Modern organizations generate and process massive amounts of data every second. From application logs and customer records to media files and backups, the demand for scalable and flexible storage has never been higher. Traditional on-premises storage systems often struggle to keep up with this growth due to limited capacity, high maintenance costs, and lack of scalability.
At the same time, cloud storage has emerged as a powerful alternative. It offers virtually unlimited capacity, pay-as-you-go pricing, and global accessibility. However, despite its advantages, cloud storage introduces its own set of challenges. One of the biggest difficulties is the mismatch between traditional applications and cloud storage interfaces.
Most enterprise applications are built to work with file-based or block-based storage protocols such as NFS, SMB/CIFS, or iSCSI. Cloud storage systems, on the other hand, typically rely on object-based interfaces like REST or SOAP APIs. This difference creates a compatibility gap that can slow down adoption and complicate integration.
Organizations often find themselves forced to redesign applications, rewrite storage logic, or introduce complex middleware solutions just to bridge this gap. This is where hybrid storage solutions become essential, offering a way to connect on-premises infrastructure with cloud environments in a seamless and efficient manner.
Introducing the Concept of a Storage Gateway
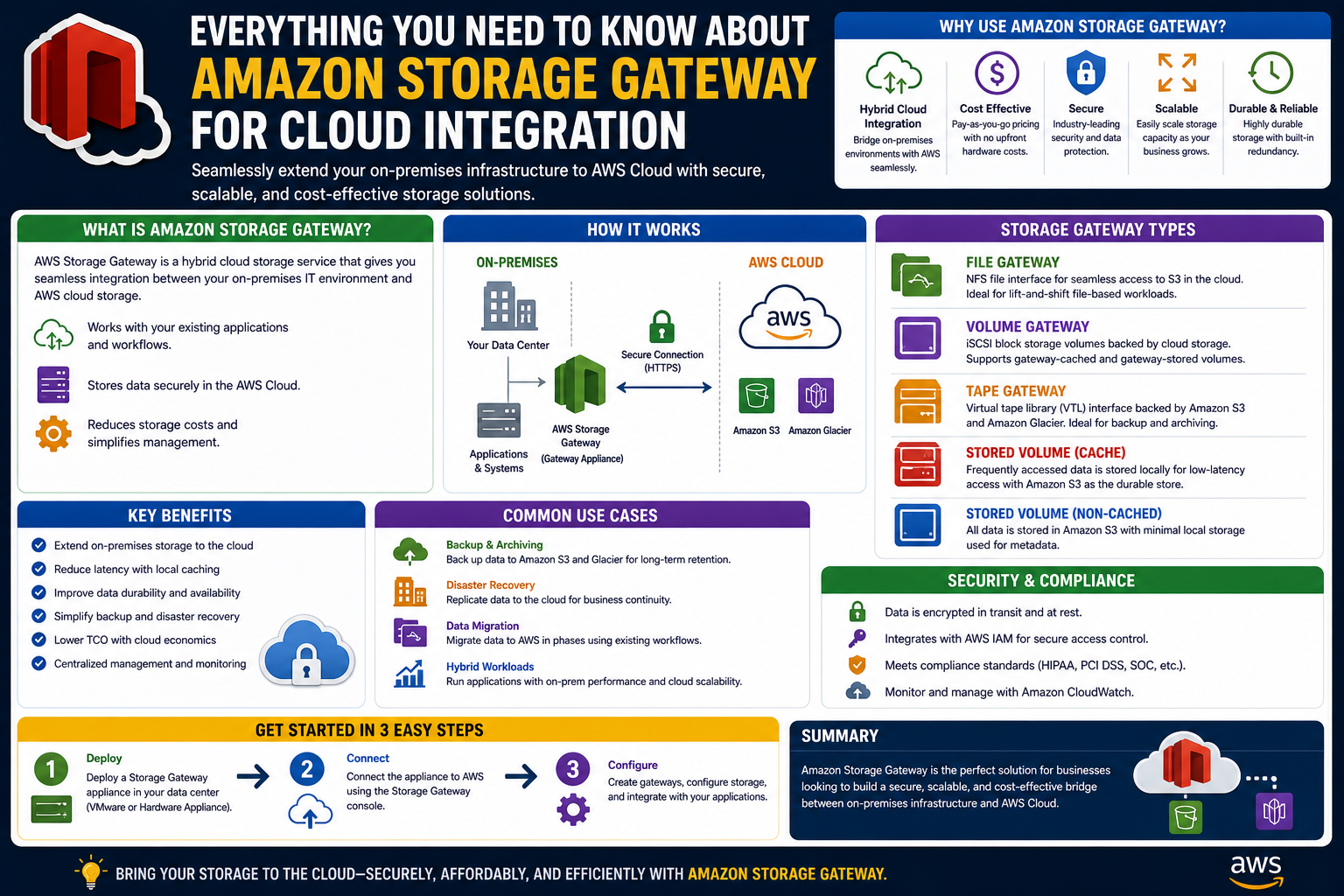
A storage gateway acts as a bridge between local infrastructure and cloud storage systems. Instead of forcing applications to communicate directly with cloud object storage, the gateway translates traditional storage requests into cloud-compatible operations.
