In modern IT environments, network reliability and performance are not optional features. They are essential requirements that directly affect how applications run, how users access services, and how organizations maintain continuity. One of the key technologies used to strengthen both performance and resilience in networks is NIC teaming, a method that combines multiple physical network connections into a single logical connection.
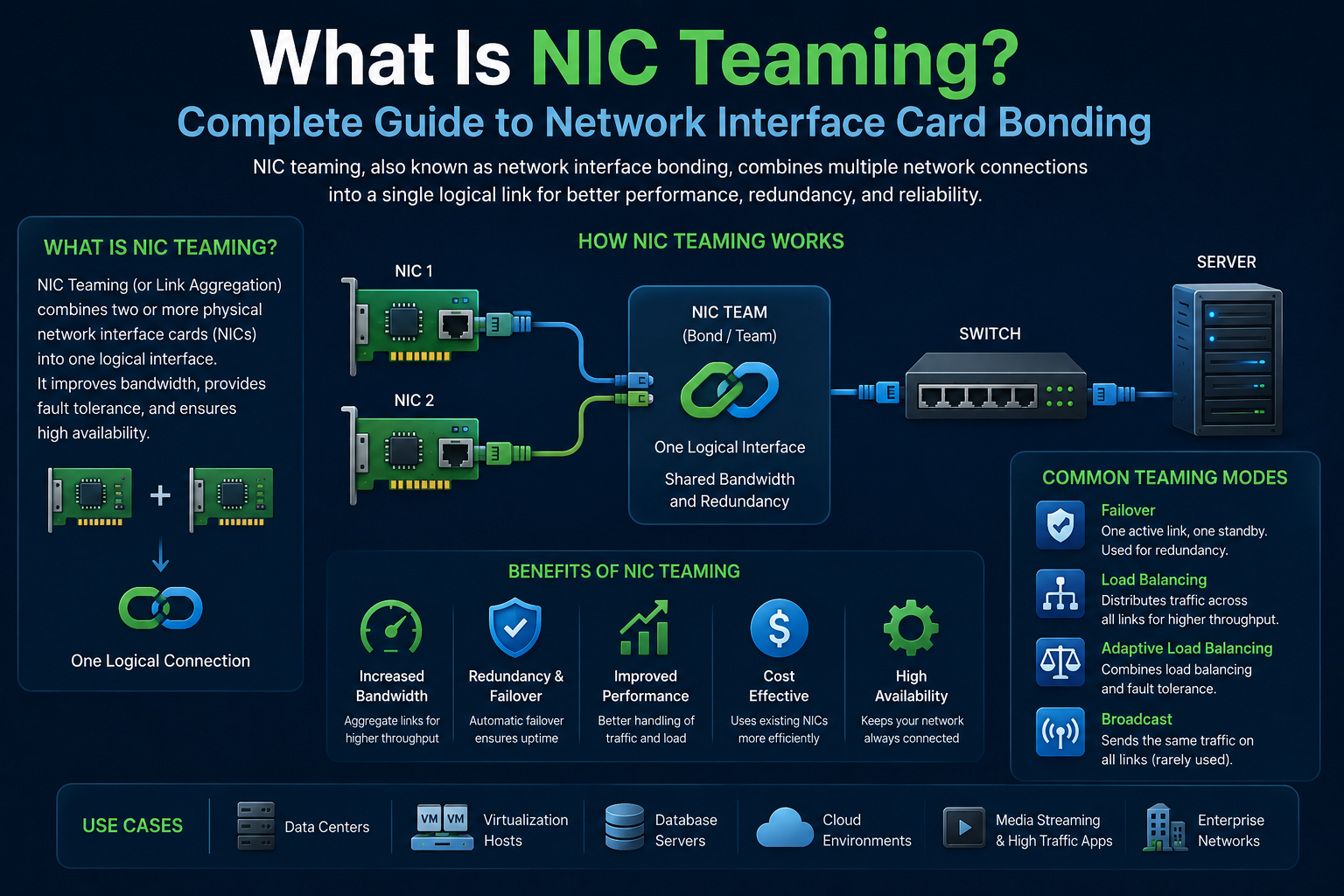
To understand NIC teaming properly, it helps to begin with the basic role of a network interface card. A network interface card, often shortened to NIC, is the hardware component that allows a computer or server to connect to a network. Each NIC provides a single communication path between a device and the network infrastructure. In simple setups, one device typically uses one NIC to send and receive data. While this works for basic needs, it introduces limitations when traffic increases or when reliability becomes critical.
