacted, responders follow predefined paths that ensure efficiency and accountability. This structure is especially important in large environments where multiple teams operate independently but depend on shared systems.
Severity Classification and Incident Prioritization Models
Severity classification is a core mechanism used to prioritize incidents based on their impact on business operations. Not all incidents carry the same level of urgency, and proper classification ensures that resources are allocated appropriately.
Incidents are typically categorized into multiple severity levels, ranging from low-impact informational issues to critical system outages. High-severity incidents usually involve complete service disruption, security breaches, or significant financial risk. Lower severity incidents may involve minor performance degradation or isolated user issues.
The classification process considers several factors, including the number of affected users, the importance of affected systems, and the potential financial or reputational impact. This ensures that technical issues are evaluated in a business context rather than purely from a system perspective.
Accurate severity classification is essential for on-call responders because it directly influences response urgency. A misclassified incident can lead to either unnecessary escalation or delayed response, both of which can negatively affect operations.
Prioritization models also help manage multiple simultaneous incidents. When several alerts occur at once, responders must decide which issue requires immediate attention. Severity classification provides a structured way to make these decisions consistently.
Over time, organizations refine severity definitions based on historical incidents. This ensures that classification remains aligned with real-world impact rather than theoretical assumptions.
The Role of Monitoring Systems in On-Call Operations
Monitoring systems form the backbone of incident detection in modern IT environments. These systems continuously observe infrastructure, applications, and network behavior to identify anomalies that may indicate potential incidents.
In on-call environments, monitoring tools generate alerts when predefined thresholds are exceeded or when unusual patterns are detected. These alerts are the primary trigger for incident response activities. Without monitoring systems, incidents would often go unnoticed until they cause significant disruption.
Effective monitoring relies on carefully configured metrics. These metrics may include system performance indicators, error rates, latency levels, or resource utilization. Each metric provides insight into the health of different system components.
However, monitoring systems must be carefully tuned to avoid excessive noise. Poorly configured alerts can lead to alert fatigue, where responders become overwhelmed by non-critical notifications. This reduces responsiveness and increases the risk of missing important incidents.
Modern monitoring systems often include correlation features that group related alerts into a single incident. This helps reduce duplication and provides a clearer picture of system-wide issues.
In on-call operations, monitoring systems act as both early warning mechanisms and diagnostic tools. Once an incident is detected, responders use these systems to investigate root causes and track system recovery in real time.
Alert Fatigue and Its Impact on Incident Response Efficiency
Alert fatigue occurs when on-call responders are exposed to a high volume of alerts, many of which are not actionable or critical. Over time, this can reduce sensitivity to important alerts and negatively impact response effectiveness.
When responders receive too many notifications, they may begin to ignore or delay responses to certain alerts. This increases the risk of missing genuine incidents that require immediate attention. In high-stakes environments, this can lead to prolonged outages or security exposure.
One of the main causes of alert fatigue is poorly tuned monitoring systems. When thresholds are too sensitive, even minor fluctuations generate alerts. This creates unnecessary workload for on-call teams and reduces overall efficiency.
Another contributing factor is a lack of prioritization. When all alerts are treated equally, responders may struggle to determine which issues require immediate attention. This leads to cognitive overload and slower decision-making.
To mitigate alert fatigue, organizations often implement alert filtering and aggregation strategies. These approaches reduce noise by grouping similar alerts or suppressing non-critical notifications during known maintenance windows.
Addressing alert fatigue is essential for maintaining the long-term sustainability of on-call operations. Without proper management, even well-designed incident response systems can become ineffective due to human overload.
The Incident Lifecycle From Detection to Resolution
Every incident follows a lifecycle that begins with detection and ends with resolution and closure. Understanding this lifecycle is essential for effective on-call operations because it provides structure for how incidents are managed.
The first stage is detection, where monitoring systems or users identify abnormal behavior. Once detected, the incident enters the triage phase, where on-call responders assess severity and impact.
During triage, responders gather information to understand the scope of the issue. This includes identifying affected systems, reviewing logs, and checking system health indicators. The goal is to quickly determine whether immediate action is required.
After triage, the incident moves into the investigation and response phase. Here, responders attempt to identify the root cause and implement temporary or permanent fixes. This phase often involves collaboration between multiple teams.
Once the issue is resolved, the recovery phase begins. Systems are monitored to ensure stability and confirm that the issue has been fully addressed. If necessary, additional fixes may be applied during this phase.
The final stage is closure, where the incident is formally documented and marked as resolved. This includes recording timelines, actions taken, and outcomes for future reference.