In simple terms, it behaves like a translator sitting between two different languages. On one side, it speaks file and block protocols that applications understand. On the other side, it communicates with cloud storage services using object-based APIs.
This approach allows organizations to continue using their existing applications without modification while still benefiting from cloud storage capabilities. It reduces complexity, improves compatibility, and accelerates cloud adoption.
A storage gateway is typically deployed as a virtual appliance within an organization’s data center or virtualized environment. Once deployed, it becomes a local interface for storage operations while handling the backend communication with cloud services.
How AWS Storage Gateway Fits into Hybrid Cloud Architecture
The AWS Storage Gateway is designed specifically to simplify hybrid cloud storage environments. It connects on-premises systems to cloud storage services in a way that feels natural to existing infrastructure.
Instead of replacing local storage entirely, it extends it. Applications continue to interact with familiar storage protocols while the gateway manages synchronization, caching, and data transfer to the cloud.
This hybrid approach is especially useful for organizations that cannot move everything to the cloud at once. It provides a gradual migration path and allows businesses to adopt cloud storage at their own pace.
The gateway operates as a software-based appliance that can be deployed on a virtual machine. Once installed, it integrates with AWS services and provides multiple storage interface options depending on workload requirements.
Key Components That Power Storage Gateway Functionality
The AWS Storage Gateway system is built around several core components that work together to ensure smooth data flow between on-premises environments and cloud storage.
One of the most important components is the local cache. This cache temporarily stores frequently accessed data closer to the application, reducing latency and improving performance. Instead of retrieving data from the cloud every time, the gateway serves it locally when possible.
Another critical component is the secure data transfer engine. This ensures that all data moving between local systems and the cloud is encrypted and transmitted securely. It helps protect sensitive information during transit and reduces the risk of unauthorized access.
The protocol translation layer is also essential. This is responsible for converting traditional storage requests into cloud-compatible operations. Whether an application is using file-based or block-based storage, the gateway translates those requests into object storage actions in the background.
Finally, the management interface connects the entire system to a centralized control panel. This allows administrators to configure, monitor, and manage storage operations from a unified dashboard.
Different Types of Storage Gateway Configurations
AWS Storage Gateway supports multiple configurations designed for different use cases. Each configuration serves a specific storage need, allowing organizations to choose the most suitable model based on workload requirements.
One of the most commonly used configurations is file-based storage access. In this setup, the gateway provides file-level access using standard protocols such as NFS and SMB. Applications see the storage as a traditional file share, while the gateway handles cloud synchronization in the background.
Another configuration is block-based storage access. In this model, storage is presented as volumes that can be attached to applications. These volumes are useful for databases and systems that require low-latency block storage performance. The gateway ensures that data is securely stored and synchronized with cloud storage services.
There is also a tape-based emulation configuration, which is designed to replace physical backup tapes. Instead of relying on traditional tape libraries, organizations can use virtual tape systems that store backup data in the cloud. This approach eliminates the need for physical media while improving scalability and durability.
Each configuration is optimized for specific workloads, allowing organizations to build flexible and efficient hybrid storage environments.
The Role of Data Caching in Performance Optimization
One of the most important aspects of AWS Storage Gateway is its use of intelligent caching. Since cloud storage is not always as fast as local disk access, caching plays a critical role in maintaining performance.
When data is accessed for the first time, it is retrieved from the cloud and stored in the local cache. Subsequent requests for the same data are served directly from the local storage, significantly reducing response time.
This caching mechanism ensures that frequently used data remains accessible with minimal delay. It creates the illusion of local storage performance while still leveraging the scalability of cloud infrastructure.
The cache is dynamically managed, meaning it automatically updates based on usage patterns. Less frequently accessed data is moved to cloud storage, while more active data remains local. This balance helps optimize both performance and storage costs.
