Network monitoring has become one of the most important pillars of modern IT operations because almost every business now depends on distributed systems, cloud platforms, and internet-based services. Unlike traditional infrastructure setups where everything was contained within a single data center, today’s environments stretch across multiple cloud providers, third-party services, remote offices, and global user locations. This shift has made it increasingly difficult to understand where performance issues originate and how they affect end users.
In earlier IT environments, monitoring primarily focused on internal systems such as servers, switches, and routers within a controlled network boundary. If a problem occurred, it was usually inside the organization’s own infrastructure, making it easier to detect and resolve. However, the modern digital ecosystem is far more complex. Applications rely on external dependencies, APIs, content delivery networks, and internet service providers, which all introduce potential points of failure outside of direct control.
As a result, organizations now require tools that go beyond traditional infrastructure monitoring. They need platforms that provide visibility not only into their own systems but also into how data travels across the internet, how third-party networks behave, and how end users experience services in real time. This is where advanced network intelligence platforms like ThousandEyes have become highly relevant, offering a broader perspective on performance that extends beyond the boundaries of a single organization’s infrastructure.
Evolution of Network Visibility and Performance Monitoring
The evolution of network monitoring has been shaped by the increasing complexity of digital environments. In the past, monitoring tools were designed to check basic metrics such as server uptime, CPU usage, memory consumption, and local network traffic. These metrics were sufficient when applications were hosted on-premises and accessed through internal networks.
Over time, businesses began adopting virtualization, followed by cloud computing. This introduced a major shift in how applications were deployed and consumed. Instead of running everything on local servers, organizations started relying on distributed cloud environments where components of a single application might be hosted in different regions or even different providers.
This transformation created a visibility gap. Traditional monitoring tools could still observe internal systems, but they struggled to understand what was happening beyond the organization’s network perimeter. For example, if a user experienced slow application performance, it was no longer obvious whether the issue was caused by the application itself, the internet connection, the cloud provider, or a third-party service.
To address this gap, network monitoring evolved into network observability and digital experience monitoring. The focus shifted from simply detecting failures to understanding the full journey of data across networks. This included tracking how requests travel across the internet, how latency changes across regions, and how external dependencies impact application performance.
Modern tools like ThousandEyes emerged in response to these challenges by introducing a model that focuses on end-to-end visibility across both internal infrastructure and external internet paths. This shift marked a significant change in how organizations approach network performance analysis, moving from reactive troubleshooting to proactive insight generation.
Understanding Complex Network Visibility Challenges
One of the biggest challenges in modern IT environments is the lack of control over external networks. While organizations can manage their internal infrastructure, they cannot directly control internet service providers, cloud interconnections, or third-party systems. This creates blind spots that make troubleshooting significantly more difficult.
When a user reports a performance issue, IT teams often face uncertainty about where the problem lies. It could be within the application code, within the cloud environment, or somewhere along the internet route between the user and the service. Without proper visibility, diagnosing such issues can take a long time and often involves guesswork.
Another challenge comes from distributed user bases. Applications are no longer accessed from a single geographic region. Instead, users connect from different countries, cities, and network environments. A service that performs well in one region may perform poorly in another due to differences in routing paths, congestion, or local ISP performance.
Additionally, modern applications rely heavily on microservices and APIs. A single user request may trigger multiple backend calls across different systems. If one of these dependencies slows down, it can affect the overall user experience even if the main application is functioning correctly. Traditional monitoring tools often fail to connect these dots because they focus on isolated metrics rather than the full transaction path.
These challenges highlight the need for a more holistic approach to monitoring, where visibility extends beyond internal systems and includes the entire delivery chain of digital services.
Introduction to ThousandEyes Monitoring Approach
ThousandEyes is designed to address the visibility gaps that exist in modern network environments by providing insights into how data moves across the internet and how external factors influence application performance. Instead of focusing only on internal infrastructure, it expands monitoring to include the entire path between users and services.
At its core, ThousandEyes operates on the principle that understanding network performance requires visibility at every hop, not just within controlled environments. This means it monitors traffic as it traverses enterprise networks, internet service provider networks, cloud platforms, and content delivery networks.
One of the defining aspects of ThousandEyes is its ability to map internet infrastructure in a way that allows organizations to see how different networks are interconnected. This helps identify where latency, packet loss, or routing issues occur along the path. By analyzing these external dependencies, organizations can better understand whether performance issues are internal or caused by third-party networks.
