Modern technology environments rely on constant availability, consistent performance, and predictable behavior. Whether an organization runs a small internal server or a globally distributed cloud platform, infrastructure must be watched carefully. Systems can fail quietly, network latency can rise slowly, and security controls can drift over time without immediate warning. Traditional monitoring methods often focus on collecting metrics and sending alerts after something has already started going wrong. While useful, that approach can leave gaps in visibility.
A test-driven mindset offers a stronger model for monitoring infrastructure. Instead of waiting for failures to appear in dashboards, teams define expectations in advance and continuously verify that those expectations remain true. In practical terms, this means creating automated checks that ask specific questions. Is the gateway responding within an acceptable time? Is a website returning the correct status code? Are firewall rules unchanged? Is resource usage increasing beyond approved limits? Each of these questions becomes a test.
This shift is powerful because it transforms monitoring from passive observation into active validation. Rather than only collecting data, teams assert how systems should behave. If behavior changes, the failure is detected quickly and clearly. This method also creates living documentation. Every test represents an operational requirement, a performance target, or a security expectation. New administrators can understand the environment by reading the tests rather than searching through scattered notes or outdated documents.
The test-driven model also improves consistency. Human checks are often irregular, subjective, and easy to forget. An engineer might manually verify a service after a deployment, but the next engineer may use a different method or skip the task entirely. Automated tests run the same way every time. They do not become distracted, rushed, or inconsistent. This repeatability is especially valuable in environments where small changes can have large downstream effects.
Another major advantage is speed. Automated tests can run on schedules, during deployments, after maintenance windows, or in response to detected changes. Instead of discovering problems hours later through user complaints, teams can receive immediate feedback. The faster a problem is identified, the smaller the impact tends to be. Early detection often prevents minor issues from becoming widespread outages.
A test-driven monitoring approach also supports growth. As environments expand, manual oversight becomes unrealistic. One server can be checked by hand. Hundreds of systems across multiple regions cannot. Automated validation scales naturally. New assets can inherit existing checks, and new tests can be added as the environment evolves.
This way of thinking also encourages stronger engineering discipline. When teams define expectations explicitly, they are forced to ask valuable questions. What is acceptable latency? Which ports must remain open? Which configuration values are critical? How much cost increase is normal? These discussions help align technical operations with business priorities.
Infrastructure monitoring becomes more meaningful when it is built around intent. Metrics show what is happening. Tests help explain whether what is happening is acceptable. That distinction is essential. A server using high memory may be normal during a backup window. A website returning success codes may still be too slow for users. Automated tests allow teams to encode context rather than relying only on raw numbers.
The result is a more reliable, understandable, and maintainable environment. Monitoring stops being a disconnected set of alerts and becomes an organized system of expectations. That is the foundation of modern infrastructure assurance.
Why PowerShell Is Well Suited for Operational Validation
PowerShell has become one of the most practical tools for infrastructure management because it combines scripting flexibility with deep administrative access. It can interact with operating systems, services, files, networks, APIs, cloud resources, and security settings through a consistent command model. That makes it especially useful for monitoring and validation tasks.
One reason PowerShell fits infrastructure testing so well is that it works naturally with structured data. Many administrative tasks involve reading outputs, comparing values, and making decisions based on system state. PowerShell objects make those operations cleaner and more reliable than plain text processing. Instead of searching strings manually, administrators can access named properties and perform precise checks.
This object-oriented approach matters when monitoring systems. If you want to inspect service status, measure response times, examine certificates, or query event logs, structured output reduces ambiguity. Scripts become easier to read and less fragile. That is important when tests need to run regularly without constant maintenance.
PowerShell is also highly portable across environments. It began as a Windows administration platform, but modern versions support multiple operating systems. Organizations with mixed environments can use a consistent automation language across servers, cloud workloads, and management workstations. This reduces the need to maintain separate tooling for different platforms.
Another strength is accessibility. Many administrators already use PowerShell for common tasks such as managing files, users, permissions, or services. Extending those existing skills into testing and monitoring is often easier than adopting an entirely new framework. Teams can build on familiar concepts instead of starting from scratch.
PowerShell also integrates well with scheduled execution and automation pipelines. Scripts can run on intervals, after deployments, during compliance scans, or as part of incident response workflows. This means infrastructure tests can be embedded into daily operations rather than treated as separate manual activities.
Visibility is another advantage. PowerShell can generate readable reports, logs, and status outputs. Operational teams often need to share results with managers, auditors, or engineers outside the scripting team. Clear output improves communication and speeds decision-making.