Security Mechanisms Built into the Storage Gateway
Security is a fundamental part of the AWS Storage Gateway architecture. Since data is constantly moving between local environments and cloud storage, strong protection mechanisms are required.
All data transmitted between the gateway and cloud services is encrypted using secure communication channels. This ensures that sensitive information cannot be intercepted during transfer.
Data at rest is also encrypted using strong encryption standards. This means that even if storage media is compromised, the data remains unreadable without proper authorization.
Authentication mechanisms further enhance security by ensuring that only authorized systems and users can access the storage gateway. Access control policies can be configured to restrict permissions based on organizational requirements.
Additionally, audit logging provides visibility into storage activities. This helps administrators monitor usage patterns, detect anomalies, and maintain compliance with security policies.
Data Deduplication and Compression in Storage Efficiency
To optimize storage usage and reduce costs, the AWS Storage Gateway incorporates data deduplication and compression techniques.
Data deduplication eliminates duplicate copies of data, ensuring that only unique information is stored in the cloud. This significantly reduces storage consumption, especially in environments where similar data is frequently backed up or replicated.
Compression further reduces the size of data before it is transmitted to cloud storage. By minimizing the amount of data being transferred, compression helps improve transfer speed and reduce bandwidth usage.
Together, these techniques enhance efficiency and make cloud storage more cost-effective. They also contribute to faster backup and recovery operations, as less data needs to be processed.
Integration with On-Premises and Cloud Workloads
The AWS Storage Gateway is designed to integrate seamlessly with both on-premises applications and cloud-based workloads. This flexibility allows organizations to build hybrid architectures that combine the strengths of both environments.
On-premises systems continue to operate normally, using familiar storage protocols and interfaces. The gateway ensures that these systems do not need to be modified or reconfigured.
At the same time, cloud services can access stored data for analytics, backup, or long-term archival purposes. This dual-access model enables greater flexibility in how data is used and managed.
Organizations can also gradually migrate workloads to the cloud by using the gateway as an intermediate layer. This reduces risk and allows for smoother transitions compared to direct migration approaches.
Operational Benefits of Using a Storage Gateway Approach
Adopting a storage gateway model offers several operational advantages. One of the most significant is reduced infrastructure complexity. Instead of managing separate systems for local and cloud storage, organizations can unify their storage strategy.
Another key benefit is improved scalability. As data volumes grow, cloud storage can be expanded without requiring significant changes to local infrastructure.
Cost efficiency is also a major advantage. By using cloud storage for long-term retention and local caching for active data, organizations can optimize storage expenses.
Operational resilience is enhanced as well. In the event of hardware failure or data loss, cloud backups ensure that critical information can be recovered quickly.
Finally, the storage gateway simplifies data management by providing a consistent interface across different storage environments.
Architectural Deep Dive of AWS Storage Gateway
The AWS Storage Gateway is built as a hybrid architecture that blends local infrastructure with cloud-native storage services. At its core, it is a software appliance that runs within a customer’s environment while maintaining a continuous connection to AWS cloud storage systems.
Unlike traditional storage systems that exist entirely on-premises or entirely in the cloud, this architecture is deliberately split across two domains. The local component handles immediate data access, caching, and protocol translation, while the cloud component provides durable storage, scalability, and long-term retention.
The architecture is designed around the principle of abstraction. Applications do not need to know where data physically resides. They interact with a familiar storage interface, and the gateway determines whether data should be served locally or retrieved from the cloud.
This separation allows organizations to modernize storage without disrupting existing workflows. It also reduces dependency on physical infrastructure while still maintaining local performance characteristics.
File Gateway in Detail and Its Operational Behavior
The file-based configuration of AWS Storage Gateway is one of the most widely used models because it aligns closely with traditional enterprise file storage systems.
In this configuration, the gateway presents cloud-backed storage as a file share using standard protocols such as SMB and NFS. From the perspective of applications and users, it behaves like a conventional network-attached storage device.
However, behind the scenes, every file operation is translated into object storage actions. When a file is created or modified, the gateway uploads it to cloud storage in the form of objects. When a file is accessed, the gateway retrieves it from either local cache or cloud storage depending on availability.
One of the most important aspects of this model is metadata handling. File systems rely heavily on metadata such as permissions, timestamps, and directory structures. The gateway maintains this metadata locally and synchronizes it with cloud storage to ensure consistency.
This design allows organizations to extend file storage into the cloud without changing how users interact with files. It is especially useful for shared file systems, home directories, and content repositories.