Unlike traditional monitoring systems that focus on static infrastructure metrics, ThousandEyes emphasizes dynamic path analysis. This means it continuously evaluates how data flows through the internet and how that flow changes over time. This is particularly important in environments where network routes are not fixed and can vary based on traffic conditions or provider decisions.
ThousandEyes Network Visibility Model
The visibility model used by ThousandEyes is built around the concept of end-to-end network intelligence. This model focuses on capturing data from multiple points along the communication path, including endpoints, cloud services, and internet backbone networks.
At the endpoint level, the platform observes how users interact with applications and how network conditions affect their experience. This includes analyzing latency, connection stability, and response times from the user’s perspective. By doing so, it provides insight into real-world performance rather than relying solely on backend metrics.
At the network level, ThousandEyes tracks how packets move across different autonomous systems and service providers. This allows it to identify bottlenecks or disruptions that may not be visible within a single organization’s infrastructure. For example, if traffic is being rerouted through a congested ISP path, the system can detect and highlight that change.
At the cloud level, the platform monitors interactions between different cloud services and regions. As many organizations now operate in multi-cloud environments, understanding how these services communicate is essential for maintaining performance consistency.
This layered visibility approach ensures that organizations are not limited to isolated data points. Instead, they gain a comprehensive view of how every component in the delivery chain contributes to overall application behavior.
Internet Intelligence and External Dependency Monitoring
One of the most distinctive aspects of ThousandEyes is its focus on internet intelligence. This involves continuously analyzing global network conditions and understanding how different parts of the internet behave in real time.
Internet intelligence allows organizations to identify patterns that affect performance, such as congestion in specific regions, outages in service provider networks, or routing inefficiencies between cloud regions. These insights are particularly valuable for businesses that operate globally and rely on consistent performance across different geographical locations.
External dependency monitoring plays a crucial role in this process. Modern applications often rely on third-party services for authentication, data storage, payment processing, and content delivery. If any of these external services experience issues, it can directly impact the user experience even if the core application remains functional.
By monitoring these dependencies, ThousandEyes provides visibility into how external systems contribute to overall performance. This helps organizations distinguish between internal application issues and problems originating outside their infrastructure.
End-to-End Application Delivery Insights
Understanding application performance requires more than just monitoring servers or network devices. It requires a complete view of how users experience the application from start to finish. ThousandEyes provides this by tracking application delivery across every stage of the communication process.
When a user accesses an application, multiple interactions occur behind the scenes. The request may pass through local networks, internet service providers, cloud gateways, and backend systems before a response is generated. Each of these stages introduces potential delays or disruptions.
ThousandEyes captures this entire journey and provides insights into where delays occur. It does not simply show that an application is slow; it helps identify whether the slowdown is caused by DNS resolution, network routing, server response time, or external service latency.
This level of detail is important for organizations that depend on cloud-based applications. Without visibility into the full delivery chain, performance optimization becomes difficult and often reactive. With comprehensive insights, teams can proactively identify weak points and address them before they impact users.
Monitoring in Cloud and Hybrid Environments
Cloud adoption has significantly changed how network monitoring is approached. In hybrid environments, where systems are split between on-premises infrastructure and cloud platforms, maintaining visibility becomes more complex.
ThousandEyes addresses this challenge by providing monitoring capabilities that extend across both environments. It allows organizations to observe how on-premises systems interact with cloud services and how data flows between different deployment models.
One of the key challenges in hybrid environments is ensuring consistent performance across all components. A delay in communication between cloud services and internal systems can affect application responsiveness. ThousandEyes helps identify such delays by tracking interconnectivity and measuring performance across different layers of infrastructure.
Cloud environments also introduce variability in network paths. Unlike traditional networks, cloud routing can change dynamically based on provider configurations. This means that the path between two services may not always be the same. ThousandEyes continuously monitors these changes to ensure that organizations maintain awareness of how their network behavior evolves.
Distributed Systems and Global Performance Visibility
Modern applications are often built using distributed architectures, where different components are deployed across multiple locations. This approach improves scalability and resilience but also increases complexity in monitoring.
ThousandEyes provides visibility into how these distributed systems interact with each other across global networks. It tracks how requests move between services hosted in different regions and how latency varies depending on network conditions.
Global performance visibility is particularly important for organizations that serve users across multiple continents. A system that performs well in one region may behave differently in another due to variations in infrastructure quality and routing efficiency.
By analyzing performance from multiple geographic perspectives, ThousandEyes helps organizations understand how location impacts user experience. This allows them to optimize service delivery based on regional network conditions rather than relying on a single global performance model.
