Machine learning has become a foundational element of modern digital systems, shaping how businesses operate, how services are delivered, and how decisions are made at scale. What was once considered an advanced research area has now evolved into a practical necessity across industries such as finance, healthcare, retail, logistics, and entertainment. Organizations increasingly rely on machine learning systems to analyze large volumes of data, detect patterns, automate decision-making, and improve operational efficiency.
This widespread adoption has changed expectations for technical professionals. It is no longer sufficient to understand machine learning at a theoretical level. Companies now expect engineers and analysts to build systems that can function reliably in production environments, handle real-world data complexity, and scale as demand increases. As a result, the role of a machine learning engineer has become more defined and more critical than ever before.
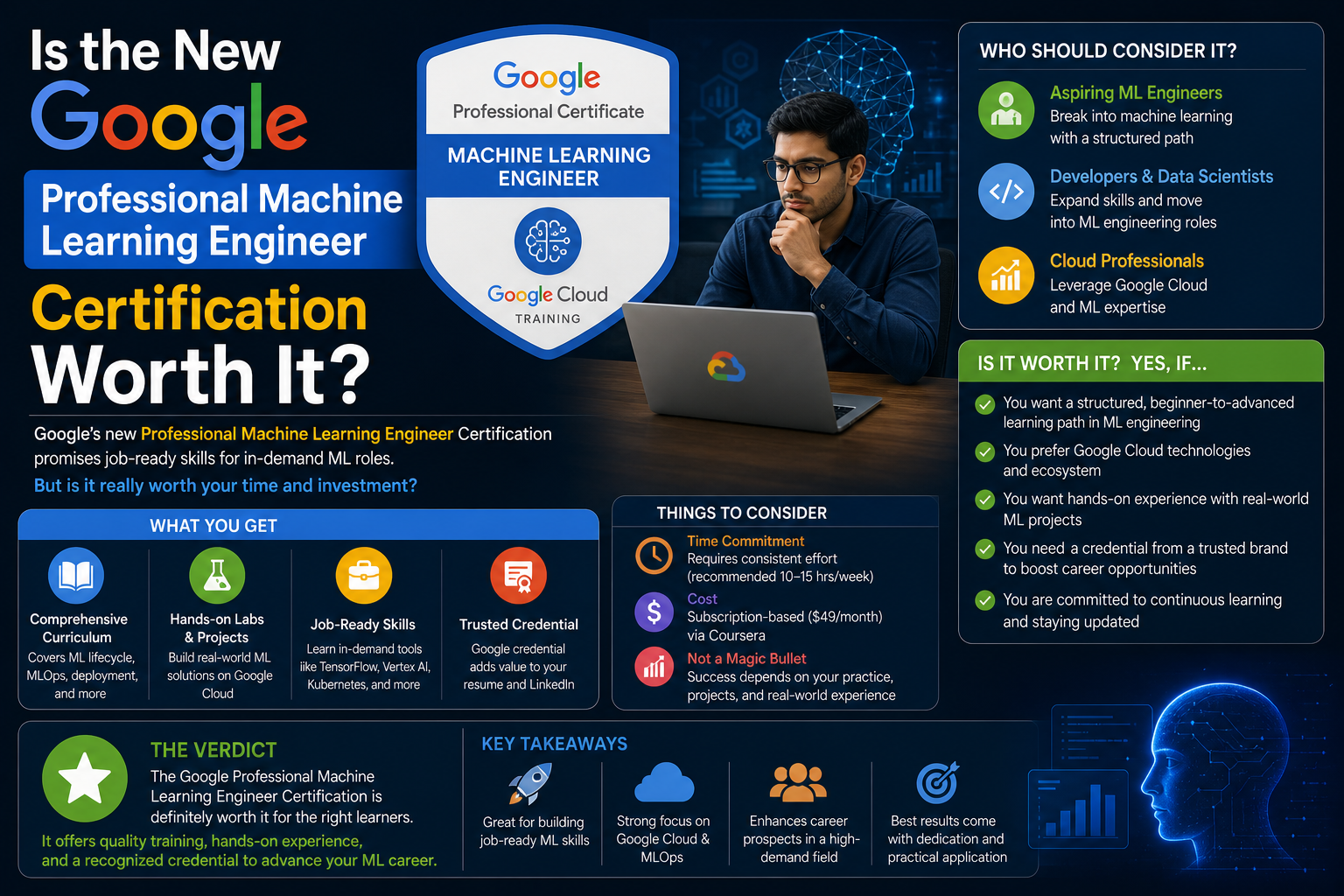
Within this context, certifications like the Google Professional Machine Learning Engineer certification have gained attention because they aim to validate not just theoretical knowledge but also applied skills in building and managing machine learning systems in cloud environments.