The file gateway also supports asynchronous upload behavior. This means that file operations can occur locally even when cloud connectivity is temporarily slow or unavailable. Once connectivity is restored, changes are synchronized automatically.
Volume Gateway Deep Dive and Block Storage Mechanics
The volume-based configuration of AWS Storage Gateway is designed for applications that require block-level storage access. Unlike file storage, block storage operates at a lower level, where data is managed in fixed-size blocks rather than files.
This configuration is commonly used for databases, enterprise applications, and systems that require consistent low-latency storage performance.
There are two primary modes within this configuration: cached volumes and stored volumes. In cached volume mode, the primary data resides in the cloud, while frequently accessed data is stored locally for performance optimization. In stored volume mode, the entire dataset is stored locally and asynchronously backed up to the cloud.
In cached volume setups, local storage acts as a performance layer. Frequently used data blocks are kept on-premises, while less frequently accessed data is fetched from cloud storage as needed. This reduces local storage requirements while still maintaining fast access to active datasets.
In stored volume setups, the gateway ensures that a complete copy of the dataset is available locally. This allows applications to operate with minimal latency. Cloud backups are created as point-in-time snapshots, providing recovery options without affecting local performance.
The block storage model also integrates with snapshot mechanisms. Snapshots capture the state of volumes at specific points in time and are stored in the cloud. These snapshots can be used for recovery, cloning, or migration purposes.
Tape Gateway and the Modernization of Backup Infrastructure
One of the most transformative features of AWS Storage Gateway is its ability to replace traditional tape-based backup systems. The tape gateway configuration emulates a physical tape library but uses cloud storage as the backend.
In legacy environments, backup data is often written to physical tapes, which are then stored offsite for disaster recovery. This approach is slow, expensive, and difficult to manage at scale.
The tape gateway eliminates the need for physical media by creating virtual tapes that behave like real ones from the perspective of backup software. These virtual tapes are stored in cloud storage services, providing virtually unlimited capacity and long-term durability.
When a backup job runs, data is written to a virtual tape stored locally on the gateway. Once the tape is full or the job completes, it is automatically transferred to cloud storage for archival.
This process preserves existing backup workflows while modernizing the underlying storage infrastructure. It also enables faster retrieval of backup data compared to traditional physical tape systems.
Additionally, virtual tapes can be moved between storage tiers in the cloud, allowing organizations to optimize costs based on retention requirements.
Data Flow Lifecycle from Application to Cloud Storage
Understanding how data moves through the AWS Storage Gateway is essential for grasping its operational model. The data lifecycle begins at the application layer, where a file, block, or backup operation is initiated.
Once a request is made, the gateway intercepts it and determines whether the data is available locally in the cache. If it is, the request is served immediately from local storage, ensuring low latency.
If the data is not available locally, the gateway retrieves it from cloud storage. Once retrieved, it is stored in the local cache for future access.
When data is created or modified, it is first written locally to ensure fast response times. The gateway then queues the data for asynchronous upload to cloud storage.
This staged approach ensures that applications are not delayed by network latency or cloud processing times. It also provides resilience in environments with intermittent connectivity.
Over time, less frequently accessed data is evicted from the local cache to make room for newer or more active data. This ensures efficient use of local storage resources.
Network Connectivity and Latency Considerations
Network performance plays a critical role in the effectiveness of AWS Storage Gateway. Since the system relies on continuous communication between on-premises environments and cloud storage, latency and bandwidth directly impact performance.
To mitigate these challenges, the gateway uses optimized data transfer mechanisms. These include compression, batching, and asynchronous processing to reduce the number of network calls required.
Bandwidth throttling is also available, allowing administrators to control how much network capacity is used for cloud synchronization. This ensures that storage operations do not interfere with other critical network traffic.
Latency is primarily managed through local caching. By keeping frequently accessed data close to applications, the gateway reduces dependency on cloud round trips.
In distributed environments, multiple gateways can be deployed to serve different locations. This reduces cross-site traffic and improves overall responsiveness.
Performance Optimization Techniques in Hybrid Storage
Performance optimization is a core design principle of AWS Storage Gateway. Several techniques are used to ensure efficient data handling across hybrid environments.
Caching is the most important optimization mechanism. By storing active data locally, the gateway minimizes cloud dependency for frequent operations.
Compression reduces the size of data before transmission, improving transfer speed and reducing bandwidth usage. This is especially beneficial for large datasets or backup workloads.
Deduplication eliminates redundant data, ensuring that only unique information is transmitted and stored. This reduces both storage consumption and network load.