SolarWinds Approach to Enterprise IT Monitoring
SolarWinds is widely recognized in the IT operations space for its broad approach to infrastructure monitoring and management. Unlike tools that focus primarily on network visibility across external environments, SolarWinds is designed around the idea of centralized IT operations management. This means it brings together multiple layers of infrastructure monitoring under a unified platform, allowing organizations to observe servers, networks, applications, databases, and security events in a single environment.
The philosophy behind SolarWinds is rooted in operational control and internal infrastructure optimization. It focuses heavily on ensuring that IT teams have deep insight into everything they manage directly. This includes physical servers in data centers, virtual machines, cloud-hosted workloads, and network devices such as routers and switches. By consolidating these elements, SolarWinds enables IT teams to maintain operational stability across complex environments without needing separate tools for each domain.
In modern enterprise settings, where IT infrastructure spans multiple environments, this centralized approach becomes particularly valuable. Organizations often struggle with tool sprawl, where different monitoring systems are used for different parts of the infrastructure. SolarWinds addresses this challenge by integrating multiple monitoring capabilities into a single ecosystem, reducing fragmentation and improving operational efficiency.
Core Architecture of SolarWinds Monitoring Systems
The architecture of SolarWinds is built around a modular framework that allows organizations to expand monitoring capabilities based on their specific requirements. At the core of this architecture is a central monitoring engine that collects, processes, and analyzes performance data from various sources.
Data collection is achieved through agents, APIs, and network polling mechanisms. These collectors gather information from servers, network devices, and applications, then transmit it to the central system for analysis. This approach ensures that performance metrics are continuously updated and available for real-time evaluation.
One of the key strengths of SolarWinds architecture is its scalability within enterprise environments. As organizations grow, they can add additional monitoring modules without restructuring the entire system. This modular design allows IT teams to start with basic network monitoring and gradually expand into areas such as application performance, database monitoring, and security analytics.
The system also supports distributed monitoring setups, where multiple polling engines are deployed across different locations. This helps reduce latency in data collection and ensures that large-scale environments can be monitored efficiently without overwhelming a single central system.
Network Performance Monitoring Capabilities
One of the most widely used components of SolarWinds is its network performance monitoring capability. This feature is designed to provide detailed visibility into network devices, traffic patterns, and infrastructure health across enterprise environments.
Network monitoring in SolarWinds focuses heavily on device-level insights. It tracks the performance of routers, switches, firewalls, and other network components by collecting metrics such as bandwidth usage, packet loss, interface errors, and uptime statistics. This information helps IT teams identify bottlenecks and resolve issues before they escalate into larger outages.
Unlike tools that emphasize external internet visibility, SolarWinds network monitoring is primarily focused on internal infrastructure. It provides a detailed view of how data flows within an organization’s controlled environment, making it easier to optimize internal network performance.
Another important aspect of this capability is traffic analysis. SolarWinds can analyze network traffic patterns to determine which applications or users are consuming the most bandwidth. This helps organizations manage network resources more effectively and prevent congestion caused by high-demand applications.
Server and Infrastructure Monitoring Depth
Beyond network devices, SolarWinds extends its monitoring capabilities to servers and infrastructure components. This includes both physical and virtual environments, allowing organizations to maintain visibility across hybrid infrastructures.
Server monitoring focuses on key performance indicators such as CPU utilization, memory usage, disk activity, and system health. These metrics provide insight into how efficiently servers are operating and whether they are approaching capacity limits. By tracking these indicators over time, IT teams can identify trends that may lead to performance degradation.
Virtualized environments are also an important part of modern IT infrastructure. SolarWinds provides monitoring for virtualization platforms, allowing administrators to track the performance of virtual machines and host systems. This includes visibility into resource allocation, workload distribution, and system dependencies.
In cloud environments, SolarWinds extends its monitoring capabilities to include cloud-hosted servers and services. This ensures that organizations can maintain consistent visibility across both on-premises and cloud infrastructure, reducing the complexity of managing hybrid systems.
Application Performance Monitoring Perspective
Application performance monitoring in SolarWinds focuses on understanding how software applications behave within an IT environment. This includes tracking response times, transaction flows, and backend dependencies that influence application performance.
Modern applications are often composed of multiple interconnected components. A single user request may pass through several layers of services, databases, and external APIs before a response is generated. SolarWinds provides visibility into these interactions by tracing application transactions and identifying performance bottlenecks at each stage.
One of the key strengths of this approach is its ability to correlate application performance with underlying infrastructure behavior. For example, if an application is running slowly, SolarWinds can help determine whether the issue is caused by server performance, database delays, or network congestion.