Because PowerShell can connect to remote systems, it also supports centralized validation. Rather than logging into many machines individually, teams can execute checks across multiple systems from a single management point. This saves time and creates a more unified monitoring process.
The language is also highly extensible. Modules add capabilities for cloud platforms, virtualization systems, networking devices, identity platforms, and security tools. As infrastructure grows more diverse, this modular ecosystem allows teams to continue using the same core automation approach while expanding into new domains.
From a governance perspective, PowerShell helps standardize operations. Instead of each administrator checking systems differently, teams can agree on shared scripts and approved tests. This reduces tribal knowledge and lowers the risk created by inconsistent manual habits.
Most importantly, PowerShell supports the transition from reactive administration to proactive engineering. It allows teams not only to fix issues when they happen, but to continuously validate that systems remain healthy, compliant, and performant. That makes it a valuable foundation for modern infrastructure monitoring.
The Role of Pester in Automated Infrastructure Assurance
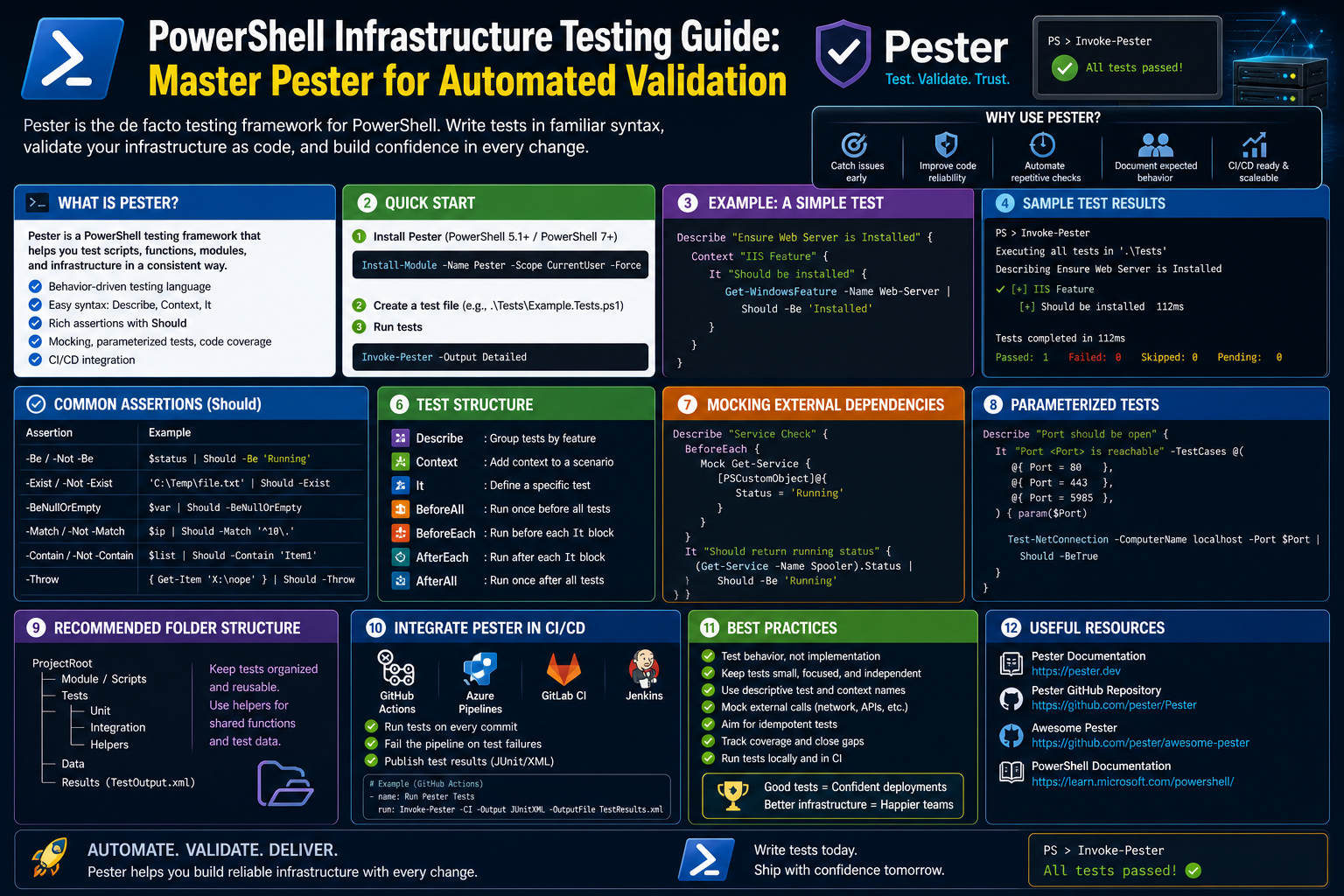
Pester is widely recognized as a testing framework associated with PowerShell, but its value reaches far beyond application scripting. It provides a structured way to define expectations and verify outcomes, which makes it highly effective for infrastructure assurance.