Another optimization technique involves intelligent prefetching. The gateway can anticipate data usage patterns and pre-load frequently accessed data into local cache.
Together, these techniques ensure that hybrid storage systems perform efficiently even under heavy workloads.
Security Architecture and Compliance Design Principles
Security is deeply embedded into the architecture of AWS Storage Gateway. Every layer of the system is designed to protect data both in transit and at rest.
Data transmitted between local systems and cloud storage is encrypted using secure communication channels. This prevents unauthorized interception during transfer.
At rest, data is encrypted using strong encryption standards. This ensures that even if storage media is compromised, the data remains protected.
Access control mechanisms regulate who can interact with the storage gateway. Authentication and authorization policies ensure that only approved users and systems can perform storage operations.
Audit logging provides visibility into all storage activities. This includes data access, modifications, and transfer events. These logs are essential for compliance and security monitoring.
The architecture is also designed to support regulatory requirements in industries such as finance, healthcare, and government, where data protection is critical.
Integration with AWS Storage Ecosystem Services
AWS Storage Gateway does not operate in isolation. It is tightly integrated with other AWS storage services, creating a unified storage ecosystem.
One of the primary integrations is with Amazon S3, which serves as the underlying object storage system. Data transferred through the gateway is ultimately stored in S3 buckets, providing durability and scalability.
For long-term archival storage, data can be transitioned to colder storage tiers such as Amazon S3 Glacier. This allows organizations to reduce costs for infrequently accessed data while maintaining retention.
Snapshot data from volume gateways is also stored in cloud storage, enabling recovery and replication across environments.
This integration allows organizations to build tiered storage strategies that balance performance, cost, and durability.
Disaster Recovery and Business Continuity Strategies
One of the most powerful advantages of AWS Storage Gateway is its ability to support disaster recovery scenarios.
Since data is continuously backed up to cloud storage, organizations can recover from hardware failures, data corruption, or site outages with minimal disruption.
In the event of a failure, a new gateway can be deployed in a different location, and cloud-stored data can be restored to resume operations.
This eliminates the dependency on physical infrastructure and reduces recovery time objectives significantly.
Point-in-time snapshots also enable recovery to specific states, allowing organizations to roll back to known good configurations.
Business continuity is further enhanced by the ability to replicate data across multiple locations. This ensures that even regional failures do not result in data loss.
Enterprise Deployment Patterns and Scaling Strategies
In enterprise environments, AWS Storage Gateway is often deployed in distributed and scalable architectures. Multiple gateways may be used across different departments, regions, or business units.
Each gateway operates independently but connects to shared cloud storage resources. This allows organizations to scale storage infrastructure horizontally without redesigning their systems.
Load distribution is achieved by assigning different workloads to different gateways. This prevents bottlenecks and ensures consistent performance across environments.
Scaling is also simplified because cloud storage capacity can grow independently of local infrastructure. Organizations do not need to physically expand storage hardware to accommodate growth.
In large-scale deployments, centralized monitoring systems are often used to track gateway performance, storage usage, and network activity. This provides visibility into the entire storage ecosystem.
Hybrid cloud architectures built on AWS Storage Gateway allow enterprises to evolve gradually while maintaining operational stability and performance consistency.
Distributed Hybrid Storage at Scale and Multi-Site Connectivity Models
As organizations grow, storage is no longer confined to a single data center. Modern enterprises often operate across multiple offices, regions, and cloud environments. This distributed reality introduces complexity in how data is accessed, synchronized, and protected. The AWS Storage Gateway is designed to operate effectively in these multi-site environments by extending hybrid storage capabilities beyond a single location.
In a distributed setup, each site can run its own gateway instance while still connecting to shared cloud storage. This allows local teams to access data with low latency while ensuring that all information is centrally stored and managed in the cloud.
The key advantage of this approach is locality of access. Instead of routing all storage requests through a central data center, each site handles its own data operations locally. Only synchronization and long-term storage operations interact with the cloud layer.
This reduces network congestion and improves responsiveness for geographically distributed teams. It also ensures that branch offices, remote facilities, and edge locations can operate independently even if connectivity to the central infrastructure is disrupted.
Multi-site configurations also enable data replication strategies. Critical datasets can be mirrored across multiple gateways, ensuring that each location maintains access to essential information. This improves resilience and reduces dependency on a single storage point.
Edge Computing and Storage Gateway at the Network Edge
Edge computing has become increasingly important in modern IT architectures, especially for applications that require real-time processing or operate in environments with limited connectivity. The AWS Storage Gateway plays a significant role in enabling storage capabilities at the edge.
