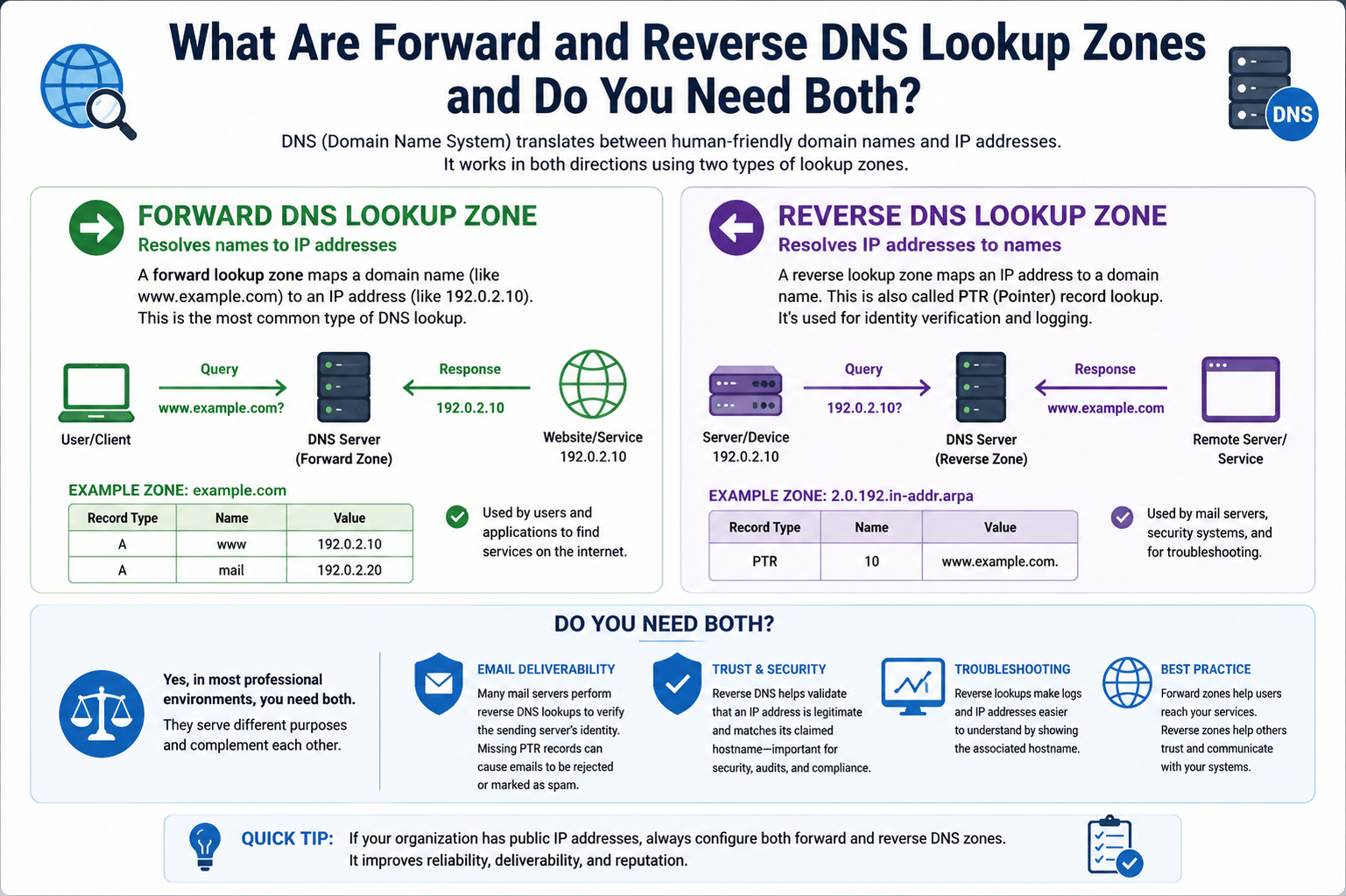
The Domain Name System, more commonly known as DNS, is one of the most important services on modern networks. Every time someone opens a website, sends an email, connects to a server, or accesses a cloud platform, DNS quietly works in the background to translate human-friendly names into machine-readable IP addresses. Without DNS, people would need to memorize long strings of numbers just to browse the internet or communicate across networks.
Among the most important concepts within DNS are Forward Lookup Zones and Reverse Lookup Zones. These two types of DNS zones form the foundation of how devices identify each other across local and global networks. Although they perform opposite functions, they often work together to improve reliability, security, troubleshooting, and communication between systems.
To understand why both lookup zones matter, it helps to first understand how DNS itself operates and why DNS zones exist in the first place.