Evolution of Machine Learning from Research to Production Systems
Machine learning originally developed as a branch of academic research focused on algorithms, statistical modeling, and experimental analysis. Early models were typically small-scale, used controlled datasets, and operated in environments where performance constraints were not a major concern. Over time, however, the field shifted significantly toward real-world deployment.
Modern machine learning systems are expected to operate continuously, process streaming or large-scale batch data, and integrate with complex software ecosystems. This shift has introduced new challenges that go beyond model accuracy. Engineers must now consider system reliability, latency, scalability, monitoring, and maintenance.
This evolution has led to the rise of production-oriented machine learning engineering, where success is not measured solely by model performance metrics but also by how effectively a model integrates into business operations. It is within this environment that cloud platforms, especially Google Cloud, play a central role by providing infrastructure and tools designed specifically for scalable machine learning workflows.
The Role of Google Cloud in Machine Learning Engineering
Google Cloud provides a comprehensive ecosystem for building, training, deploying, and managing machine learning models. Its tools are designed to support the entire machine learning lifecycle, from data ingestion to model monitoring. This includes managed services for data storage, distributed processing, model training, and deployment pipelines.
One of the key advantages of working within a cloud environment is scalability. Machine learning workloads often require significant computational resources, especially during training phases. Cloud platforms allow engineers to dynamically allocate resources based on demand, reducing the limitations of local hardware.
Another important aspect is integration. Machine learning systems rarely operate in isolation. They often interact with databases, APIs, analytics tools, and user-facing applications. Google Cloud provides a unified environment where these components can be connected and managed more efficiently.
Because of this ecosystem, the Google Professional Machine Learning Engineer certification focuses heavily on evaluating how well candidates understand and apply these cloud-based tools in practical scenarios.
Core Responsibilities of a Machine Learning Engineer
A machine learning engineer is responsible for transforming data-driven ideas into functional systems that deliver measurable outcomes. This role involves several interconnected responsibilities that span the entire lifecycle of a machine learning solution.
One of the primary responsibilities is designing machine learning solutions based on business requirements. This involves understanding the problem, identifying relevant data sources, and determining whether machine learning is the appropriate approach.
Another major responsibility is building and training models. This requires selecting appropriate algorithms, preparing datasets, and fine-tuning model parameters to achieve desired performance levels.
Once models are developed, engineers must deploy them into production environments. This includes setting up infrastructure, ensuring scalability, and integrating models with existing systems. Deployment is not a one-time task; it requires continuous updates and optimization.
Monitoring is also a critical responsibility. Machine learning models can degrade over time due to changes in data distribution or external conditions. Engineers must track performance metrics and implement mechanisms for retraining or adjustment when necessary.
Why Organizations Invest in Machine Learning Solutions
Organizations adopt machine learning for a variety of strategic reasons, but the underlying goal is usually to improve decision-making and efficiency. Machine learning systems can process vast amounts of data far more quickly than traditional methods, allowing businesses to identify patterns that would otherwise remain hidden.
In operational contexts, machine learning can automate repetitive tasks, reducing the need for manual intervention. In customer-facing applications, it can personalize experiences by analyzing user behavior and preferences. In financial systems, it can detect anomalies or fraudulent activities in real time.
However, implementing machine learning is not a trivial task. It requires significant investment in infrastructure, expertise, and ongoing maintenance. This is why organizations seek professionals who can not only build models but also ensure that those models are reliable, scalable, and aligned with business goals.
The Shift Toward Production-Ready Machine Learning Systems
One of the most significant changes in the machine learning field is the shift from experimental models to production-ready systems. In early stages of machine learning development, success was often measured in terms of accuracy on test datasets. Today, success is defined more broadly.
Production-ready machine learning systems must meet requirements such as reliability, scalability, maintainability, and interpretability. They must also be resilient to changes in data and capable of operating continuously without manual intervention.
This shift has introduced the need for structured workflows that govern the entire lifecycle of machine learning models. These workflows ensure that models are not only built correctly but also deployed and maintained in a controlled and efficient manner.
Cloud-based platforms have become essential in supporting this shift, as they provide tools for automation, orchestration, and monitoring of machine learning pipelines.