This correlation capability is essential in complex environments where multiple systems interact with each other. Without it, identifying the root cause of performance issues would require manual analysis across different monitoring tools.
Log Management and Event Correlation Systems
In addition to performance monitoring, SolarWinds includes log management and event correlation capabilities. These features play an important role in understanding system behavior and diagnosing issues across IT environments.
Logs provide detailed records of system activity, including application events, security alerts, and infrastructure changes. SolarWinds collects and organizes these logs to provide a centralized view of system activity. This makes it easier for IT teams to search, filter, and analyze log data when troubleshooting issues.
Event correlation adds another layer of intelligence by identifying relationships between different system events. Instead of treating each event independently, SolarWinds analyzes patterns to determine whether multiple events are related to a single underlying issue. This helps reduce noise and allows IT teams to focus on the most relevant alerts.
In large environments where thousands of events may be generated every minute, this correlation capability becomes essential for maintaining operational efficiency. It ensures that teams are not overwhelmed by redundant or unrelated alerts.
Security Monitoring and Compliance Visibility
Security monitoring is another important aspect of SolarWinds’ platform. While it is primarily known for infrastructure monitoring, it also includes features that help organizations detect security threats and maintain compliance standards.
Security monitoring focuses on identifying unusual behavior within IT systems. This may include unauthorized access attempts, abnormal network traffic, or changes in system configurations. By detecting these anomalies, SolarWinds helps organizations respond to potential security incidents more quickly.
Compliance monitoring is also integrated into the platform, allowing organizations to track adherence to regulatory standards. This is particularly important for industries that must comply with strict data protection and operational guidelines.
By combining performance monitoring with security visibility, SolarWinds provides a more comprehensive view of IT health. This integration helps organizations understand not only how systems are performing but also whether they are operating securely.
Alerting Systems and Operational Response
One of the most critical components of any monitoring platform is its alerting system. SolarWinds includes a highly configurable alerting mechanism that allows IT teams to define conditions under which notifications are triggered.
Alerts can be based on a wide range of metrics, including CPU usage thresholds, network latency, service availability, and application performance indicators. When these thresholds are exceeded, the system generates alerts that are sent to IT teams for immediate action.
The alerting system is designed to reduce response time by ensuring that issues are identified as soon as they occur. This proactive approach helps prevent minor issues from escalating into major outages.
In addition to basic alerting, SolarWinds also supports escalation workflows. This means that if an issue is not addressed within a certain timeframe, it can be automatically escalated to higher-level support teams. This ensures that critical issues receive timely attention.
Scalability in Large Enterprise Environments
Scalability is a key consideration for organizations with large and complex IT infrastructures. SolarWinds is designed to handle scalability through a distributed monitoring architecture and modular expansion.
As organizations grow, they often add new servers, applications, and network components. SolarWinds supports this growth by allowing additional monitoring nodes to be deployed without disrupting existing operations. These nodes help distribute the monitoring workload and ensure consistent performance across the system.
In large enterprise environments, scalability also involves managing large volumes of data. SolarWinds is capable of processing significant amounts of performance data and presenting it in a structured format. This allows IT teams to analyze trends over time and make informed decisions based on historical data.
The platform’s ability to scale across different environments makes it suitable for organizations with global operations. Whether infrastructure is located in a single data center or distributed across multiple regions, SolarWinds can adapt to the complexity of the environment.
Integration with IT Operations Ecosystems
Modern IT environments rely on multiple tools to manage different aspects of operations. SolarWinds is designed to integrate with a wide range of external systems, allowing organizations to build a connected IT ecosystem.
These integrations include ticketing systems, configuration management tools, cloud platforms, and collaboration systems. By connecting with these tools, SolarWinds enables automated workflows that streamline IT operations.
For example, when a performance issue is detected, an alert can automatically generate a ticket in a service management system. This ensures that issues are tracked and resolved in an organized manner.
Integration also plays a role in improving visibility across systems. By connecting with other platforms, SolarWinds can collect additional data that enhances its monitoring capabilities.
Observability Across Internal Infrastructure Layers
Observability in SolarWinds is centered around understanding internal system behavior through metrics, logs, and traces. This approach allows IT teams to gain insight into how different components interact within the infrastructure.
Unlike external monitoring tools that focus on internet pathways, SolarWinds emphasizes internal system observability. This includes understanding how applications communicate with databases, how servers process requests, and how network devices handle traffic.
By combining multiple data sources, SolarWinds provides a comprehensive view of internal system behavior. This helps organizations identify performance bottlenecks and optimize resource utilization.