DNS can be compared to a massive distributed directory service. Instead of storing all information in one place, DNS spreads responsibility across many servers throughout the world. Each DNS server manages a specific portion of the namespace. This structure makes DNS scalable, efficient, and resilient.
Within DNS, a “zone” refers to an administrative section of the DNS namespace. A DNS zone contains records related to a particular domain or network segment. These records define how names and addresses are resolved. For example, a company domain may contain records for its website, mail server, internal systems, remote access services, and cloud applications.
DNS zones exist because managing all internet records in one giant database would be impossible. Dividing responsibilities into smaller zones allows organizations to control their own records independently while still participating in the global DNS system.
A DNS zone may contain several different record types, each serving a unique purpose. The most common record type is the A record, which maps a hostname directly to an IPv4 address. If a user enters a domain name into a browser, the DNS server looks up the matching A record and returns the corresponding IP address.
Another common record type is the CNAME record. Instead of mapping directly to an IP address, a CNAME points one hostname to another hostname. This is especially useful when multiple services should resolve to the same destination without creating duplicate records.
MX records are responsible for mail routing. These records tell other mail servers where email for a domain should be delivered. TXT records store text information and are commonly used for security verification methods, email authentication, and ownership validation.
All these records are stored inside DNS zones, which are maintained either as text-based zone files or within specialized databases managed by DNS server software. Traditional DNS implementations often store zone data in plain text files, making them readable and editable by administrators. Modern enterprise environments may instead store DNS information within directory services or cloud management platforms.
In enterprise environments, DNS frequently integrates with centralized identity systems. In many corporate networks, DNS data is replicated automatically between servers to ensure consistency and availability. This replication allows users to continue resolving names even if one server becomes unavailable.
DNS zones can also be divided into subdomains. A subdomain represents a smaller administrative section beneath a larger domain. For example, an organization may separate departments, branch offices, or business units using subdomains. This segmentation allows different teams to manage their own DNS records independently while remaining part of the larger organizational namespace.
The importance of DNS zones becomes especially clear in large environments where thousands of devices, servers, and services require consistent name resolution. Without structured DNS management, networks would quickly become disorganized and difficult to maintain.
Two major types of DNS lookup zones exist: forward lookup zones and reverse lookup zones. Although both are related to DNS resolution, they serve very different purposes.
A forward lookup zone converts hostnames into IP addresses. This is the type of DNS lookup most people use every day without realizing it. When someone types a website address into a browser, the device sends a DNS query asking for the IP address associated with that name. The DNS server checks the forward lookup zone and returns the correct address.
Forward lookup zones are essential because humans naturally remember names better than numbers. Names are easier to organize, easier to document, and easier to communicate between teams. Imagine trying to manage hundreds of servers identified only by numerical IP addresses. Even small environments would become confusing.
Forward lookups simplify network communication dramatically. Instead of remembering numerical addresses, users can access systems using meaningful names such as mail.company.local or server01.office.local. Applications also rely heavily on forward lookups when establishing communication between systems.
Inside a forward lookup zone, administrators create records that associate names with addresses. These records may represent websites, email servers, cloud services, printers, databases, or internal applications. Once configured, users and systems can access those resources through simple, recognizable hostnames.
Forward lookup zones also support flexibility within networks. If a server’s IP address changes, administrators only need to update the DNS record rather than reconfigure every device that accesses the server. This abstraction layer significantly simplifies infrastructure management.
DNS caching further improves performance. Once a system resolves a hostname, the result is temporarily stored locally. This reduces repeated queries and speeds up future connections. The duration of caching depends on a setting known as Time to Live, often abbreviated as TTL. TTL values define how long DNS information remains valid before another lookup is required.
Although forward lookups receive most of the attention, reverse lookup zones are equally important in many environments.
A reverse lookup zone performs the opposite operation. Instead of converting a name into an IP address, it converts an IP address back into a hostname. Reverse DNS exists primarily for validation, troubleshooting, monitoring, and security purposes.
At first glance, reverse lookups may seem unnecessary because most users interact with names rather than addresses. However, many systems and services rely heavily on reverse DNS behind the scenes.
One of the most common uses of reverse DNS involves email security. Mail servers frequently check reverse DNS records to verify whether incoming messages originate from legitimate systems. If an IP address lacks a valid reverse record, some mail systems may flag the message as suspicious or reject it entirely.
Reverse DNS is also useful for logging and diagnostics. Network administrators often analyze firewall logs, server logs, and traffic reports containing large numbers of IP addresses. Reverse lookups help translate those addresses into recognizable hostnames, making analysis much easier.