At its core, Pester allows teams to express operational rules as tests. Instead of saying “the website should respond quickly,” a team can define an automated check that confirms the site responds within an approved threshold. Instead of assuming firewall settings remain unchanged, a test can compare current rules against expected baselines. Instead of manually reviewing cloud spending, a test can flag abnormal cost growth.
This structure is important because operational knowledge is often vague or undocumented. Experienced engineers may know what “normal” looks like, but that knowledge can remain trapped in memory. Pester turns that experience into repeatable checks that anyone on the team can run and understand.
Another major strength is readability. Well-written tests describe intent clearly. Someone reviewing a test suite can often understand the environment’s expectations even without deep platform knowledge. This turns tests into documentation that stays relevant because it must remain accurate to pass.
Pester also improves trust in automation. Some organizations hesitate to automate monitoring because they fear hidden logic or difficult maintenance. A test framework creates clear pass-or-fail outcomes and organizes checks in predictable ways. This transparency encourages adoption.
Consistency is another benefit. Without a framework, scripts often evolve into loosely connected checks with mixed output styles and unclear error handling. Pester provides structure so tests are grouped logically and results are easier to interpret. That organization becomes increasingly valuable as the number of checks grows.
Because Pester supports assertions, teams can compare expected versus actual outcomes directly. This is central to useful monitoring. A server being reachable is not enough if response time is too slow. A certificate existing is not enough if expiration is near. Assertions help define acceptable states rather than binary existence checks.
The framework also supports maintenance through version control. Infrastructure tests stored as files can be reviewed, updated, approved, and rolled back like any other managed asset. This creates accountability and historical visibility. Teams can see when thresholds changed, when new controls were added, or when outdated checks were removed.
Pester is equally useful during change management. Before and after maintenance work, teams can run test suites to confirm that essential services still behave correctly. This reduces uncertainty after updates, migrations, or security changes.
In incident response, Pester can help narrow investigation scope. If only certain tests fail, responders can quickly identify which layer of infrastructure is affected. If network latency checks fail but service availability checks pass, the issue may differ from a full outage scenario.
Another advantage is cultural. Testing frameworks encourage teams to think in terms of standards and evidence. Instead of debating whether something “looks fine,” engineers can rely on measurable checks. This reduces subjective troubleshooting and supports more professional operations.
Used effectively, Pester transforms infrastructure monitoring into a disciplined engineering practice. Systems are no longer trusted simply because no one has complained yet. They are trusted because defined expectations are continuously verified.
Building Better Visibility with Network Response Testing
One of the most common and useful infrastructure checks involves network responsiveness. Connectivity issues often appear before complete outages. Latency may rise, packet loss may increase, or routes may become unstable while systems still technically respond. Monitoring these early signals helps teams act before users experience serious disruption.
Testing connectivity to a default gateway is a practical example. The gateway is a critical path between local systems and wider networks. If it becomes slow or unreachable, many services may degrade simultaneously. Automated checks against gateway responsiveness can reveal switching issues, overloaded devices, interface problems, or broader network congestion.
Latency thresholds are especially important. A gateway that responds eventually may still be unhealthy if response time rises beyond normal levels. By defining acceptable milliseconds and testing regularly, teams can detect performance deterioration early.
These checks are valuable because they are simple yet informative. They do not require deep packet analysis or expensive tools to provide useful signals. Regular response testing creates a baseline of normal behavior. Once baselines are known, unusual trends become easier to recognize.
Network response testing also helps distinguish infrastructure problems from application problems. If users report slowness but gateway and upstream latency remain healthy, the issue may lie elsewhere. If latency is elevated across multiple tests, network conditions become a stronger suspect.
Distributed environments benefit even more. Different sites, regions, or offices can run localized checks and report centrally. This helps teams see whether issues are isolated or widespread. A single failing location may indicate local connectivity problems, while broad failures suggest upstream outages.