Observability also supports long-term performance analysis. By tracking historical data, organizations can identify trends and make strategic decisions about infrastructure planning and capacity management.
Role in Traditional and Hybrid IT Environments
SolarWinds continues to play a significant role in both traditional and hybrid IT environments. In traditional setups, where most infrastructure is on-premises, it provides complete visibility into internal systems. In hybrid environments, it extends this visibility to cloud-based resources as well.
Hybrid environments introduce complexity because they combine multiple infrastructure models. SolarWinds helps manage this complexity by providing a unified monitoring approach that covers both physical and virtual systems.
This unified view is essential for maintaining operational consistency. Without it, organizations would need to rely on separate tools for different environments, leading to fragmented visibility.
By supporting both traditional and modern infrastructure models, SolarWinds remains relevant in evolving IT landscapes where flexibility and integration are essential.
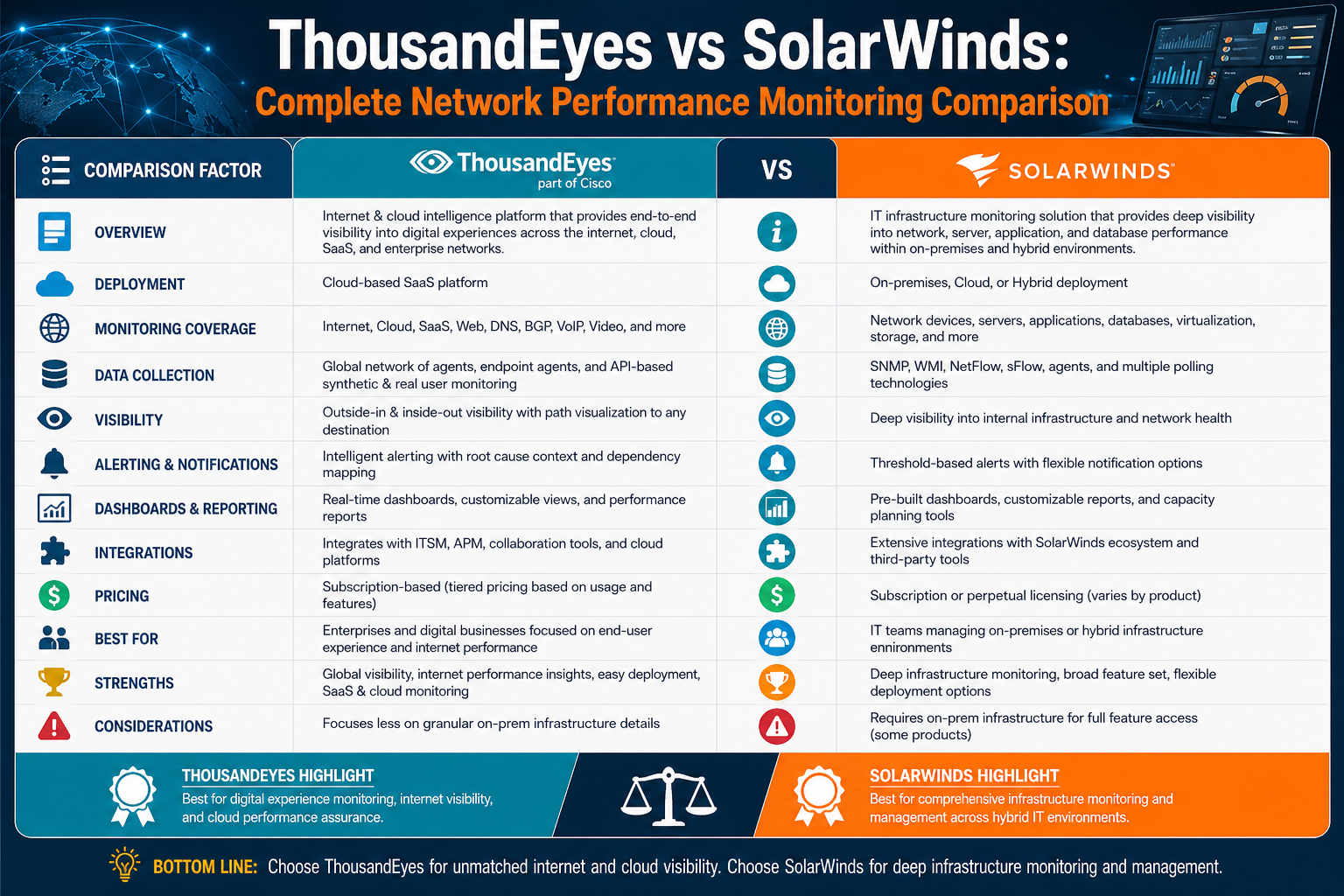
Head-to-Head Architectural Differences Between ThousandEyes and SolarWinds
When comparing ThousandEyes and SolarWinds at an architectural level, the most important distinction lies in their foundational design philosophy. ThousandEyes is built around external network intelligence and internet-wide visibility, while SolarWinds is designed around internal IT infrastructure management and operational control.