Troubleshooting network connectivity also becomes more manageable with reverse DNS. Tools like traceroute and network scanners often display reverse lookup information alongside IP addresses. Seeing meaningful names instead of raw addresses helps administrators identify devices more quickly.
Reverse lookup zones use a special naming structure based on reversed IP addresses. Instead of organizing records by hostname, reverse zones organize records by network ranges. Pointer records, commonly known as PTR records, are used to map IP addresses back to hostnames.
The structure may initially seem unusual because IP octets appear in reverse order. This reversed hierarchy allows DNS servers to delegate authority efficiently across network boundaries.
Unlike forward zones, reverse zones usually contain fewer records because each IP address generally maps to only one primary hostname. While multiple names can point to the same IP address through forward records, reverse mappings are typically designed as one-to-one relationships.
This difference creates an important distinction between forward and reverse DNS behavior. Multiple hostnames may successfully resolve to a single server, but reverse lookups usually return only one canonical name for an address.
Because forward and reverse zones are separate, they do not automatically synchronize unless administrators specifically configure them to do so. This independence sometimes leads to mismatched records, especially in poorly maintained environments.
For example, a forward record may point a hostname to an IP address, but the corresponding reverse record might be missing or outdated. In such cases, forward resolution still works normally, but reverse validation may fail.
This separation explains why some services operate correctly even when reverse DNS is incomplete. Basic web browsing generally depends only on forward lookups. However, enterprise applications, mail systems, security platforms, and monitoring tools often rely on reverse DNS for additional verification.
Organizations frequently underestimate the importance of maintaining reverse lookup zones because users rarely interact with them directly. As a result, reverse DNS often becomes neglected compared to forward DNS management.
In modern networks, however, reverse DNS plays an increasingly important role in security and automation. Security platforms use reverse lookups to identify suspicious connections. Monitoring systems rely on hostnames to generate readable alerts. Authentication services may verify reverse records during validation processes.
Cloud computing has further increased the complexity of DNS management. Modern infrastructures often include hybrid environments containing on-premises servers, cloud platforms, containers, and remote services. Coordinating DNS across these distributed systems requires careful planning.
Many cloud providers now offer managed DNS services that simplify zone administration. These services automate replication, improve availability, and integrate with modern infrastructure tools. Despite these advancements, the core concepts of forward and reverse lookup zones remain unchanged.
Internal DNS zones are another important aspect of enterprise networking. Organizations commonly maintain private DNS zones that are inaccessible from the public internet. These zones allow internal systems to communicate securely without exposing sensitive infrastructure externally.
Active Directory environments frequently rely on internal DNS zones for authentication and service discovery. Domain controllers, authentication services, and internal applications depend heavily on accurate DNS records to function correctly.
In these environments, DNS becomes much more than a simple website lookup mechanism. It evolves into a critical infrastructure component supporting identity management, communication, resource discovery, and operational stability.
As networks grow more complex, DNS administration becomes increasingly important. Poor DNS configuration can lead to service outages, authentication failures, communication delays, and security vulnerabilities.
Understanding the distinction between forward and reverse lookup zones helps administrators design more reliable infrastructures. Forward zones ensure users and applications can locate services efficiently, while reverse zones provide verification and visibility that support security and diagnostics.
Even though reverse DNS may not always be strictly required for basic connectivity, its absence can create operational challenges. Systems that rely on validation, logging, or reputation analysis often behave unpredictably when reverse records are incomplete or inaccurate.
Maintaining both forward and reverse lookup zones improves consistency across the network. It allows administrators to identify devices quickly, validate communications, simplify troubleshooting, and support services that depend on hostname verification.
DNS may operate quietly in the background, but nearly every modern digital interaction depends on it. Understanding how lookup zones function provides valuable insight into the infrastructure that powers communication across networks large and small.
Forward and Reverse DNS Lookup Zones in Real-World Network Operations
DNS is often described as the phonebook of the internet, but in real-world network environments, its role extends far beyond simple name resolution. Modern organizations depend on DNS for communication between servers, cloud systems, applications, authentication platforms, and security services. As infrastructures grow more distributed and interconnected, forward and reverse DNS lookup zones become increasingly important for operational stability.
Although many people encounter DNS only while browsing websites, administrators work with DNS constantly behind the scenes. Every server deployment, service migration, cloud integration, or security implementation usually involves DNS planning. Forward and reverse lookup zones play distinct roles in these operations, and understanding how they function in practical environments helps explain why both are valuable.
Forward lookup zones are the foundation of almost every network interaction. Whenever a device needs to contact another system using a hostname, a forward lookup occurs. This process happens continuously across enterprise networks, often without users realizing it.