By deploying the gateway closer to data sources, organizations can reduce latency and improve performance for edge applications. Data generated at remote sites can be processed locally and then synchronized with cloud storage when connectivity allows.
This is particularly useful in industries such as manufacturing, logistics, healthcare, and telecommunications, where data is often generated far from centralized data centers.
At the edge, the gateway acts as both a local storage controller and a cloud synchronization engine. It ensures that applications continue to function even in disconnected or intermittently connected environments.
Once connectivity is restored, the gateway automatically synchronizes changes with cloud storage, ensuring consistency across the entire system.
This edge-enabled model allows organizations to extend cloud capabilities into environments that were previously difficult to support.
Data Consistency Models and Synchronization Behavior
Maintaining data consistency across hybrid environments is one of the most challenging aspects of distributed storage systems. The AWS Storage Gateway addresses this challenge through carefully designed synchronization mechanisms.
When data is modified locally, those changes are first committed to local storage. The gateway then queues these changes for upload to cloud storage. This asynchronous model ensures that applications are not blocked by network delays.
However, this introduces the possibility of temporary inconsistency between local and cloud copies. To manage this, the gateway uses versioning and metadata tracking to ensure that changes are applied in the correct order.
Conflict resolution mechanisms are also in place to handle situations where multiple gateways may modify the same dataset. In such cases, the system uses timestamps and version control to determine the most recent and authoritative version of the data.
Consistency is eventually achieved once all changes are synchronized with the cloud. This model is known as eventual consistency, where temporary differences are allowed as long as the system converges to a unified state over time.
This approach balances performance and reliability, ensuring that local operations remain fast while cloud systems maintain long-term accuracy.
Storage Tiering and Intelligent Data Placement
One of the most important aspects of modern storage design is tiering—placing data in different storage classes based on how frequently it is accessed. The AWS Storage Gateway integrates naturally with this concept.
Frequently accessed data is stored locally in cache or on-premises storage for fast retrieval. Less frequently accessed data is moved to cloud storage, where it can be retained at lower cost.
Within the cloud, additional tiering options are available. Data can be stored in high-performance object storage for active use cases or moved to archival tiers for long-term retention.
The gateway plays a key role in determining data placement based on usage patterns. It continuously monitors access behavior and adjusts caching and synchronization strategies accordingly.
This intelligent placement ensures that storage resources are used efficiently. High-performance storage is reserved for active workloads, while cold data is moved to cost-effective storage tiers.
Over time, this creates a dynamic storage ecosystem where data automatically shifts between tiers based on real-world usage.
Backup Optimization and Incremental Data Transfer Strategies
Backup operations are one of the most common use cases for AWS Storage Gateway. However, traditional backup systems can be inefficient due to repeated full data transfers. The gateway improves this process through incremental backup strategies.
Instead of copying entire datasets during each backup cycle, the gateway identifies only the changed portions of data. These incremental changes are then transferred to cloud storage.
This reduces network usage and speeds up backup operations significantly. It also minimizes storage costs by avoiding redundant data transfers.
In addition, compression and deduplication further optimize backup efficiency. Duplicate data blocks are eliminated, and remaining data is compressed before transmission.
This combination of incremental transfer, deduplication, and compression creates a highly efficient backup pipeline that is well-suited for large-scale enterprise environments.
Backup data stored in the cloud can also be versioned, allowing organizations to restore previous states of their systems when needed.
Performance Behavior Under High Load Conditions
In enterprise environments, storage systems must handle varying levels of demand. During peak usage periods, the AWS Storage Gateway is designed to maintain stable performance through resource management and load balancing techniques.
Local caching plays a critical role in absorbing high read loads. When multiple applications request the same data, it is served directly from local storage rather than repeatedly fetching it from the cloud.
Write operations are also optimized through batching. Instead of sending each change individually, the gateway groups multiple operations into a single transfer. This reduces network overhead and improves throughput.
The system also dynamically adjusts resource allocation based on workload intensity. During high demand, more local resources are allocated to caching and processing, while cloud synchronization is temporarily prioritized based on available bandwidth.
If network conditions become constrained, the gateway continues to operate locally, queuing data for later synchronization. This ensures that applications remain functional even under stress conditions.
Lifecycle Management of Stored Data
Data within the AWS Storage Gateway environment follows a defined lifecycle that governs how it is stored, accessed, and eventually archived or deleted.
When data is first created, it is stored locally for immediate access. This allows applications to interact with it at high speed.