ThousandEyes extends monitoring beyond organizational boundaries, observing how data travels across the public internet, cloud networks, and service provider infrastructures. Its architecture is distributed and relies heavily on vantage points placed in different geographic and network locations. These vantage points continuously simulate and measure network conditions from multiple perspectives, allowing the system to reconstruct a global view of connectivity and performance.
SolarWinds, on the other hand, is centralized around the organization’s internal environment. Its architecture is built on a core monitoring engine that collects data from agents, network devices, and application systems. This data is processed internally and used to generate dashboards, alerts, and reports focused on infrastructure health.
The contrast is significant because ThousandEyes does not rely on direct control over infrastructure; instead, it observes external behavior from multiple independent points. SolarWinds relies on direct access to monitored systems, enabling deeper internal diagnostics but limited visibility beyond controlled environments.
This difference in architecture defines how each platform interprets performance issues. ThousandEyes identifies where problems occur across global networks, while SolarWinds identifies what is happening inside organizational systems.
Data Collection Models and Telemetry Strategies
Data collection is another area where both platforms differ fundamentally. ThousandEyes uses a synthetic and distributed telemetry model. It actively generates traffic from monitoring points and observes how that traffic behaves as it traverses networks. This approach allows it to simulate real-world user experiences and capture performance metrics from an external perspective.
The synthetic nature of this model is particularly useful for understanding how applications behave under different network conditions. By sending controlled requests from multiple locations, ThousandEyes can measure latency, packet loss, and routing changes across the internet. This provides a realistic view of user experience, even when actual user traffic is not being directly observed.
SolarWinds relies primarily on agent-based and SNMP-based data collection. Agents installed on servers and endpoints collect performance metrics and transmit them to the central system. Network devices are monitored using standard protocols that provide information about bandwidth usage, device health, and interface performance.
This model is highly effective for internal systems because it provides granular visibility into infrastructure components. However, it is limited in its ability to observe external network conditions beyond the organization’s perimeter.
The difference between synthetic and agent-based telemetry reflects the broader distinction between external and internal monitoring philosophies. ThousandEyes focuses on experience simulation across the internet, while SolarWinds focuses on direct measurement of internal system behavior.
Visibility Scope and Monitoring Boundaries
One of the most defining differences between the two platforms is the scope of visibility they provide. ThousandEyes extends visibility across the entire internet path between users and applications. This includes local networks, ISP networks, cloud providers, and application endpoints.
This extended visibility allows organizations to understand how external factors influence performance. For example, if a user in one region experiences slow access to a cloud application, ThousandEyes can identify whether the issue is caused by regional ISP congestion, cloud routing inefficiencies, or external service degradation.
SolarWinds operates within a defined monitoring boundary that primarily includes systems owned or controlled by the organization. This includes internal networks, servers, applications, and cloud resources that are directly integrated into the monitoring system.
While SolarWinds can integrate with cloud environments, its primary strength remains in internal infrastructure visibility. It provides detailed insights into system health, but it does not extend deep into the public internet or external ISP networks.
This difference in monitoring boundaries makes each tool suitable for different types of operational challenges. ThousandEyes is designed for diagnosing external connectivity issues, while SolarWinds is designed for managing internal infrastructure performance.
Performance Troubleshooting Methodologies
Troubleshooting approaches differ significantly between ThousandEyes and SolarWinds due to their underlying data models and visibility scopes.
ThousandEyes uses a path-based troubleshooting methodology. It reconstructs the journey of data packets across networks and identifies where delays or failures occur along that path. This allows IT teams to isolate issues at specific network hops, whether they are within enterprise networks, ISPs, or cloud providers.
This approach is particularly effective for diagnosing intermittent or geographically distributed performance issues. By analyzing multiple vantage points, ThousandEyes can determine whether an issue is localized or widespread.
SolarWinds uses a component-based troubleshooting methodology. It focuses on identifying which internal system component is responsible for performance degradation. This may include servers, network devices, applications, or databases.