For example, when an employee logs into a company application, the workstation may contact authentication servers, database servers, storage systems, and cloud services using DNS names rather than IP addresses. Each connection depends on successful forward resolution.
The reason hostnames are preferred is simple: names remain consistent even when infrastructure changes. IP addresses may change because of hardware replacements, virtualization, cloud migration, network redesign, or failover operations. Hostnames provide an abstraction layer that shields users and applications from these changes.
This flexibility becomes critical in environments with large numbers of servers. Imagine a data center containing hundreds or thousands of systems. Managing those systems entirely by IP address would create confusion and increase the likelihood of configuration errors. DNS allows administrators to organize resources logically using descriptive names.
Naming conventions are especially important in enterprise environments. Administrators often structure hostnames according to location, function, operating system, department, or service type. This organization makes infrastructure easier to understand and maintain.
For instance, a hostname may indicate whether a server belongs to a branch office, hosts a database, or provides authentication services. With consistent naming standards, administrators can quickly identify systems without manually checking IP addresses.
Forward lookup zones also simplify application deployment. Many applications rely on DNS names during installation or configuration. If infrastructure changes later, administrators can update DNS records instead of modifying every application individually.
Load balancing is another major benefit of forward DNS. Multiple servers can share responsibility for handling traffic under a single hostname. DNS may return different IP addresses for the same hostname, distributing requests across multiple systems.
This technique improves performance and availability. If one server becomes unavailable, traffic can continue flowing to remaining systems. Cloud environments rely heavily on DNS-based load balancing because services frequently scale dynamically.
Content delivery networks also depend on forward DNS. When users access online content, DNS may direct them to geographically closer servers to reduce latency and improve performance. This process happens automatically through intelligent DNS resolution.
Containerized applications and microservices have increased DNS importance even further. In modern cloud-native environments, services constantly start, stop, and move between hosts. DNS helps applications locate one another dynamically without requiring static IP configurations.
Service discovery mechanisms frequently integrate with DNS to allow automated communication between distributed components. Without reliable forward lookup zones, many modern application architectures would struggle to function efficiently.
Despite the importance of forward DNS, reverse lookup zones provide critical operational value in areas that users rarely notice directly.
Reverse DNS becomes especially valuable during troubleshooting. Network administrators frequently encounter IP addresses in logs, monitoring systems, firewall events, and diagnostic tools. Reverse lookups translate those addresses into recognizable hostnames, making investigations faster and more accurate.
Consider a scenario involving unusual network traffic. A firewall log may show repeated connections from a specific IP address. Without reverse DNS, administrators would need to manually identify the device associated with that address. With properly maintained reverse zones, the hostname appears immediately, providing useful context.
This capability saves significant time during incident response. Security teams often investigate suspicious activity under tight deadlines. Reverse lookups help analysts identify compromised systems, unauthorized devices, or unexpected communications more quickly.
Monitoring systems also benefit from reverse DNS. Infrastructure monitoring platforms collect enormous amounts of network data. Displaying hostnames instead of raw addresses makes alerts more understandable and actionable.
When a monitoring dashboard reports that “database-server-01” is unreachable, administrators immediately know which system requires attention. If the dashboard displays only an IP address, additional investigation becomes necessary before troubleshooting can begin.
Reverse DNS also improves readability in network diagnostic tools. Commands such as traceroute often display reverse lookup results automatically. Instead of seeing only intermediary IP addresses, administrators can identify routers, gateways, or provider infrastructure along the network path.
Internet service providers and hosting companies frequently rely on reverse DNS as well. Customer support teams use reverse lookups to identify devices, diagnose routing issues, and validate network ownership.
Email systems represent one of the most important areas where reverse DNS matters significantly. Modern mail servers perform extensive reputation checks to combat spam, phishing, and fraudulent communications.
When a mail server receives an incoming message, it often performs a reverse lookup on the sender’s IP address. The server checks whether the address resolves to a legitimate hostname. It may also perform a forward lookup on that hostname to confirm consistency.
This process helps verify that the sender appears legitimate. Many spam systems operate from improperly configured hosts lacking valid reverse DNS records. As a result, mail systems may distrust messages originating from addresses without proper reverse mappings.
A mismatch between forward and reverse DNS can negatively affect email delivery. Even legitimate organizations may encounter problems if their reverse records are outdated or incorrectly configured.
This issue becomes especially important for businesses operating their own mail infrastructure. Without accurate reverse DNS, outbound messages may be flagged as spam or rejected entirely by recipient systems.
Cloud environments introduce additional reverse DNS considerations. Public cloud providers often control reverse DNS delegation for customer IP ranges. Organizations hosting services in the cloud may need to configure reverse records through provider-specific management interfaces.