Historical trends are another benefit. Short spikes may be tolerable, but gradual latency growth over weeks can indicate saturation or aging infrastructure. Test data supports capacity planning and investment decisions.
Regular response validation also helps after changes. If latency increases immediately after firewall updates, routing changes, or equipment replacement, the correlation becomes visible quickly. This shortens troubleshooting time.
For remote workforces and branch offices, network tests can confirm whether essential paths remain healthy enough for voice, video, and cloud applications. User complaints often arrive after frustration builds. Automated checks surface issues sooner.
When combined with other monitoring signals, response testing becomes even stronger. A website slowdown paired with network latency alerts tells a clearer story than either signal alone. Infrastructure monitoring works best when tests reinforce one another.
Reliable operations depend on more than uptime. Performance matters, and network responsiveness is one of the clearest indicators of real user experience. Continuous testing of that responsiveness helps organizations protect both productivity and trust.
Moving from Manual Checks to Continuous Confidence
Many teams begin infrastructure monitoring with manual habits. Someone logs into a server to confirm a service is running. Someone opens a browser to verify a site loads. Someone checks firewall settings after maintenance. These actions may work in small environments, but they do not scale and rarely provide lasting confidence.
Manual checks are inconsistent by nature. Different people use different methods. Some verify deeply, others glance quickly. Some record findings, others do not. Timing also varies. Important systems may go unchecked for long periods simply because everyone assumed someone else looked already.
Automated testing changes that dynamic. Checks run on schedule, use the same logic every time, and produce repeatable evidence. Confidence comes not from assumption but from verification.
This shift also reduces operational stress. Teams no longer need to remember dozens of routine checks or scramble after every change window. Known tests can run automatically, allowing engineers to focus on improvement rather than repetitive confirmation.
Continuous confidence does not mean systems never fail. It means failures are discovered faster, diagnosed more clearly, and understood in context. That is a far stronger operating model than reactive firefighting.
As organizations modernize, the ability to express expectations as tests becomes a strategic advantage. It improves resilience, onboarding, compliance, performance management, and change safety. Most importantly, it turns infrastructure from something merely maintained into something continuously validated.
Designing Reliable Infrastructure Tests That Reflect Real Operations
Once a team understands the value of automated monitoring, the next challenge is creating tests that truly represent operational reality. Many organizations begin with enthusiasm, build a few basic checks, and then discover that some tests are noisy, unclear, or too shallow to be useful. Effective infrastructure testing requires thoughtful design. A good test should reveal meaningful information, support quick decisions, and align with how systems are expected to behave in the real world.
The first principle is relevance. Every test should answer an important question. If a check exists only because it is easy to create, it may clutter results without delivering value. For example, verifying that a server responds to a simple request can be useful, but if the business depends on database transactions, authentication, and secure connectivity, then a basic reachability test alone does not reflect real service health. Teams should focus on tests that matter to users, operations, security, or cost control.
Useful tests are also specific. A vague check that says a service is “working” is less helpful than one that verifies response time, expected output, dependency access, and acceptable behavior under normal load. Specificity helps teams understand what failed and why it matters. If a production website responds but returns an error page, a simple availability check may pass while users remain blocked. More precise validation prevents false confidence.
Another key factor is measurable thresholds. Infrastructure teams often use informal language such as “fast enough,” “normal,” or “not too high.” Those phrases are difficult to automate because they are subjective. Good tests replace ambiguity with defined expectations. A network gateway may need to respond under a certain number of milliseconds. CPU utilization may remain acceptable within a certain range during business hours. Storage growth may require attention after crossing a defined level. Quantified expectations create clearer monitoring and more useful alerts.
Tests should also reflect service priorities. Not every system needs the same level of scrutiny. A public customer-facing platform deserves more frequent and detailed checks than a low-impact internal utility. Critical systems may need layered tests covering availability, latency, dependencies, certificate validity, configuration drift, and resource usage. Less critical systems can use lighter monitoring. This prioritization prevents wasted effort and ensures attention goes where risk is highest.
Reliability in test design also means avoiding brittle logic. Some checks fail too easily because they depend on changing values that are not truly problematic. For instance, a dynamic cloud environment may legitimately create and remove resources throughout the day. A rigid inventory comparison may generate constant false alarms. Strong tests distinguish between authorized change and unexpected drift.
Another common mistake is over-monitoring symptoms instead of validating outcomes. A process running does not always mean a service is healthy. A port being open does not guarantee application success. A server with normal CPU usage may still deliver poor user experience. Whenever possible, tests should measure end results rather than only component presence.