Understanding the incident lifecycle helps ensure that on-call responders approach incidents in a structured and consistent manner, reducing confusion and improving efficiency.
Communication Channels and Coordination During Active Incidents
Effective communication channels are essential during incident response because they ensure that all relevant teams remain aligned throughout the resolution process. Without clear communication, incidents can become more complex due to overlapping actions or conflicting decisions.
Most organizations define specific communication platforms for incident coordination. These platforms serve as central hubs where updates, decisions, and progress reports are shared in real time.
During active incidents, communication must be structured and purposeful. Responders provide updates on system status, actions taken, and next steps. This helps maintain situational awareness across teams.
Coordination also involves managing different communication audiences. Technical teams require detailed system information, while management and stakeholders need high-level updates focused on impact and resolution timelines.
Miscommunication can lead to duplicated effort or delayed response. For example, if two teams independently attempt fixes without coordination, their actions may conflict and worsen the issue.
Regular updates are important even when progress is slow. Silence during an incident can create uncertainty and lead to unnecessary escalations. Consistent communication helps maintain trust and alignment.
Clear communication channels also support post-incident analysis by providing a record of decisions and actions taken during the event.
Runbooks and Standard Operating Procedures in On-Call Workflows
Runbooks are structured documentation guides that outline step-by-step procedures for handling common incidents. They are essential tools in on-call environments because they provide responders with predefined instructions during high-pressure situations.
A well-designed runbook includes diagnostic steps, common causes, and resolution procedures. This allows responders to follow a consistent process rather than relying solely on memory or improvisation.
Runbooks reduce response time by eliminating uncertainty. When an incident occurs, responders can quickly refer to relevant documentation and begin resolution without extensive investigation.
Standard operating procedures complement runbooks by defining broader operational rules. These include escalation policies, communication protocols, and incident classification guidelines.
Together, runbooks and procedures ensure consistency across different responders. This is particularly important in rotation-based on-call systems, where different individuals may handle similar incidents at different times.
Runbooks are continuously updated based on post-incident reviews. When new issues are discovered or existing procedures are improved, documentation is revised to reflect the latest knowledge.
In mature environments, runbooks are integrated into monitoring systems, allowing responders to access relevant documentation directly from alerts.
Cross-Team Collaboration During Complex Incidents
Complex incidents often involve multiple systems and therefore require collaboration between different teams. On-call responders play a central role in coordinating these efforts and ensuring alignment across technical domains.
Each team contributes specialized knowledge. For example, infrastructure teams may focus on system stability, while application teams address software behavior. Security teams may investigate potential breaches or unauthorized access.
Effective collaboration requires a clear division of responsibilities. Without defined roles, teams may duplicate efforts or overlook critical aspects of the incident.
On-call responders often act as coordinators during these situations. They ensure that tasks are distributed appropriately and that progress is communicated across teams.
Collaboration also involves managing dependencies. Some fixes cannot be applied until other issues are resolved, making coordination essential for sequencing actions correctly.
In high-impact incidents, collaboration may extend beyond technical teams to include business units. This ensures that operational decisions align with business priorities.
Strong cross-team collaboration improves resolution speed and reduces the risk of incomplete fixes.
Data Collection, Logging, and Evidence Gathering During Incidents
Data collection plays a critical role in understanding and resolving incidents. Logs, metrics, and system traces provide the information needed to diagnose issues accurately.
During an incident, responders rely heavily on logs to reconstruct system behavior. These logs help identify the sequence of events leading up to the issue.
Metrics provide quantitative insights into system performance. Sudden changes in resource usage, error rates, or response times often indicate the presence of an underlying problem.
Evidence gathering is not only important for immediate resolution but also for post-incident analysis. Accurate data allows teams to understand root causes and prevent recurrence.
Proper logging practices ensure that relevant information is available when needed. Incomplete or missing logs can significantly slow down incident investigation.
On-call responders must know how to access and interpret logs efficiently. This skill is essential for reducing resolution time and improving diagnostic accuracy.
Data collected during incidents also supports long-term system improvements by highlighting recurring issues and system weaknesses.
Managing Service Level Expectations During On-Call Incidents
Service level expectations define how quickly incidents should be acknowledged and resolved based on their severity. These expectations are critical in guiding on-call response behavior.
High-severity incidents typically require immediate acknowledgment and rapid action. Lower severity incidents may have longer resolution windows depending on their impact.
On-call responders must balance speed with accuracy. While fast response is important, incorrect fixes can worsen the situation and increase recovery time.
Service level expectations also influence communication frequency. Critical incidents require frequent updates, while lower-priority issues may require less frequent reporting.