By correlating performance metrics across different components, SolarWinds helps IT teams pinpoint internal bottlenecks. For example, if an application is slow, the system can determine whether the cause is high CPU usage, database latency, or network congestion within the internal environment.
The key difference lies in directionality. ThousandEyes traces problems outward across the internet, while SolarWinds traces problems inward within controlled infrastructure.
Real-Time Monitoring and Data Refresh Mechanisms
Real-time monitoring is a critical capability in both platforms, but it is implemented differently based on their architectural designs.
ThousandEyes provides near real-time visibility into network conditions by continuously collecting data from distributed vantage points. These vantage points simulate user interactions and network traffic, allowing the system to detect changes in internet performance almost immediately.
Because it relies on multiple independent monitoring locations, ThousandEyes can detect regional variations in performance in real time. This is particularly useful for identifying localized outages or routing changes that may not affect all users simultaneously.
SolarWinds also provides real-time monitoring, but its data refresh mechanisms depend on polling intervals and agent reporting cycles. Network devices and servers are queried at regular intervals, and performance data is updated accordingly.
While this approach provides accurate internal monitoring, it may not capture instantaneous external network changes. However, it is highly effective for tracking system health and resource utilization within controlled environments.
The difference in real-time capabilities reflects the trade-off between external distribution and internal precision.
Cloud Dependency and Multi-Cloud Visibility
Cloud computing has become a central part of modern IT infrastructure, and both platforms address cloud monitoring differently.
ThousandEyes focuses on how cloud services interact with the broader internet ecosystem. It monitors cloud application delivery, inter-region communication, and connectivity between cloud providers and end users. This helps organizations understand how cloud performance is influenced by external network conditions.
In multi-cloud environments, ThousandEyes provides visibility into how different cloud providers communicate with each other. This is important for organizations that rely on hybrid or distributed cloud architectures.
SolarWinds focuses more on the internal performance of cloud-hosted resources. It monitors virtual machines, cloud servers, and applications running within cloud environments. This includes tracking resource utilization, system health, and application performance.
While SolarWinds can integrate with cloud APIs, its primary focus remains on infrastructure-level monitoring rather than internet-wide cloud connectivity.
The distinction is important because cloud performance issues can originate either inside the cloud environment or outside it. ThousandEyes helps identify external causes, while SolarWinds helps diagnose internal cloud issues.
Scalability Across Distributed Enterprises
Scalability is a key requirement for enterprise-grade monitoring platforms, and both tools handle it in different ways.
ThousandEyes scales by expanding its global network of monitoring agents. These agents are distributed across different regions and networks, allowing the platform to observe performance from multiple perspectives simultaneously. As organizations grow, they can add more monitoring points to increase visibility coverage.
This distributed scaling model is particularly effective for global enterprises that operate in multiple geographic regions. It ensures that performance monitoring reflects real-world user experiences across different parts of the world.
SolarWinds scales through modular expansion and distributed polling engines. Organizations can deploy additional monitoring nodes to handle increased infrastructure load. This allows the platform to support large-scale environments with thousands of devices and systems.
However, scaling SolarWinds typically involves increasing internal capacity rather than expanding external visibility. This reflects its focus on internal infrastructure rather than global network observation.
Both platforms scale effectively, but they scale in fundamentally different directions—one outward across the internet, and the other inward across enterprise systems.
Incident Detection and Root Cause Analysis
Incident detection and root cause analysis are central to IT operations, and both platforms provide strong but different capabilities in this area.
ThousandEyes identifies incidents based on changes in network behavior across the internet. It detects anomalies such as increased latency, packet loss, or routing changes. Once an issue is detected, it traces the path of affected traffic to identify where the disruption originates.
This makes it highly effective for identifying external causes of performance degradation, such as ISP outages or cloud service disruptions.
SolarWinds detects incidents based on internal system thresholds and performance metrics. It monitors servers, applications, and network devices for signs of abnormal behavior. When thresholds are exceeded, alerts are generated and correlated with other system events.
Root cause analysis in SolarWinds focuses on internal dependencies, helping IT teams identify whether the issue originates from hardware failures, software performance issues, or network congestion within the organization.
The difference is that ThousandEyes emphasizes external causality, while SolarWinds emphasizes internal causality.
Observability Depth and Analytical Granularity
Observability depth refers to how deeply a platform can analyze system behavior. ThousandEyes provides deep visibility into network paths and external dependencies, but it does not focus on internal system metrics such as CPU or memory usage.