Good infrastructure tests are also understandable to humans. If only the original author can interpret a failing result, the test loses value. Names, descriptions, and outputs should clearly explain what expectation was checked and what went wrong. During an incident, clarity saves time.
Review cycles are equally important. Infrastructure changes constantly, and tests must evolve with it. Thresholds that made sense six months ago may no longer fit current workloads. Retired services may still trigger outdated checks. New business dependencies may be unmonitored. Periodic review ensures test suites remain aligned with reality.
Reliable testing also depends on ownership. Each test should have someone or some team responsible for its accuracy. When nobody owns a check, it often becomes stale. Ownership encourages maintenance, relevance, and trust in results.
Finally, good tests should lead to action. If a failing alert appears repeatedly but no one responds, the check is not creating value. Either the threshold is wrong, the issue is tolerated, or the response process is broken. Useful monitoring drives decisions and improvement.
Designing meaningful tests takes more effort than creating quick scripts, but that investment pays off. Strong tests become a dependable operating layer that helps teams understand infrastructure health in real time and manage change with confidence.
Monitoring Web Services Through Response Validation
Modern organizations depend heavily on web-based systems. Internal portals, APIs, public websites, dashboards, and software platforms often serve as the front door to business operations. Because of this, validating web service health is one of the most practical uses of automated infrastructure testing.
Many teams begin by checking whether a site responds at all. While basic reachability has value, true service monitoring should go further. A site may technically respond while users experience errors, delays, incomplete content, or failed transactions. Response validation means testing whether a service behaves correctly, not merely whether it exists.
One of the simplest indicators is status code behavior. When a healthy service receives a standard request, it should return the expected success response. Unexpected redirects, permission failures, or server-side errors may indicate application issues, misconfigurations, expired credentials, or dependency failures. Monitoring these responses gives teams rapid insight into service condition.
Performance is equally important. A page that loads successfully after a long delay can damage user trust as much as a short outage. Slow systems frustrate customers, interrupt employees, and increase abandonment rates. Measuring response times helps teams detect degradation early, especially when performance worsens gradually rather than failing suddenly.
Response content can also be validated. Some systems return a success code even when displaying an internal error page. Others may serve maintenance placeholders or broken partial content. By checking for expected text, data markers, or known behaviors, teams gain stronger confidence that services are actually functioning.
Authentication workflows deserve attention as well. Many business systems depend on identity providers, tokens, or session management. If login systems fail, users may perceive the entire platform as unavailable. Automated validation of access flows can reveal issues in identity integrations before support queues fill.
Monitoring should also consider dependencies. A web application often relies on databases, storage platforms, messaging systems, third-party APIs, or internal services. The front-end page may load while core features fail silently. Broader validation scenarios that test functional pathways provide more realistic health signals.
Geographic perspective matters for public services. A platform may perform well from one region while suffering latency or routing issues elsewhere. Distributed response testing helps identify location-specific problems that centralized checks can miss.
Scheduled validation after deployments is another major benefit. Software releases, configuration changes, certificate renewals, and infrastructure updates all create risk. Immediate automated checks after changes help confirm that key endpoints still behave correctly. This reduces the time between defect introduction and detection.
Historical trend analysis can reveal hidden problems. If response times worsen every Monday morning or spike during monthly reporting cycles, capacity planning may be needed. If errors rise after each deployment, release processes may need improvement. Monitoring becomes more valuable when used for learning rather than only alerting.
Well-designed web monitoring also improves communication across teams. Operations, developers, security teams, and business leaders often interpret system health differently. Clear automated checks provide a shared evidence source. Instead of debating whether users are impacted, teams can examine consistent test results.
User experience should remain the guiding principle. Monitoring that reflects real customer journeys is more valuable than technical checks disconnected from business outcomes. If users search products, upload files, view dashboards, or submit forms, those paths deserve validation.
In fast-moving environments, web services change often. New features, architecture updates, and scaling events create constant motion. Automated response validation helps organizations innovate without sacrificing confidence. It turns uncertainty into measurable visibility and allows teams to move faster with less risk.
Detecting Configuration Drift Before It Causes Problems
Infrastructure rarely fails only because hardware breaks. Many incidents begin with small configuration changes that seemed harmless at the time. A firewall rule is edited, a service startup mode changes, permissions are adjusted, or a network route is modified. Individually these changes may appear minor, but together they can create outages, security gaps, or unstable behavior. Detecting configuration drift is therefore a critical part of infrastructure testing.