Meeting service expectations requires coordination between technical teams and business stakeholders. Both sides must understand what is realistically achievable during an incident.
These expectations are often defined in advance to ensure consistency. They help align operational performance with business requirements and customer commitments.
When service levels are not met, it often triggers post-incident reviews to identify gaps in response processes or resource allocation.
Handling Security-Specific Incidents in On-Call Environments
Security-related incidents require specialized handling due to their potential impact on data integrity, confidentiality, and system trust. On-call responders must treat these incidents with heightened urgency and caution.
Security incidents may include unauthorized access attempts, malware detection, or suspicious network activity. Each of these requires immediate investigation to prevent escalation.
The priority in security incidents is containment. This involves isolating affected systems to prevent further spread or damage.
After containment, responders focus on investigation. This includes identifying the source of the incident and understanding the scope of compromise.
Security incidents often involve additional stakeholders such as compliance teams or legal departments. These teams help ensure that response actions align with regulatory requirements.
Evidence preservation is particularly important in security incidents. Logs and system data must be carefully preserved for forensic analysis.
On-call responders handling security incidents must balance rapid action with careful documentation to ensure both operational recovery and investigative integrity.
Incident Response Automation and Its Role in On-Call Efficiency
Automation has become an essential part of modern incident response because it reduces the time required to detect, triage, and sometimes even resolve issues. In on-call environments, where speed and accuracy are critical, automation helps reduce manual workload and allows responders to focus on complex decision-making rather than repetitive tasks.
Automated alerting systems can instantly detect anomalies in system behavior and trigger predefined workflows. These workflows may include collecting logs, restarting services, or isolating affected components. By executing these actions immediately, automation shortens the initial response window and helps contain incidents before they escalate.
In many cases, automation also assists in triage. Instead of manually gathering information, on-call responders can rely on automated diagnostics that summarize system health, affected services, and potential root causes. This allows faster decision-making during critical situations.
However, automation is not a replacement for human judgment. While automated systems can execute predefined actions, they cannot fully understand business context or make nuanced decisions about trade-offs. On-call engineers must still evaluate whether automated responses are appropriate or if manual intervention is required.
Over-reliance on automation can also introduce risks. Incorrectly configured automation may amplify incidents instead of resolving them. For example, a misconfigured restart loop could repeatedly fail and increase system instability. For this reason, automated actions are typically designed with safeguards and rollback mechanisms.
When properly implemented, automation significantly enhances on-call efficiency. It reduces response time, minimizes human error, and allows teams to manage larger systems with fewer resources.
Post-Incident Analysis and Continuous Learning in On-Call Systems
After an incident is resolved, organizations conduct post-incident analysis to understand what happened, why it happened, and how similar issues can be prevented in the future. This process is a critical part of improving on-call effectiveness over time.
Post-incident analysis focuses on identifying root causes rather than just symptoms. This involves reviewing logs, system behavior, and response actions taken during the incident. The goal is to understand the underlying failure points that led to the disruption.
On-call responders play an important role in this process because they have firsthand experience of how the incident unfolded. Their insights help reconstruct the timeline and identify decision points where different actions could have been taken.
These reviews also examine response effectiveness. This includes evaluating how quickly the incident was detected, how accurately it was classified, and how efficiently it was resolved. Any delays or missteps are analyzed to improve future performance.
A key aspect of post-incident analysis is identifying systemic improvements. These may include improving monitoring systems, updating runbooks, refining escalation paths, or enhancing automation workflows.
Importantly, post-incident reviews are not focused on assigning blame. Instead, they aim to improve processes and reduce the likelihood of recurrence. This encourages openness and honest discussion among teams.
Over time, organizations build a knowledge base of past incidents. This historical data becomes a valuable resource for training new responders and improving overall incident response maturity.
The Importance of Reliability Engineering in On-Call Operations
Reliability engineering is closely connected to incident response because it focuses on designing systems that are resilient, fault-tolerant, and capable of recovering quickly from failures. In on-call environments, reliability engineering reduces the frequency and severity of incidents that responders must handle.
A key principle of reliability engineering is anticipating failure. Instead of assuming systems will always function correctly, engineers design infrastructure with the expectation that failures will occur. This mindset leads to a more robust system architecture.
Redundancy is one of the most common reliability strategies. By duplicating critical components, systems can continue operating even if one component fails. This reduces downtime and minimizes the need for emergency intervention.
Another important aspect is fault isolation. Systems are designed so that failures in one area do not cascade into others. This containment approach prevents small issues from becoming large-scale incidents.
Reliability engineering also emphasizes observability. Systems must provide clear visibility into their internal state so that issues can be quickly detected and diagnosed. Without observability, on-call responders struggle to understand what is happening during incidents.