Understanding the Machine Learning Lifecycle
The machine learning lifecycle refers to the complete process of developing and maintaining a machine learning system. It typically begins with problem definition and data collection, followed by data preprocessing, model training, evaluation, deployment, and ongoing monitoring.
Each stage of the lifecycle is interconnected. For example, the quality of data preparation directly impacts model performance, while deployment decisions affect scalability and user experience. Because of this interconnected nature, machine learning engineering requires a holistic understanding of the entire system rather than isolated knowledge of individual components.
In modern environments, this lifecycle is often automated using pipelines that ensure consistency and repeatability. These pipelines are especially important in large-scale systems where manual processes would be inefficient and error-prone.
The Importance of Data Pipelines in Machine Learning Systems
Data is the foundation of all machine learning systems. Without high-quality data, even the most advanced algorithms cannot produce meaningful results. Data pipelines are responsible for collecting, transforming, and delivering data in a format that can be used for training and inference.
In real-world systems, data often comes from multiple sources and in different formats. It may also contain inconsistencies, missing values, or noise. Data pipelines address these challenges by applying preprocessing steps such as cleaning, normalization, and feature engineering.
A well-designed data pipeline ensures that data flows efficiently from source systems to machine learning models without delays or errors. It also supports scalability, allowing systems to handle increasing volumes of data over time.
Model Training and Evaluation in Practical Scenarios
Model training involves teaching a machine learning algorithm to recognize patterns in data. This process requires selecting appropriate features, choosing model architectures, and adjusting parameters to minimize error.
Evaluation is equally important, as it determines how well a model performs on unseen data. Common evaluation techniques include splitting data into training and testing sets, cross-validation, and performance metric analysis.
In real-world applications, evaluation goes beyond simple accuracy measures. Engineers must consider factors such as robustness, fairness, and generalization. A model that performs well in controlled environments may not necessarily perform well in production if it is not properly evaluated.
Deployment and Serving of Machine Learning Models
Once a model is trained and evaluated, it must be deployed into a production environment where it can serve predictions. This process involves integrating the model into applications, APIs, or backend systems.
Serving models efficiently requires careful consideration of latency, throughput, and resource usage. In many cases, models must handle real-time requests, which adds additional complexity to the deployment process.
Deployment also involves versioning and rollback strategies. As models are updated or improved, engineers must ensure that changes do not disrupt existing systems.
Introduction to MLOps Concepts
MLOps refers to the set of practices that combine machine learning development with operational workflows. It focuses on automating and standardizing the machine learning lifecycle to improve efficiency and reliability.
Key aspects of MLOps include pipeline automation, continuous integration, continuous deployment, and model monitoring. These practices help ensure that machine learning systems remain stable and adaptable over time.
MLOps also emphasizes collaboration between different teams, including data engineers, software developers, and operations specialists. This collaborative approach is essential for building scalable and maintainable systems.
Collaboration Across Technical and Business Teams
Machine learning engineering is not an isolated activity. It requires close collaboration between technical teams and business stakeholders. Engineers must translate business requirements into technical specifications and ensure that models align with organizational goals.
Effective communication is essential in this process. Business teams may focus on outcomes such as revenue growth or customer satisfaction, while technical teams focus on model performance and system efficiency. Bridging this gap is a key responsibility of machine learning engineers.
Responsible AI and Ethical Considerations
As machine learning systems become more influential in decision-making processes, ethical considerations have become increasingly important. Responsible AI involves ensuring that models are fair, transparent, and free from bias.
This includes carefully evaluating training data, monitoring model outputs, and implementing safeguards against unintended consequences. Engineers must also consider privacy and security implications when designing machine learning systems.
Responsible AI is not just a technical requirement but also a societal expectation, especially in systems that impact individuals directly.
Scalability Challenges in Machine Learning Systems
Scalability is one of the most significant challenges in machine learning engineering. As data volumes grow and user demand increases, systems must be able to adapt without performance degradation.
Scalability concerns affect every stage of the machine learning lifecycle, from data processing to model serving. Engineers must design systems that can handle increased workloads efficiently while maintaining reliability.
Distributed computing and cloud infrastructure play a key role in addressing these challenges, allowing systems to scale dynamically based on demand.
Differences Between Machine Learning Engineers, Data Scientists, and Software Engineers
Although machine learning engineers, data scientists, and software engineers often work together, their roles differ significantly.
Data scientists typically focus on analyzing data, building statistical models, and generating insights. Software engineers focus on building applications and systems. Machine learning engineers bridge the gap between these roles by turning models into scalable production systems.