Configuration drift occurs when systems gradually move away from their intended state. Sometimes this happens through emergency fixes made under pressure. Sometimes it results from manual changes that were never documented. In dynamic environments, temporary exceptions can become permanent simply because nobody revisits them. Over time, servers that should be identical behave differently, security controls weaken, and troubleshooting becomes harder.
Automated testing helps by continuously comparing reality against expectations. If firewall rules differ from approved baselines, teams can investigate quickly. If required services are disabled, if key registry values change, or if important policies disappear, tests surface those deviations early.
This matters because drift often remains invisible until something breaks. A modified access rule may not cause problems immediately, but months later it may block a new application dependency. An outdated configuration on one node may only fail during peak traffic when load balancing shifts demand. Early detection reduces surprise.
Configuration validation also strengthens security posture. Unauthorized ports, weak settings, disabled logging, and missing protections can appear through well-intentioned shortcuts or forgotten experiments. Regular checks create accountability and reduce the lifespan of risky changes.
Consistency across environments is another major benefit. Development, testing, staging, and production systems often need comparable settings to ensure smooth releases. If environments diverge too much, deployments that worked elsewhere may fail in production. Automated comparisons help preserve alignment.
Drift detection supports faster troubleshooting as well. When an issue appears, one of the first questions is often “what changed?” If tests already track expected state, unusual differences become easier to spot. This shortens investigation time and lowers operational stress.
The process also improves documentation quality. Many teams struggle with outdated diagrams and incomplete runbooks. Test definitions effectively become living standards. They describe what the system should look like in operational terms rather than static prose.
Not every difference is harmful, so context matters. Some systems legitimately require custom settings. Effective drift monitoring distinguishes approved exceptions from unknown deviations. This is where ownership and review processes become important.
Configuration checks are especially valuable after maintenance windows. Patch cycles, migrations, vendor upgrades, and emergency changes all introduce risk. Running validation afterward confirms that essential standards still hold.
Cloud environments introduce additional drift challenges because resources can be created quickly and frequently. Identity permissions, storage policies, network controls, tagging standards, and backup settings may change rapidly. Automated governance checks become essential in such settings.
When organizations ignore drift, they often accumulate silent risk. Systems still appear operational, but resilience and security gradually weaken. By the time failure occurs, the root cause may have existed for months.
Continuous validation reverses that pattern. Instead of learning about configuration issues through incidents, teams learn through tests. That difference can save time, money, and trust.
Using Performance Thresholds to Protect User Experience
Availability alone is no longer enough. A system that technically remains online but responds slowly can still damage productivity, customer satisfaction, and revenue. For this reason, performance thresholds are a central component of mature infrastructure monitoring.
Threshold-based testing means defining what acceptable performance looks like and measuring systems against that expectation. This could involve network latency, API response time, storage delays, query duration, authentication speed, or page load times. By setting limits, teams turn vague perceptions of slowness into measurable standards.
One advantage of thresholds is earlier detection. Users often tolerate minor slowdowns at first and report issues only when frustration builds. Automated checks notice deterioration immediately. A response time that doubles overnight may signal capacity pressure, code inefficiency, dependency problems, or network congestion even before complaints begin.
Thresholds also help prioritize alerts. Not every fluctuation deserves emergency action. Systems naturally vary under changing load. Defined limits help distinguish ordinary variation from meaningful degradation. This reduces unnecessary escalations while still protecting service quality.
Business context should guide threshold choices. A real-time trading platform may need extremely low latency. An internal archival tool may tolerate slower performance. Matching expectations to business impact prevents both overreaction and underprotection.
Performance monitoring is also valuable during growth. As user counts rise, workloads increase, or new features launch, thresholds can reveal when infrastructure is nearing limits. Teams gain time to scale resources, optimize architecture, or adjust schedules before major incidents occur.
After changes, thresholds provide objective validation. If a software release improves speed, metrics confirm success. If a patch introduces delays, tests expose the regression quickly. This creates a healthier improvement cycle based on evidence rather than assumptions.
User experience often depends on chains of systems rather than one component. A slow login may involve directory services, network paths, application logic, and databases. Threshold testing across multiple layers helps identify where delays begin.
Historical data makes thresholds even stronger. Seasonal traffic patterns, reporting deadlines, and promotional events may predictably stress systems. Knowing these patterns allows smarter thresholds and better preparation.