In addition, reliability practices include regular testing of failure scenarios. This helps ensure that systems behave as expected under stress conditions and that recovery procedures are effective.
When reliability engineering is strong, on-call teams experience fewer critical incidents and can focus more on optimization rather than constant firefighting.
Managing On-Call Stress and Maintaining Performance
On-call responsibilities can introduce significant stress due to unpredictability and urgency. Managing this stress is important for maintaining both individual well-being and operational effectiveness.
One of the main contributors to stress is the uncertainty of incidents. Since alerts can occur at any time, responders must remain mentally prepared throughout their shift. This constant readiness can be mentally exhausting if not properly managed.
Another factor is responsibility pressure. On-call responders are often responsible for critical systems that affect business operations. The awareness that delays or mistakes can have significant consequences can increase stress levels.
To manage stress effectively, organizations often implement structured rotation systems. These ensure that on-call duties are distributed fairly and that individuals have sufficient recovery time between shifts.
Clear escalation paths also reduce stress by providing responders with support options when incidents become complex. Knowing that assistance is available helps reduce the feeling of isolation during critical situations.
Training and preparation further contribute to stress reduction. When responders are confident in their ability to handle incidents, they are less likely to feel overwhelmed during emergencies.
Maintaining a healthy balance between on-call duties and regular work responsibilities is also important. Excessive on-call frequency can lead to fatigue, which negatively impacts both performance and decision-making.
Sustainable on-call systems prioritize long-term team health alongside operational reliability.
The Evolving Nature of On-Call in Modern Cloud Environments
As technology environments evolve, so do on-call responsibilities. Modern cloud-based systems introduce new complexities but also provide new tools for managing incidents more effectively.
Cloud environments are highly dynamic, with resources scaling up and down automatically based on demand. While this improves efficiency, it also introduces variability that on-call responders must understand.
Distributed systems architecture means that incidents may originate in one service but affect multiple downstream components. This requires responders to think in terms of system-wide dependencies rather than isolated failures.
Cloud providers also offer built-in monitoring and diagnostic tools that enhance visibility. These tools help on-call engineers quickly identify issues across large-scale infrastructure.
However, the abstraction of infrastructure in cloud environments can sometimes make root cause analysis more challenging. Responders may not have direct access to underlying hardware or system layers, requiring reliance on higher-level metrics.
Automation and infrastructure-as-code practices are increasingly important in cloud-based on-call operations. These practices allow systems to be rebuilt or repaired quickly using predefined configurations.
The evolving nature of cloud systems means that on-call roles are also becoming more specialized. Engineers are expected to understand both traditional infrastructure concepts and modern cloud-native architectures.
Building a Culture of Ownership in On-Call Teams
A strong on-call system depends not only on processes and tools but also on organizational culture. A culture of ownership ensures that individuals take responsibility for the systems they support and actively engage in resolving issues.
Ownership means that on-call responders do not simply act as ticket handlers but as problem solvers who understand the broader impact of their work. This mindset leads to more proactive incident resolution and better system outcomes.
In ownership-driven cultures, engineers are encouraged to understand system design deeply. This allows them to respond more effectively during incidents because they are familiar with how components interact.
Collaboration is also a key part of ownership culture. Teams work together to resolve incidents rather than operating in isolation. This shared responsibility improves response speed and accuracy.
Transparency is another important element. Open communication about incidents, failures, and improvements fosters trust and continuous learning across teams.
Organizations that promote ownership often see improved on-call performance because individuals feel more invested in system reliability and long-term success.
Conclusion
Incident response and on-call responsibilities form a critical foundation for maintaining the stability, security, and reliability of modern IT systems. As organizations increasingly depend on interconnected digital environments, the ability to detect, assess, and resolve incidents quickly has become essential for business continuity. On-call teams act as the first line of defense when systems fail, ensuring that issues are addressed before they escalate into larger operational or security disruptions.
A well-structured incident response framework, supported by clear escalation paths, monitoring systems, and documented procedures, allows teams to respond with consistency and confidence. At the same time, effective on-call operations depend heavily on preparation, communication, and collaboration across technical and non-technical teams. Without these elements, even minor incidents can become complex and difficult to manage.
Equally important is the human aspect of on-call work. Sustainable rotation models, proper training, and supportive team culture help reduce stress and prevent burnout while maintaining high performance. Continuous improvement through post-incident analysis ensures that each event contributes to stronger systems and better processes in the future.
Ultimately, strong incident response practices transform unpredictable system failures into manageable, structured events, helping organizations maintain resilience and trust in an increasingly demanding digital landscape.