This hybrid role requires a combination of skills in software engineering, data processing, and machine learning, making it one of the most interdisciplinary positions in modern technology.
Transition from Conceptual Machine Learning to Engineering-Driven Systems
Modern machine learning engineering is no longer centered only on building predictive models in isolation. Instead, it has evolved into a discipline focused on designing complete systems where data, infrastructure, algorithms, and deployment mechanisms work together seamlessly. This transition is especially important in cloud environments where models are expected to operate continuously, adapt to changing data, and integrate with large-scale applications.
The Google Professional Machine Learning Engineer certification reflects this shift by emphasizing system design and engineering practices over isolated theoretical knowledge. Rather than focusing purely on model accuracy or algorithm selection, it evaluates how well professionals can build end-to-end machine learning solutions that function reliably in production environments.
This systems-level thinking is what distinguishes a machine learning engineer from a purely academic practitioner. It requires understanding not only how models are built but also how they behave when exposed to real-world constraints such as latency, scalability, and operational complexity.
Designing Scalable Machine Learning Architectures
A core responsibility in machine learning engineering is designing architectures that can scale efficiently as data and usage grow. Scalability is not limited to computational power; it also includes data flow, system responsiveness, and resource optimization.
In practical environments, machine learning systems must handle increasing volumes of incoming data without degrading performance. This requires distributed processing systems that can divide workloads across multiple computing nodes. Cloud environments make this possible by offering elastic infrastructure that can expand or contract based on demand.
A scalable architecture also considers fault tolerance. Systems must continue functioning even when individual components fail. This is achieved through redundancy, load balancing, and automated recovery mechanisms. Engineers must design systems with these principles in mind to ensure uninterrupted service delivery.
Another critical aspect of architecture design is modularity. Machine learning systems are often composed of multiple components such as data ingestion pipelines, feature engineering modules, training environments, and deployment services. Each of these components must be designed in a way that allows independent updates without disrupting the entire system.
Understanding Data Flow in Machine Learning Pipelines
Data flow is the backbone of any machine learning system. It determines how raw data is collected, transformed, and delivered to models for training and inference. Poorly designed data flows can lead to bottlenecks, inconsistencies, and unreliable predictions.
In real-world systems, data often originates from multiple sources, including transactional databases, user interactions, sensors, and external APIs. This data must be unified into a consistent format before it can be used effectively.
Data pipelines are responsible for managing this transformation process. They ensure that data is cleaned, validated, and structured properly. They also handle tasks such as feature extraction and aggregation, which are essential for improving model performance.
A well-structured data pipeline is automated and repeatable. Automation ensures that data processing steps are executed consistently, reducing the risk of human error. Repeatability ensures that models can be retrained using the same processes, which is essential for maintaining reliability over time.
Feature Engineering in Real-World Machine Learning Systems
Feature engineering is one of the most critical steps in machine learning development. It involves transforming raw data into meaningful inputs that models can use to make predictions.
In practical applications, raw data is often noisy, incomplete, or unstructured. Feature engineering helps convert this data into a usable format by applying transformations such as normalization, encoding, scaling, and aggregation.
The quality of features directly influences model performance. Even advanced algorithms can produce poor results if they are trained on poorly engineered features. As a result, machine learning engineers spend significant time refining feature sets to improve accuracy and generalization.
In large-scale systems, feature engineering is often automated using feature pipelines. These pipelines ensure that transformations are applied consistently during both training and inference phases, reducing discrepancies between development and production environments.
Model Training at Scale and Distributed Computing Concepts
Training machine learning models can be computationally intensive, especially when dealing with large datasets or complex architectures such as deep neural networks. In such cases, distributed computing becomes essential.
Distributed training involves splitting data and computations across multiple machines or processing units. This allows models to be trained faster and on larger datasets than would be possible on a single machine.
Cloud platforms provide managed services that support distributed training, allowing engineers to focus on model design rather than infrastructure management. These systems automatically allocate resources and optimize performance based on workload requirements.
However, distributed training introduces additional complexity. Engineers must ensure that data is properly synchronized across nodes and that model updates remain consistent. Techniques such as gradient averaging and parameter synchronization are used to address these challenges.
Evaluation Metrics Beyond Accuracy
In traditional machine learning contexts, accuracy is often considered the primary evaluation metric. However, in production systems, evaluation must go far beyond accuracy alone.