Over time, if data is not frequently accessed, it may be moved to cloud storage to free up local resources. This transition is transparent to applications.
As data ages further and becomes less relevant, it may be moved to archival storage tiers within the cloud. These tiers are optimized for long-term retention at reduced cost.
Finally, when data is no longer required, it can be deleted according to retention policies. These policies are often defined by organizational or regulatory requirements.
This lifecycle approach ensures that storage resources are used efficiently while still preserving access to important historical data when needed.
Integration with Enterprise Security Frameworks
In enterprise environments, storage systems must align with broader security frameworks and governance policies. The AWS Storage Gateway is designed to integrate into these frameworks without requiring significant changes.
It supports identity-based access control, allowing organizations to define who can access specific storage resources. Permissions can be configured at granular levels to restrict access based on roles and responsibilities.
Encryption policies ensure that all data is protected both in transit and at rest. These policies can be aligned with internal security standards or external compliance requirements.
Audit trails provide visibility into all storage operations. This includes file access, data transfers, and configuration changes. These logs can be integrated into security monitoring systems for real-time analysis.
The gateway also supports secure authentication mechanisms that integrate with existing identity management systems. This allows organizations to maintain centralized control over access policies.
Cost Optimization Strategies in Hybrid Storage Environments
One of the primary motivations for adopting AWS Storage Gateway is cost optimization. Hybrid storage models allow organizations to reduce reliance on expensive on-premises infrastructure while leveraging cost-efficient cloud storage.
Local storage is typically reserved for high-performance or frequently accessed data, while cloud storage is used for long-term retention and archival purposes.
This reduces the need for large-scale on-premises storage systems, which can be expensive to maintain and scale.
Data deduplication and compression further reduce storage costs by minimizing the amount of data stored in the cloud.
Lifecycle policies also contribute to cost efficiency by automatically moving data to lower-cost storage tiers as it becomes less frequently accessed.
Bandwidth optimization techniques reduce network transfer costs by minimizing unnecessary data movement between local and cloud environments.
Together, these strategies create a highly cost-efficient storage model that adapts to changing usage patterns.
Operational Monitoring and System Observability
Effective management of hybrid storage systems requires continuous monitoring and observability. The AWS Storage Gateway provides detailed metrics and logging capabilities that allow administrators to track system performance.
Key metrics include storage utilization, cache hit rates, network throughput, and synchronization latency. These metrics provide insight into how efficiently the system is operating.
Logging capabilities capture detailed information about storage operations, including file access, data transfers, and error events. These logs are essential for troubleshooting and performance analysis.
Monitoring tools can also detect anomalies such as unusual access patterns or unexpected spikes in data usage. This helps organizations identify potential issues before they impact operations.
In large-scale environments, centralized monitoring systems aggregate data from multiple gateways, providing a unified view of the entire storage infrastructure.
Long-Term Evolution of Hybrid Storage Systems
Hybrid storage systems continue to evolve as cloud adoption increases and data volumes grow. The AWS Storage Gateway represents an important step in this evolution by bridging the gap between traditional infrastructure and cloud-native storage.
Over time, storage systems are expected to become increasingly automated. Intelligent algorithms will play a greater role in managing data placement, performance optimization, and cost control.
Edge computing will also become more integrated with hybrid storage, enabling real-time data processing closer to where data is generated.
As organizations continue to adopt cloud-first strategies, hybrid models will serve as transitional and long-term architectures that balance flexibility, performance, and cost.
The AWS Storage Gateway sits at the center of this transformation, enabling seamless connectivity between distributed environments and scalable cloud storage systems.
Advanced Data Movement Patterns and Hybrid Transfer Optimization
In large-scale hybrid environments, data movement is not simply a matter of copying files between systems. It becomes a carefully orchestrated process that balances performance, cost, reliability, and consistency. The AWS Storage Gateway introduces advanced transfer patterns that are designed to make this process efficient even under heavy enterprise workloads.
One of the most important concepts in this context is asynchronous transfer optimization. Instead of sending data immediately to the cloud with every change, the gateway intelligently batches updates. These batches are transmitted during optimal network conditions, reducing congestion and improving throughput. This approach ensures that local application performance is never blocked by cloud synchronization delays.
Another important optimization technique is adaptive transfer sizing. The gateway adjusts the size of data chunks based on current network conditions. When bandwidth is high and latency is low, larger chunks are transmitted to maximize efficiency. When network conditions degrade, the system switches to smaller, more manageable transfers to maintain stability.