Reverse DNS delegation can become complex when organizations use leased IP space from internet providers. In such cases, the provider retains authority over reverse zones unless delegation arrangements are established.
This dependency explains why reverse DNS implementation sometimes lags behind forward DNS deployment. Forward records are usually fully controlled by the organization managing the domain, while reverse zones may involve coordination with external providers.
Internal reverse DNS, however, is usually easier to manage because organizations control their own private address spaces. Many enterprises maintain extensive reverse zones for internal troubleshooting and operational visibility.
Dynamic DNS updates further enhance DNS management in modern environments. Devices can automatically register or update their DNS records as network conditions change. This automation is common in enterprise operating systems and directory-integrated networks.
For example, when a workstation receives a new IP address through DHCP, it may automatically update both forward and reverse DNS records. This synchronization helps maintain accurate mappings without requiring manual administration.
Automation becomes essential in environments containing large numbers of devices. Manual DNS management is time-consuming and prone to errors. Automated updates improve consistency while reducing administrative overhead.
However, automated DNS updates also introduce security considerations. Unauthorized systems should not be allowed to modify DNS records freely. Many organizations therefore implement secure update mechanisms tied to authentication systems.
DNS security has become increasingly important as cyber threats continue evolving. Attackers frequently target DNS because it influences nearly all network communication. Compromised DNS systems can redirect users, intercept traffic, or disrupt services.
Forward and reverse DNS records both contribute to security visibility. Security tools use DNS data to identify malicious domains, suspicious traffic patterns, and unauthorized systems. Reverse lookups often help investigators identify devices communicating with potentially harmful destinations.
DNS logging provides another valuable security capability. Organizations may collect DNS query data to analyze user activity, detect malware behavior, or investigate incidents. Reverse DNS enriches these logs by associating addresses with meaningful hostnames.
DNS-based filtering systems also depend heavily on reliable name resolution. Security platforms may block access to dangerous domains, phishing sites, or command-and-control infrastructure based on DNS requests.
Network segmentation strategies frequently involve DNS design as well. Organizations may create separate zones for internal systems, external services, development environments, or isolated departments. This segmentation improves manageability and limits exposure.
Cloud migration projects often highlight the importance of DNS planning. Applications moving between environments require consistent name resolution to maintain availability. DNS enables organizations to redirect traffic gradually during migrations without disrupting users.
Disaster recovery planning also relies heavily on DNS flexibility. In failover scenarios, DNS records can redirect users to backup systems located in alternate data centers or cloud regions. Proper TTL configuration becomes especially important during these events because cached records may delay traffic redirection.
Global organizations often deploy distributed DNS infrastructures to improve resilience and performance. Multiple DNS servers across geographic regions ensure continued availability even if one site experiences problems.
Redundancy is crucial because DNS outages can effectively disable access to services even when servers themselves remain operational. If users cannot resolve hostnames, applications may appear unavailable despite functioning normally.
DNS replication helps maintain consistency between servers. Enterprise DNS platforms synchronize records automatically to prevent discrepancies. However, administrators must still monitor replication carefully to avoid stale or conflicting data.
Forward and reverse lookup zones also support asset management efforts. Accurate DNS records help organizations track devices, identify unused systems, and maintain visibility across complex environments.
In virtualized and cloud-based infrastructures where resources change frequently, DNS often provides one of the most reliable indicators of active systems. Reverse lookups, in particular, help correlate network activity with actual device names.
Many compliance frameworks indirectly depend on proper DNS management as well. Security audits, vulnerability assessments, and incident investigations frequently reference DNS information when evaluating network integrity and operational practices.
Despite all these advantages, DNS maintenance is sometimes neglected because successful DNS operation tends to remain invisible. Users notice immediately when DNS fails, but rarely think about it when everything works correctly.
This invisibility can lead organizations to underestimate the importance of maintaining accurate lookup zones. Outdated records, inconsistent naming conventions, missing reverse entries, and poor documentation may gradually accumulate over time.
As infrastructures expand, these issues become increasingly problematic. Troubleshooting slows down, security visibility decreases, and operational complexity increases. Proper DNS governance therefore becomes essential for long-term network reliability.
Forward lookup zones remain the primary mechanism enabling users and systems to locate services efficiently. Reverse lookup zones complement them by adding validation, traceability, readability, and diagnostic value.
Together, these lookup zones form a critical part of modern network infrastructure. Whether supporting cloud platforms, internal business applications, email systems, or security monitoring, DNS continues to operate as one of the most fundamental services powering digital communication.