Different applications require different performance metrics. For example, in classification tasks, precision and recall may be more important than overall accuracy. In ranking systems, metrics such as mean average precision or normalized discounted cumulative gain may be more relevant.
In addition to performance metrics, engineers must also consider operational metrics such as latency, throughput, and system reliability. A model that performs well in terms of accuracy but responds slowly to requests may not be suitable for real-time applications.
Fairness and bias are also important evaluation dimensions. Models must be assessed to ensure that they do not produce discriminatory or unethical outcomes. This requires careful analysis of training data and continuous monitoring of model behavior.
Model Deployment Strategies in Cloud Environments
Deploying machine learning models involves making them accessible for predictions in production environments. This process can take several forms depending on the application requirements.
One common approach is real-time deployment, where models respond to user requests instantly. This is often used in applications such as recommendation systems, fraud detection, and search engines. Real-time deployment requires low latency and high availability.
Another approach is batch deployment, where predictions are generated in bulk at scheduled intervals. This is suitable for applications where immediate response is not required, such as reporting systems or periodic analysis.
In cloud environments, deployment is typically managed through containerized services. Containers allow models to be packaged with all their dependencies, ensuring consistent behavior across different environments.
Deployment strategies also include version control mechanisms. Multiple versions of a model may exist simultaneously, and engineers must ensure smooth transitions between versions without disrupting users.
Monitoring Machine Learning Systems in Production
Once a model is deployed, its performance must be continuously monitored. Unlike traditional software systems, machine learning models can degrade over time due to changes in data patterns, known as data drift.
Monitoring systems track key performance indicators such as prediction accuracy, response time, and resource usage. They also detect anomalies that may indicate system failures or unexpected behavior.
Data drift detection is particularly important. If the statistical properties of incoming data change significantly compared to training data, model performance may decline. In such cases, retraining or recalibration may be necessary.
Monitoring also includes logging and auditing mechanisms that allow engineers to trace predictions and understand model behavior over time. This is essential for debugging and compliance purposes.
Automation and Orchestration of Machine Learning Workflows
Automation plays a central role in modern machine learning engineering. It reduces manual effort, improves consistency, and enables faster iteration cycles.
Machine learning workflows are typically composed of multiple stages, including data ingestion, preprocessing, training, evaluation, and deployment. Orchestration systems manage the execution of these stages in a coordinated manner.
Orchestration ensures that each step is executed in the correct order and that dependencies between steps are properly managed. It also enables scheduling, allowing workflows to run at specific intervals or in response to events.
Automation is especially important in large-scale systems where manual intervention would be inefficient and error-prone. It allows teams to focus on model improvement rather than operational tasks.
Collaboration Between Data Engineering and Machine Learning Teams
Machine learning systems rely heavily on collaboration between different technical roles. Data engineers are responsible for building and maintaining data pipelines, while machine learning engineers focus on model development and deployment.
Effective collaboration ensures that data is available in the correct format and at the right time for model training. It also ensures that infrastructure is properly aligned with system requirements.
Communication between teams is essential for resolving issues related to data quality, system performance, and deployment challenges. Without coordination, machine learning projects can suffer from delays and inefficiencies.
In many organizations, machine learning engineers act as a bridge between data engineering and software engineering teams, ensuring that all components of the system work together effectively.
Infrastructure Management and Resource Optimization
Machine learning systems require significant computational resources, especially during training and large-scale inference. Efficient infrastructure management is therefore essential for cost control and performance optimization.
Cloud platforms provide tools for dynamic resource allocation, allowing systems to scale based on demand. This ensures that resources are used efficiently without overprovisioning.
Resource optimization also involves selecting appropriate hardware configurations, such as CPUs, GPUs, or specialized accelerators. Different workloads require different types of computational resources, and selecting the right configuration can significantly impact performance.
Engineers must also monitor resource usage to identify inefficiencies and optimize system performance over time.
Data Governance and Security in Machine Learning Systems
Data governance refers to the management of data availability, usability, integrity, and security. In machine learning systems, governance is critical because models rely heavily on large datasets that may contain sensitive information.
Security measures must be implemented to protect data from unauthorized access. This includes encryption, access control, and secure storage mechanisms.
Data integrity ensures that information remains accurate and consistent throughout the machine learning pipeline. Any corruption or inconsistency in data can lead to incorrect model outputs.
Governance policies also ensure compliance with regulatory requirements, particularly in industries such as healthcare and finance where data privacy is critical.