This dynamic behavior allows the gateway to operate efficiently across a wide range of network environments, from high-speed enterprise links to constrained or unstable connections commonly found in remote sites.
Role of Metadata Intelligence in Storage Operations
Beyond raw data transfer, metadata plays a crucial role in how the AWS Storage Gateway manages storage operations. Metadata includes information such as file structure, timestamps, permissions, version history, and access patterns.
The gateway uses this metadata to make intelligent decisions about caching, synchronization, and storage tiering. For example, files that are accessed frequently over short time intervals may be prioritized for local caching, while rarely accessed files are candidates for cloud migration.
Metadata also enables predictive behavior. By analyzing access trends over time, the system can anticipate which data is likely to be needed in the near future and pre-load it into local storage. This reduces latency and improves user experience without requiring manual configuration.
In distributed environments, metadata consistency is especially important. The gateway ensures that metadata changes are propagated reliably across all connected systems, even if actual data transfer is delayed due to network conditions.
Handling Failures and Recovery Scenarios in Hybrid Environments
No storage system is complete without robust failure handling mechanisms, and the AWS Storage Gateway is designed with resilience as a core principle. Failures can occur at multiple levels, including network disruptions, hardware issues, or cloud service interruptions.
When a network failure occurs, the gateway continues to operate using local storage. Applications are not immediately impacted because all read and write operations are handled locally. Write operations are queued for later synchronization once connectivity is restored.
In the case of gateway hardware failure, recovery is achieved by redeploying a new gateway instance and reconnecting it to existing cloud storage. Since data is stored in the cloud, the new gateway can retrieve and rebuild its local cache without data loss.
Cloud-side failures are mitigated through redundancy mechanisms provided by the underlying storage services. Data stored in cloud systems is replicated across multiple availability zones, ensuring durability even in the event of infrastructure outages.
This layered approach to failure handling ensures that the system remains operational under a wide range of adverse conditions.
Data Gravity and Its Influence on Hybrid Storage Design
As organizations accumulate more data in the cloud, a phenomenon known as data gravity begins to influence system design. Data gravity refers to the tendency of large datasets to attract applications, services, and additional data processing workloads.
The AWS Storage Gateway helps manage data gravity by providing a balanced approach between local and cloud storage. Instead of forcing all data into a single location, it allows data to exist where it is most useful.
Frequently accessed data remains close to applications, while large historical datasets are stored in the cloud where they can be analyzed or archived efficiently.
This balance prevents performance bottlenecks that might occur if all data were centralized in one location. It also supports flexible workload distribution across hybrid environments.
Intelligent Workload Distribution Across Storage Layers
Workload distribution is another critical aspect of hybrid storage systems. Different applications have different storage requirements, and the AWS Storage Gateway helps distribute these workloads effectively.
High-performance workloads, such as transactional systems or real-time analytics, rely heavily on local caching to minimize latency. These workloads benefit from immediate access to frequently used data.
Conversely, archival workloads or backup processes are primarily cloud-based. These do not require immediate access and can tolerate higher latency in exchange for lower cost and higher durability.
The gateway dynamically balances these workloads based on access patterns and system demand. This ensures that no single storage layer becomes overloaded while others remain underutilized.
Conclusion
The AWS Storage Gateway represents a practical and powerful approach to solving one of the most persistent challenges in modern IT: bridging the gap between traditional on-premises storage systems and scalable cloud storage. Instead of forcing organizations to completely redesign their applications or abandon existing infrastructure, it introduces a hybrid model that integrates both worlds in a seamless and efficient way.
By offering file, block, and tape-based interfaces, the gateway allows legacy systems to continue operating without disruption while still benefiting from cloud scalability, durability, and cost efficiency. Its ability to translate storage protocols, manage data caching, and handle secure synchronization makes it a versatile solution for a wide range of workloads.
One of its most valuable strengths is flexibility. Whether an organization needs fast local access for active data, long-term archival storage, or a complete backup replacement strategy, the storage gateway adapts to those requirements through different configurations and intelligent data management techniques.
Equally important is its role in supporting hybrid and distributed environments. As businesses expand across multiple locations and adopt edge computing models, the need for consistent and reliable data access becomes critical. The gateway ensures that data remains accessible locally while being securely maintained in the cloud.
Ultimately, the AWS Storage Gateway is not just a connectivity tool—it is an enabler of modern storage strategy. It simplifies cloud adoption, improves operational resilience, and allows organizations to gradually transition toward cloud-first architectures without sacrificing performance or control.