Organizations that ignore performance until outages occur often suffer avoidable reputational damage. Users judge systems by responsiveness, not just uptime. Continuous performance validation helps ensure services remain pleasant and productive to use.
Controlling Operational Costs Through Automated Checks
Infrastructure monitoring is commonly associated with uptime and security, but cost control is increasingly important. In cloud and hybrid environments, spending can rise quickly through idle resources, oversized systems, forgotten storage, unnecessary data transfer, or uncontrolled scaling. Automated tests can help keep financial risk visible.
One of the strongest benefits is early warning. Small daily waste may seem insignificant, but over weeks and months it becomes substantial. Regular checks that compare spending trends, resource counts, or usage patterns against expectations help teams intervene sooner.
Unused resources are a common source of waste. Temporary test systems may be left running, old disks may remain attached, snapshots may accumulate, and redundant services may continue consuming budget. Automated validation can identify these patterns consistently.
Rightsizing is another opportunity. Systems provisioned for past peak demand may now be oversized. Monitoring usage against allocated capacity can highlight where reductions are safe.
Tagging and ownership checks matter too. When resources lack clear ownership, waste persists because nobody feels responsible. Automated governance tests that validate naming, tagging, or cost-center alignment improve accountability.
Cost monitoring should be collaborative rather than punitive. Engineers need visibility into spending impacts so they can design efficiently. Finance teams need technical context to understand why costs change. Shared automated signals support better decisions across both groups.
Rapid growth environments benefit especially from this approach. When teams can launch resources quickly, they also need guardrails that prevent accidental overspend. Automated cost checks create those guardrails without blocking innovation.
Unexpected spikes may also indicate security issues, such as abused compute resources or unauthorized workloads. Financial anomalies sometimes reveal operational anomalies.
By treating cost as another measurable infrastructure outcome, organizations build healthier operations. Efficiency becomes continuous rather than reactive.
Turning Test Results Into Daily Operational Discipline
Automated checks only create value when their results influence behavior. Some teams build impressive monitoring suites but fail to integrate them into everyday operations. Alerts are ignored, reports go unread, and recurring failures become background noise. To realize full benefits, test outcomes must become part of operational discipline.
The first step is visibility. Results should be easy to access and understand. Engineers need concise signals, not confusing floods of raw output. Clear pass, fail, trend, and severity indicators support faster action.
Second is ownership. Every important alert should route to someone empowered to respond. Unowned failures tend to persist. Defined responsibility creates accountability and resolution momentum.
Third is routine review. Daily standups, shift handovers, weekly operations meetings, and change advisory discussions should include monitoring insights. Repeated failures may indicate structural issues rather than isolated events.
Fourth is learning. When incidents occur, teams should ask whether existing tests could have detected the issue sooner or more clearly. If not, new validations can be added. Monitoring should improve after every disruption.
Fifth is noise reduction. Alerts that never matter erode trust. Thresholds, logic, and schedules should be refined continuously so failures are meaningful.
Finally, success should be recognized. Reliable systems often appear invisible because nothing goes wrong. Strong monitoring helps create that stability. Acknowledging the discipline behind quiet operations reinforces good engineering culture.
When test results become part of daily habits, infrastructure monitoring evolves from a toolset into an operating model. Systems are not merely watched—they are continuously understood, improved, and managed with intent.
Building a Long-Term Culture of Infrastructure Reliability
Automated infrastructure testing delivers the greatest value when it becomes part of an organization’s culture rather than a short-term technical project. Many teams begin by creating a few checks for urgent pain points such as website outages, slow network links, or inconsistent server settings. Those early wins are useful, but long-term success depends on embedding testing into everyday operations, planning, and decision-making.
A reliability-focused culture starts with shared expectations. Operations teams, developers, security staff, and leadership should all understand what healthy systems look like. That includes uptime goals, acceptable response times, configuration standards, recovery expectations, and cost boundaries. When expectations are clear, automated tests become practical because they are measuring agreed standards rather than vague assumptions.
Another important factor is consistency during change. Infrastructure changes constantly through updates, migrations, scaling actions, new applications, and security improvements. Each change introduces risk. Teams that adopt routine testing before and after changes create a safer environment because problems are detected quickly. Instead of hoping an update worked, they verify essential services, dependencies, and performance immediately.
Documentation also improves significantly when tests are treated as operational assets. Traditional documentation often becomes outdated because it relies on manual updates. Automated tests, however, must stay current to remain useful. This naturally encourages more accurate records of system expectations, dependencies, and standards. New team members can learn faster by reviewing what the environment is designed to satisfy.