Lifecycle Management of Machine Learning Models
Machine learning models are not static; they require continuous updates and improvements. Lifecycle management refers to the process of maintaining models over time, from initial development to retirement.
This includes retraining models with new data, updating features, improving architectures, and decommissioning outdated models. Lifecycle management ensures that systems remain relevant and effective as conditions change.
In production environments, multiple models may be active simultaneously, each serving different purposes or user segments. Managing these models requires careful coordination and version tracking.
Lifecycle management is closely tied to monitoring and automation, as these systems provide the feedback and infrastructure needed to support continuous improvement.
The Industry Shift Toward Cloud-Centered Machine Learning Expertise
The modern technology landscape has shifted strongly toward cloud-first machine learning development. Organizations are no longer building isolated models that run on local systems; instead, they are constructing fully integrated, cloud-native machine learning ecosystems. These systems are designed to operate at scale, support continuous deployment, and integrate directly into business workflows.
This shift has significantly changed what companies expect from machine learning professionals. It is no longer enough to understand algorithms or data science principles in isolation. Engineers are now expected to design systems that can operate reliably in production environments, handle distributed workloads, and adapt to real-time data changes.
The Google Professional Machine Learning Engineer certification is positioned within this transformation. It reflects the increasing demand for professionals who can bridge the gap between machine learning theory and cloud-based engineering practices. Rather than focusing solely on academic understanding, it emphasizes applied skills in building production-ready systems using cloud infrastructure.
Why Production Readiness Has Become the Core Evaluation Standard
In earlier stages of machine learning adoption, success was often measured by model accuracy or experimental results. However, in real-world applications, accuracy alone is not sufficient. A model must also be stable, scalable, maintainable, and efficient under production conditions.
Production readiness refers to the ability of a machine learning system to function reliably in real operational environments. This includes handling large volumes of data, responding to user requests within acceptable latency limits, and maintaining performance over time despite changes in input data.
The certification reflects this reality by focusing heavily on operational aspects of machine learning systems. Candidates are expected to understand not only how models are built but also how they are deployed, monitored, and maintained in real environments.
This shift toward production readiness has redefined what it means to be a machine learning engineer. It is no longer a purely analytical role; it is an engineering discipline that requires system-level thinking and operational awareness.
The Strategic Role of MLOps in Modern Machine Learning Systems
MLOps has emerged as one of the most important paradigms in machine learning engineering. It combines principles from machine learning, software engineering, and DevOps to create structured workflows for managing the entire machine learning lifecycle.
At its core, MLOps focuses on automation, reproducibility, and scalability. It ensures that machine learning workflows are consistent and repeatable, reducing the risk of errors and improving efficiency.
In practice, MLOps involves automating data pipelines, training processes, deployment workflows, and monitoring systems. This allows teams to continuously improve models without manual intervention.
The Google Professional Machine Learning Engineer certification places strong emphasis on MLOps concepts because they are essential for managing real-world machine learning systems. Engineers are expected to understand how to design pipelines that support continuous integration and continuous deployment of models.
MLOps also improves collaboration between teams by standardizing workflows and reducing operational complexity. This allows data scientists, engineers, and operations teams to work more effectively together.
Career Value and Industry Recognition of the Certification
One of the key reasons professionals pursue this certification is its industry recognition. Google is widely regarded as a leader in cloud computing and machine learning infrastructure. As a result, certifications associated with its platform carry significant credibility in the job market.
Employers often view the certification as evidence that a candidate possesses practical skills in designing and deploying machine learning systems using cloud infrastructure. This is particularly valuable in organizations that already rely on Google Cloud or are transitioning to cloud-based machine learning systems.
The certification can also serve as a differentiator in competitive job markets. As machine learning becomes more widely adopted, the number of professionals entering the field continues to grow. Certifications that validate advanced, production-level skills help candidates stand out.
In addition to improving job prospects, the certification can also contribute to career progression. Professionals who hold it are often considered for more advanced roles involving system architecture, infrastructure design, and machine learning operations.
The Depth of Knowledge Required for the Certification
The Google Professional Machine Learning Engineer certification is designed for experienced professionals rather than beginners. It requires a deep understanding of both machine learning concepts and cloud engineering practices.
Candidates must be familiar with the entire machine learning lifecycle, including data ingestion, preprocessing, model training, evaluation, deployment, and monitoring. Each of these stages involves complex technical considerations that must be understood in detail.
In addition, candidates must understand how to work with distributed systems, cloud storage, and scalable computing resources. These skills are essential for building systems that can handle real-world workloads.