Why Maintaining Both Forward and Reverse DNS Lookup Zones Matters
Many organizations initially focus almost entirely on forward DNS resolution because it directly affects user access to websites, applications, and services. If users can reach systems successfully, administrators may assume DNS is functioning properly. However, this perspective often overlooks the broader operational role that DNS plays throughout a network environment.
Forward and reverse DNS lookup zones together create a more complete and reliable infrastructure. While forward zones enable connectivity, reverse zones provide context, validation, accountability, and visibility. Networks that maintain both lookup types consistently tend to experience fewer operational issues and more efficient troubleshooting processes.
As enterprise environments become increasingly dependent on automation, cloud computing, remote connectivity, and security monitoring, the importance of maintaining accurate DNS information grows significantly. Even though reverse DNS may not always appear essential during normal operations, its absence can create hidden problems that surface during troubleshooting, audits, security investigations, or service integrations.
One of the most overlooked aspects of DNS administration is consistency. A well-managed DNS environment allows administrators to trust the information they see. When forward and reverse records align properly, teams gain confidence that systems are correctly identified and network activity can be interpreted accurately.
This consistency becomes especially important in environments containing thousands of endpoints, virtual machines, containers, cloud workloads, and remote devices. Without reliable DNS mapping, identifying systems quickly becomes difficult. Administrators may spend valuable time manually correlating IP addresses with devices during outages or investigations.
Reverse lookup zones help solve this challenge by associating IP addresses with recognizable hostnames. During high-pressure situations such as security incidents or service outages, rapid identification matters greatly. Administrators can react more effectively when they immediately recognize the systems involved.
For example, imagine a network monitoring platform reports excessive outbound traffic from a specific IP address. If reverse DNS is properly configured, the monitoring system may instantly reveal the hostname associated with that address. Administrators can identify whether the system is a database server, user workstation, application server, or unauthorized device without additional investigation.
Without reverse DNS, analysts may need to search inventory databases, review DHCP logs, or manually trace the address assignment. This additional effort slows down incident response and increases operational complexity.
Large organizations often manage multiple network segments across offices, cloud providers, and geographic regions. DNS naming conventions become extremely valuable in these environments because they provide structure and clarity.
A properly designed naming system may identify device type, physical location, department, operating system, or application role directly within the hostname itself. Reverse lookups then expose this contextual information whenever administrators encounter an IP address.
This approach significantly improves troubleshooting workflows. Instead of investigating anonymous numerical addresses, support teams interact with meaningful system names that provide immediate operational insight.
Reverse DNS also improves collaboration between technical teams. Security analysts, system administrators, network engineers, and support personnel frequently review shared logs and monitoring data. Human-readable hostnames simplify communication and reduce misunderstandings.
Operational efficiency becomes even more important in hybrid cloud environments. Modern organizations commonly operate across on-premises data centers, public cloud platforms, remote branches, and software-defined infrastructures simultaneously.
In these distributed environments, IP addresses may change frequently because of scaling operations, virtualization, dynamic provisioning, or orchestration tools. DNS provides stability by allowing systems to communicate through consistent names rather than constantly changing addresses.
Cloud-native applications rely heavily on DNS because services may exist only temporarily. Containers and workloads can be created and destroyed dynamically within seconds. Automated DNS registration allows these systems to remain discoverable despite rapid infrastructure changes.
Forward lookup zones support this dynamic connectivity by ensuring applications can locate one another automatically. Reverse lookup zones complement this process by helping administrators trace activity back to specific workloads or services.
Observability platforms also depend heavily on DNS information. Modern monitoring solutions collect enormous volumes of telemetry data from servers, applications, network devices, and cloud platforms. DNS enrichment helps transform raw network information into understandable operational intelligence.
For example, monitoring systems may record millions of network connections daily. Reverse lookups allow analysts to interpret these connections more easily because recognizable hostnames appear instead of unfamiliar addresses.
Security operations centers rely particularly heavily on this visibility. Threat detection platforms analyze DNS activity to identify malware communication, suspicious domains, lateral movement, and unauthorized network behavior.
DNS is frequently targeted by attackers because it influences nearly all network communication. Malicious actors may attempt to manipulate DNS records, redirect traffic, or establish covert communication channels using DNS queries.
Maintaining accurate DNS records helps organizations detect anomalies more effectively. Unexpected reverse lookup results or mismatched forward and reverse mappings may indicate unauthorized changes or compromised systems.
DNS logging has become an important component of modern cybersecurity strategies. Organizations often collect DNS query logs to identify malicious activity patterns. Reverse lookup information enriches these logs by providing device identification alongside network addresses.