Strengthening Collaboration Across Technical Teams
Infrastructure reliability is rarely owned by one department alone. Modern services depend on networks, operating systems, identity platforms, databases, cloud resources, and applications working together. When failures occur, multiple teams may be involved. Automated testing creates a common language that helps collaboration.
Instead of debating whether an issue exists, teams can look at clear results. If authentication checks fail, identity teams gain immediate context. If response times rise while servers remain healthy, application or database teams may investigate further. Shared evidence reduces blame and speeds resolution.
Testing also encourages proactive conversations. For example, if a new service is being launched, teams can discuss which checks should exist from day one. They may define availability tests, certificate checks, backup validation, scaling thresholds, and security controls before the system goes live. This approach is far stronger than adding monitoring only after incidents occur.
Cross-team trust often grows when monitoring is transparent. Everyone can see what is being tested, how success is measured, and where gaps remain. That openness supports healthier operational relationships.
Improving Incident Response and Recovery
No environment is immune to incidents. Hardware fails, software bugs appear, external providers experience outages, and human mistakes happen. The difference between resilient teams and struggling teams is often how quickly they detect and recover from problems.
Automated tests shorten the time between issue creation and issue discovery. Rather than learning about failures through user complaints, teams receive signals based on real operational checks. This early awareness limits impact.
Tests can also narrow troubleshooting scope. If network connectivity checks pass but web response tests fail, investigators know where to focus first. If configuration drift alerts appeared shortly before an outage, recent changes become a strong lead. Faster diagnosis means faster restoration.
Recovery processes benefit as well. After services are restored, automated validation confirms whether systems truly returned to expected behavior. Without that confirmation, teams may reopen access while hidden issues remain unresolved.
Over time, incidents should feed improvement. After each event, teams can ask what additional checks might have reduced impact. This creates a continuous learning cycle where monitoring grows stronger with experience.
Preparing for Future Growth and Complexity
Technology environments rarely become simpler. Organizations expand, adopt new platforms, integrate more services, and face higher user expectations. Manual oversight becomes less realistic as complexity increases.
Automated infrastructure testing helps teams scale responsibly. New servers, cloud workloads, branch locations, or business applications can inherit proven validation patterns. Instead of reinventing monitoring for each addition, teams extend an established framework.
This is especially valuable in hybrid environments where on-premises systems, cloud platforms, and remote users all interact. Consistent testing across varied technologies creates unified visibility that would otherwise be difficult to achieve.
Future readiness also includes governance. Regulatory demands, audit expectations, and internal control standards often increase over time. When organizations already verify settings, access patterns, backups, and operational health through automated tests, adapting to stricter requirements becomes easier.
Making Reliability an Everyday Habit
The strongest infrastructure teams do not treat monitoring as a side task. They make reliability part of normal work. They review trends, refine thresholds, retire noisy checks, add tests for new risks, and use results to guide decisions.
This habit creates calmer operations. Fewer surprises occur because warning signs are caught early. Changes become safer because validation is routine. Knowledge spreads because expectations are visible. Teams spend less time reacting and more time improving.
Infrastructure testing with tools like PowerShell and Pester is not only about scripts or alerts. It is about building confidence that critical systems continue to perform as intended. In a world where digital services support nearly every business function, that confidence is one of the most valuable assets an organization can develop.
Conclusion
Reliable infrastructure does not happen by accident. It is the result of clear standards, consistent validation, and a willingness to improve systems continuously. As technology environments become larger and more complex, traditional manual checks are no longer enough to provide the level of confidence modern organizations need. Automated testing offers a smarter and more dependable path forward.
By applying a test-driven approach, teams can move beyond simply reacting to outages and begin preventing many issues before they grow into serious problems. Network response checks, web service validation, configuration drift detection, performance thresholds, and cost monitoring all contribute to a healthier operational environment. These checks turn assumptions into measurable facts and provide early warning when systems begin to move outside expected conditions.
Tools such as PowerShell and Pester make this process practical by allowing organizations to build repeatable, readable, and scalable validation workflows. As systems evolve, those tests can evolve alongside them, creating long-term resilience.
Ultimately, infrastructure monitoring is most effective when it becomes part of everyday operational discipline. Teams that continuously test, review, and refine their environments are better prepared for change, faster during incidents, and more confident in the services they deliver. In an era where digital reliability directly impacts trust and productivity, automated infrastructure testing is no longer optional—it is a strategic necessity.