The certification also evaluates understanding of system design principles. This includes the ability to design architectures that are modular, scalable, and resilient. Engineers must be able to make decisions about how different components of a system interact and how to optimize performance across the entire pipeline.
Real-World Application of Machine Learning Engineering Skills
The skills tested in the certification are directly applicable to real-world machine learning systems. In practical environments, engineers are often responsible for building end-to-end solutions that go beyond model development.
For example, a machine learning engineer might be tasked with building a recommendation system for an e-commerce platform. This would involve collecting user data, designing features, training models, deploying them into production, and continuously monitoring performance.
Each step of this process requires careful engineering decisions. Data must be processed efficiently, models must be optimized for performance, and systems must be designed to handle large-scale traffic.
Another example could be a fraud detection system in financial services. Such a system must operate in real time, processing transactions as they occur and identifying potentially fraudulent activity within milliseconds. This requires highly optimized models, low-latency infrastructure, and robust monitoring systems.
These examples illustrate why machine learning engineering is considered a highly practical discipline. It is not limited to theoretical knowledge but requires the ability to build systems that function reliably in dynamic environments.
The Importance of Cloud-Native Machine Learning Systems
Cloud-native machine learning refers to systems that are built specifically to operate within cloud environments. These systems are designed to take advantage of cloud infrastructure features such as scalability, distributed computing, and managed services.
One of the key benefits of cloud-native systems is flexibility. Engineers can quickly scale resources up or down based on demand, allowing systems to handle varying workloads efficiently.
Another advantage is accessibility. Cloud platforms provide centralized environments where teams can collaborate on data, models, and infrastructure without being limited by physical hardware constraints.
Cloud-native systems also support automation and integration. Machine learning pipelines can be integrated with other cloud services such as data storage, analytics, and application hosting, creating a unified ecosystem.
The certification emphasizes cloud-native principles because they are essential for building modern machine learning systems that are efficient, scalable, and maintainable.
Challenges in Building and Maintaining Machine Learning Systems
Despite the advancements in tools and infrastructure, building machine learning systems remains a complex task. One of the main challenges is managing data complexity. Data often comes from multiple sources and may be inconsistent or incomplete.
Another challenge is model degradation over time. Machine learning models are trained on historical data, but real-world data changes continuously. This can lead to performance degradation if models are not regularly updated.
Scalability is also a major challenge. As systems grow, they must handle increasing amounts of data and user requests without sacrificing performance. This requires careful system design and resource management.
In addition, ensuring fairness and ethical behavior in machine learning systems is becoming increasingly important. Engineers must be aware of potential biases in data and take steps to mitigate them.
Monitoring and Maintenance as Continuous Processes
Machine learning systems require continuous monitoring to ensure they remain effective over time. Monitoring involves tracking performance metrics, detecting anomalies, and identifying potential issues before they impact users.
Maintenance includes updating models, retraining them with new data, and optimizing system performance. These tasks are ongoing and require structured workflows to manage effectively.
In many cases, automated monitoring systems are used to detect changes in data patterns or performance metrics. When issues are detected, alerts are generated, and corrective actions are taken.
This continuous approach ensures that machine learning systems remain reliable and accurate even as conditions change.
Organizational Impact of Machine Learning Engineering
Machine learning engineering has a significant impact on organizational decision-making and operational efficiency. By automating complex tasks and providing data-driven insights, machine learning systems enable organizations to operate more effectively.
In many industries, machine learning is used to improve customer experiences, optimize supply chains, and enhance decision-making processes. These improvements can lead to increased revenue, reduced costs, and improved service quality.
The role of machine learning engineers is therefore not limited to technical contributions. They also play a strategic role in enabling organizations to leverage data more effectively.
Long-Term Relevance of Machine Learning Engineering Skills
The demand for machine learning engineering skills is expected to continue growing as more organizations adopt artificial intelligence technologies. As systems become more complex, the need for professionals who can design, build, and maintain these systems will increase.
Cloud platforms will continue to play a central role in this evolution, making cloud-based machine learning expertise increasingly valuable.
The skills validated by the Google Professional Machine Learning Engineer certification are likely to remain relevant as long as machine learning systems continue to be used in production environments.
The Expanding Scope of Machine Learning in Enterprise Systems
Machine learning is no longer confined to experimental projects or isolated analytical tools. It has become deeply embedded in enterprise systems that power decision-making, automation, and customer experiences at scale. In modern organizations, machine learning is used across nearly every operational layer, from backend data processing to customer-facing applications.