Threat hunting activities also benefit from reliable reverse DNS. Analysts reviewing historical network traffic can identify suspicious systems more quickly when hostnames are consistently maintained.
Email infrastructure remains one of the clearest examples of why reverse DNS matters. Spam filtering technologies rely heavily on sender validation techniques, and reverse DNS plays an important role in this process.
When an email server receives a message, it may verify whether the sender’s IP address resolves to a legitimate hostname. Some systems also check whether the hostname maps back to the same IP address through forward resolution.
This validation process helps identify suspicious or poorly configured senders. Many spam campaigns originate from compromised systems lacking proper reverse DNS records. As a result, missing or inconsistent reverse mappings can damage email reputation even for legitimate organizations.
Businesses operating their own mail servers therefore need carefully maintained reverse lookup zones. Incorrect reverse DNS can cause legitimate emails to be rejected, delayed, or classified as spam by recipient systems.
Internet service providers and hosting companies also use reverse DNS for customer identification and abuse management. Reverse lookups help providers investigate complaints, trace traffic sources, and validate ownership of assigned address ranges.
Public-facing services often benefit from reverse DNS as well. Network diagnostic tools display reverse records during connectivity tests, allowing administrators and external partners to identify systems more easily.
Traceroute utilities provide a useful example. During path analysis, traceroute displays intermediate network devices encountered between source and destination systems. Reverse DNS allows these devices to appear with meaningful names rather than only numerical addresses.
This visibility helps engineers identify routing issues, provider boundaries, or misconfigured devices more efficiently. Reverse records effectively turn raw network paths into understandable infrastructure maps.
Maintaining DNS accuracy also supports automation initiatives. Modern infrastructure increasingly depends on automated provisioning, orchestration, and configuration management systems. These tools often interact with DNS programmatically.
Automated workflows may create, update, or remove DNS records dynamically as resources change. Maintaining synchronization between forward and reverse zones becomes essential for ensuring reliable automation behavior.
Dynamic DNS updates help organizations manage large environments more efficiently. Devices can automatically register their names and addresses with DNS servers whenever changes occur.
This automation reduces administrative overhead and minimizes the likelihood of stale records. However, organizations must still implement proper governance to ensure DNS data remains accurate and secure.
DNS scavenging mechanisms are commonly used to remove outdated records automatically. Without cleanup processes, DNS databases may accumulate obsolete entries from decommissioned systems, expired leases, or temporary workloads.
Stale DNS records create several problems. Administrators may waste time investigating systems that no longer exist, monitoring platforms may generate false alerts, and security analysts may misinterpret network activity.
Reverse lookup zones are particularly vulnerable to neglect because users rarely interact with them directly. Organizations sometimes deploy forward records carefully while ignoring reverse mappings entirely.
This imbalance often becomes apparent only during troubleshooting or compliance reviews. Missing reverse records can reduce visibility, complicate investigations, and interfere with systems that depend on hostname validation.
Network documentation practices also benefit from accurate DNS management. DNS effectively serves as a living directory of infrastructure resources. Well-maintained DNS zones provide valuable operational information even when formal documentation becomes outdated.
Asset management systems frequently integrate with DNS to improve visibility across large environments. DNS records help identify active devices, track naming consistency, and support inventory management efforts.
Virtualization platforms further increase the importance of DNS coordination. Virtual machines can move between hosts, migrate across clusters, or scale dynamically depending on workload demands. DNS ensures these systems remain reachable despite infrastructure mobility.
Disaster recovery planning also depends heavily on DNS flexibility. During failover events, organizations may redirect traffic to alternate systems or secondary locations by updating DNS records.
TTL settings become critically important during these scenarios. Shorter TTL values allow changes to propagate more quickly, enabling faster redirection during outages or maintenance operations.
However, shorter TTLs also increase query frequency because systems cache records for less time. Administrators must balance responsiveness against efficiency when configuring DNS caching behavior.
Global organizations often deploy redundant DNS infrastructures to improve resilience. Multiple DNS servers distributed across geographic regions help ensure availability even if one location experiences failures.
DNS redundancy is essential because name resolution failures can disrupt entire environments even when underlying applications remain operational. Users cannot access systems they cannot resolve.
Replication mechanisms help synchronize DNS information between servers. Inconsistent replication may create conflicting records or stale data, leading to unpredictable behavior across the network.
Maintaining accurate reverse zones becomes particularly important in environments with overlapping responsibilities between teams. Different administrators may manage network infrastructure, server deployment, security operations, and cloud resources simultaneously.
Consistent DNS governance ensures all teams rely on the same authoritative information. Clear ownership policies and automated update mechanisms help maintain accuracy as infrastructures evolve.