Instead, its granularity lies in network-level telemetry, including hop-by-hop analysis, routing behavior, and internet health metrics. This makes it highly specialized for network performance analysis.
SolarWinds provides deep internal observability across infrastructure layers. It tracks system-level metrics, application behavior, and log data with high granularity. This allows IT teams to analyze internal system behavior in detail.
Its strength lies in connecting multiple internal data sources to provide a unified view of system health.
The two platforms complement each other in terms of observability depth. One provides external network granularity, while the other provides internal infrastructure granularity.
Operational Use in Modern IT Ecosystems
In modern IT ecosystems, organizations often rely on multiple monitoring tools to achieve full visibility. ThousandEyes is typically used in environments where understanding internet performance and external dependencies is critical. This includes cloud-heavy organizations, global enterprises, and digital service providers.
SolarWinds is commonly used in environments where internal infrastructure management is the primary concern. This includes enterprise IT departments responsible for maintaining servers, networks, and applications.
Both tools can coexist in complex IT ecosystems, but they serve different operational roles. ThousandEyes provides external intelligence, while SolarWinds provides internal operational control.
This separation of responsibilities reflects the broader evolution of IT monitoring, where no single tool can fully cover all aspects of modern digital infrastructure.
Conclusion
The comparison between ThousandEyes and SolarWinds highlights a fundamental shift in how modern IT environments are monitored and managed. Both platforms are powerful, widely adopted, and highly capable, yet they are designed with different philosophies that serve distinct operational needs. Understanding these differences is essential for organizations aiming to build reliable, scalable, and performance-driven digital systems.
ThousandEyes represents a modern approach centered on external visibility and internet intelligence. Its primary strength lies in revealing how data travels beyond organizational boundaries and how external networks influence application performance. In today’s cloud-driven ecosystem, where applications depend on third-party services, global routing paths, and distributed infrastructure, this level of visibility is increasingly critical. ThousandEyes allows organizations to observe real-world user experience from multiple geographic perspectives, helping them identify issues that traditional internal monitoring tools often cannot detect. It excels in scenarios where performance problems are caused by internet service providers, cloud routing inefficiencies, or regional connectivity issues.
On the other hand, SolarWinds represents a more traditional yet highly evolved approach focused on internal IT infrastructure management. It provides deep visibility into servers, network devices, applications, databases, and system logs within an organization’s controlled environment. This makes it an ideal solution for IT teams that need centralized operational control over complex infrastructures. SolarWinds is particularly effective in environments where maintaining uptime, optimizing internal systems, and ensuring infrastructure stability are top priorities. Its ability to correlate internal metrics across multiple systems allows IT teams to quickly identify root causes of performance issues within their own infrastructure.
The key difference between the two platforms lies in scope. ThousandEyes extends outward, mapping and analyzing the internet as an extension of the enterprise network. It answers the question of how and where performance is affected outside the organization’s direct control. SolarWinds, in contrast, extends inward, providing deep insights into internal systems and infrastructure components. It answers the question of what is happening inside the organization that affects performance and reliability.
This distinction becomes especially important in modern hybrid and multi-cloud environments. Businesses today rarely rely on a single infrastructure model. Instead, they operate across on-premises systems, private clouds, and multiple public cloud providers. In such environments, performance issues can arise from both internal and external sources. ThousandEyes helps identify external dependencies and internet-related bottlenecks, while SolarWinds ensures that internal systems remain optimized and stable.
From a strategic perspective, the choice between these tools is not simply about features but about operational priorities. Organizations focused on delivering digital services to global audiences often prioritize external visibility to ensure a consistent user experience across regions. For them, understanding internet behavior and external dependencies is critical. Meanwhile, organizations with complex internal infrastructures prioritize operational efficiency, system reliability, and infrastructure control, making SolarWinds a more suitable choice.
It is also important to recognize that these tools are not mutually exclusive. In many enterprise environments, they are used together to create a comprehensive monitoring strategy. ThousandEyes provides the external lens, capturing how the internet and cloud ecosystems affect performance, while SolarWinds provides the internal lens, ensuring that infrastructure components operate efficiently and reliably. Together, they offer a complete picture of digital performance from user experience to backend systems.
Ultimately, modern network monitoring is no longer about choosing a single tool but about understanding how different layers of visibility work together. ThousandEyes and SolarWinds represent two essential perspectives in this ecosystem—one focused on global connectivity and user experience, and the other focused on internal stability and operational control. Organizations that understand and leverage both perspectives are better positioned to maintain performance, reduce downtime, and deliver seamless digital experiences in an increasingly complex technological landscape.