This expansion has created a demand for professionals who understand not only how to build models but also how to integrate them into complex enterprise ecosystems. Machine learning engineers are now expected to work across multiple domains, including data engineering, software development, infrastructure management, and system design.
The Google Professional Machine Learning Engineer certification aligns closely with this shift. It reflects the need for engineers who can operate in cross-functional environments and contribute to large-scale systems that require coordination between multiple technical teams.
Machine Learning as a Core Business Infrastructure Component
One of the most significant changes in recent years is the transformation of machine learning from an optional enhancement into a core infrastructure component. Many organizations now rely on machine learning systems for essential business functions such as demand forecasting, risk assessment, personalization, and anomaly detection.
This means that machine learning systems are no longer experimental or supplementary; they are mission-critical. As a result, reliability, scalability, and performance are no longer optional features—they are mandatory requirements.
Engineers working in this space must ensure that systems can operate continuously without failure. Even minor disruptions can have significant financial or operational consequences. This elevates the importance of engineering discipline, system monitoring, and robust deployment strategies.
The certification indirectly reflects this reality by emphasizing production readiness and system reliability rather than purely theoretical understanding.
The Increasing Importance of Automation in Machine Learning Workflows
Automation has become one of the most defining characteristics of modern machine learning systems. As datasets grow larger and workflows become more complex, manual processes are no longer sustainable.
Automated pipelines are used to handle everything from data ingestion to model retraining. These pipelines ensure consistency and reduce the likelihood of human error. They also allow organizations to scale their machine learning operations without requiring proportional increases in engineering resources.
Automation also enables continuous improvement. Models can be retrained automatically when new data becomes available, ensuring that systems remain up to date with minimal manual intervention.
This level of automation requires careful design and orchestration. Engineers must ensure that each component of the pipeline is reliable, efficient, and capable of handling failures gracefully. The certification emphasizes these skills because they are essential for building scalable machine learning systems in real-world environments.
The Future Direction of Machine Learning Engineering Roles
The role of machine learning engineers is expected to continue evolving as technology advances. One emerging trend is the integration of machine learning with other advanced technologies such as edge computing, Internet of Things (IoT), and generative AI systems.
Edge computing, for example, involves running machine learning models directly on devices rather than centralized servers. This reduces latency and enables real-time decision-making in environments such as autonomous vehicles and smart devices.
Generative AI is another rapidly growing area that is changing how machine learning systems are designed and used. These models can generate text, images, and other types of content, opening new possibilities for applications across industries.
As these technologies evolve, machine learning engineers will need to adapt their skills and understanding to remain effective in building modern systems.
The skills validated by the Google Professional Machine Learning Engineer certification contribute to this growth by providing a structured foundation in both machine learning concepts and cloud-based engineering practices.
Conclusion
The Google Professional Machine Learning Engineer certification reflects how deeply machine learning has become embedded in modern technology systems and how significantly the role of engineers has evolved. It is no longer enough to simply understand algorithms or build isolated models in experimental environments. Today, organizations require professionals who can design, deploy, and maintain full-scale machine learning systems that operate reliably in production, handle real-world data complexity, and integrate seamlessly with cloud infrastructure.
Across industries, machine learning is now a core driver of decision-making, automation, and user experience. This shift has elevated the importance of production-ready engineering skills, particularly in areas such as MLOps, system architecture, scalability, and monitoring. The certification aligns closely with these demands by focusing on practical, cloud-based implementation using Google Cloud technologies and emphasizing lifecycle management over theoretical knowledge alone.
For experienced data scientists, software engineers, and machine learning practitioners, the certification can serve as a structured validation of advanced capabilities. It demonstrates the ability to move beyond experimentation and contribute to real-world systems that require stability, performance, and long-term maintainability. At the same time, it highlights the importance of collaboration across teams, responsible AI practices, and continuous system improvement.
However, its true value depends on the individual’s goals and experience level. For those already working in machine learning or cloud environments, it can strengthen career progression and open doors to more specialized or senior roles. For newcomers, it may serve as a challenging but insightful roadmap into the realities of production-grade machine learning engineering.
Ultimately, the certification represents more than just an exam. It reflects a broader industry transformation where machine learning is becoming a foundational component of modern infrastructure. As this transformation continues, professionals who can bridge the gap between data, models, and scalable systems will remain in high demand, making this skill set increasingly relevant for the future of technology.