As organizations adopt zero-trust security models, identity verification and visibility become increasingly important. DNS contributes indirectly to these efforts by improving system identification and supporting monitoring capabilities.
Although DNS alone does not provide comprehensive security, accurate forward and reverse records strengthen operational awareness across the environment. Visibility remains one of the most valuable assets during both routine administration and incident response.
Organizations sometimes ask whether reverse DNS is truly necessary if forward resolution already functions correctly. Technically, many services operate without reverse lookups. Basic web browsing, internal application access, and many standard network operations depend primarily on forward DNS.
However, operational maturity often determines whether reverse DNS becomes valuable. Smaller environments with minimal complexity may function adequately without extensive reverse zones. Larger environments usually benefit substantially from maintaining both lookup types consistently.
The advantages become increasingly noticeable as infrastructures grow more dynamic and interconnected. Cloud computing, virtualization, automation, security analytics, and distributed applications all increase reliance on accurate infrastructure metadata.
Reverse DNS effectively provides an additional layer of intelligence that improves visibility, diagnostics, validation, and manageability. While users rarely notice it directly, administrators frequently depend on it during real-world operations.
Forward and reverse lookup zones are therefore not competing technologies but complementary components of a larger DNS ecosystem. Forward DNS enables communication by translating names into addresses. Reverse DNS enhances understanding by translating addresses back into names.
Together, they create a more transparent, maintainable, and operationally efficient network environment capable of supporting modern infrastructure demands.
One of the most frequent DNS issues involves stale records. Over time, networks constantly change. Servers are replaced, applications move to new environments, virtual machines are removed, and cloud workloads scale dynamically. If DNS records are not updated accordingly, outdated information begins accumulating inside lookup zones.
Stale forward records may direct users or applications to systems that no longer exist. This can lead to failed connections, delayed troubleshooting, or confusion during maintenance activities. Reverse lookup zones experience similar issues when old IP-to-hostname mappings remain long after devices have been decommissioned.
Conclusion
Forward and reverse DNS lookup zones are fundamental components of modern network infrastructure, and together they form the backbone of reliable digital communication. While many users interact with DNS every day without realizing it, organizations depend heavily on accurate DNS resolution to support websites, cloud services, email systems, remote access, authentication platforms, and internal applications. Understanding how these lookup zones function helps administrators build networks that are not only efficient but also secure, scalable, and easier to manage.
A forward lookup zone is responsible for translating domain names into IP addresses, allowing users and applications to locate systems quickly and efficiently. This process simplifies communication across networks because people can work with meaningful hostnames instead of numerical IP addresses. Forward DNS plays a direct role in nearly every online activity, from browsing websites to accessing enterprise services and cloud platforms. Without forward lookup zones, modern networking would become extremely difficult to manage.
Reverse lookup zones, on the other hand, provide the ability to translate IP addresses back into hostnames. Although reverse DNS often operates quietly in the background, it delivers significant operational value. Reverse lookups help administrators troubleshoot network problems, investigate suspicious activity, improve monitoring visibility, and validate system identities. Many critical services, especially email servers and security platforms, rely on reverse DNS to confirm the legitimacy of devices and connections.
One of the most important points to understand is that forward and reverse lookup zones are separate systems that complement one another rather than replace each other. Forward DNS ensures connectivity, while reverse DNS improves traceability, readability, and verification. Organizations that maintain both lookup zones consistently usually experience better operational efficiency and stronger infrastructure visibility.
As networks continue evolving through cloud computing, virtualization, automation, and distributed services, DNS management becomes increasingly important. Modern infrastructures contain rapidly changing workloads, dynamic applications, and large numbers of connected devices. Accurate DNS records help organizations maintain stability in these complex environments by ensuring systems can communicate reliably and administrators can identify resources quickly.
Proper DNS management also contributes to cybersecurity. Attack detection, traffic analysis, logging, and reputation validation all benefit from accurate forward and reverse DNS records. During troubleshooting or incident response, reliable DNS information can significantly reduce investigation time and improve decision-making.
Maintaining clean and organized lookup zones requires ongoing attention. Outdated records, inconsistent naming conventions, and neglected reverse mappings can create confusion and operational challenges. Automated updates, structured naming policies, regular monitoring, and proper security controls help organizations keep DNS environments reliable and efficient.
Ultimately, forward and reverse DNS lookup zones are both valuable parts of a healthy network ecosystem. Even though forward DNS receives most of the attention because it directly affects user access, reverse DNS provides the visibility and validation that modern enterprise environments increasingly require. Together, they create a more manageable, secure, and resilient networking foundation capable of supporting the growing demands of today’s digital infrastructure.