NIC teaming changes this structure by combining multiple NICs so they function as a unified system. Instead of relying on a single communication path, a server can use several network interfaces at the same time. These interfaces are grouped logically so that the operating system and network view them as a single connection. This approach introduces both performance improvements and redundancy, which are two of the most important goals in network design.
One of the key reasons NIC teaming exists is to address bandwidth limitations. A single network interface can only handle a certain amount of data traffic. When demand increases, such as in data centers, virtualization environments, or high-traffic applications, a single NIC can become a bottleneck. By combining multiple NICs, the total available bandwidth increases. This allows more data to flow simultaneously without overwhelming a single connection.
Another major reason for using NIC teaming is fault tolerance. Hardware failures are inevitable in any system, and network interfaces are no exception. If a single NIC fails in a traditional setup, the server loses its network connectivity, leading to service interruptions. With NIC teaming, however, other active interfaces can continue handling traffic even if one NIC fails. This ensures that connectivity is maintained and downtime is minimized.
NIC teaming also improves overall network efficiency by distributing traffic across multiple interfaces. Instead of sending all data through a single path, the system intelligently balances network traffic across available NICs. This distribution helps reduce congestion and improves responsiveness, especially in environments where multiple users or services are accessing the network simultaneously.
At a structural level, NIC teaming works by creating a logical interface that represents multiple physical NICs. This logical interface is what the operating system interacts with. Each physical NIC remains active in the background, but they are coordinated as part of a unified system. This abstraction simplifies network management because administrators can configure and manage one interface instead of multiple separate ones.
The concept of abstraction is important in understanding why NIC teaming is so widely used. In complex IT environments, simplicity in configuration reduces the chances of errors. Managing multiple network interfaces individually would increase administrative workload and the risk of misconfiguration. By grouping them together, administrators gain a cleaner and more manageable networking model.
Different operating systems implement NIC teaming in different ways, but the underlying concept remains consistent. The system creates a logical interface, assigns it an IP address, and then binds multiple physical interfaces to it. Once this is done, the system determines how to distribute outgoing and incoming traffic based on predefined rules.
These rules are important because not all network traffic behaves the same way. Some applications require continuous high-speed connections, while others generate small bursts of data. The system must decide how to allocate traffic efficiently across available interfaces without disrupting communication patterns.
NIC teaming is also closely related to the concept of redundancy in system design. Redundancy refers to having backup components ready to take over when primary components fail. In networking, redundancy ensures that a single point of failure does not disrupt the entire system. By combining multiple NICs, redundancy is built directly into the network architecture.
In enterprise environments, NIC teaming is especially valuable because downtime can have significant financial and operational consequences. Servers that host applications, databases, or virtual machines must remain accessible at all times. Even a brief interruption in connectivity can lead to service degradation or loss of productivity. NIC teaming reduces this risk by ensuring that alternative communication paths are always available.
Another important aspect of NIC teaming is its role in virtualization. Virtual machines depend heavily on stable network connections because they often host critical workloads. In virtualized environments, multiple virtual machines may share the same physical hardware, increasing network demand. NIC teaming helps distribute this load effectively, ensuring that virtual machines maintain consistent network performance.
While NIC teaming provides clear benefits, it also introduces a level of complexity in network design. Administrators must consider how physical NICs are grouped, how traffic is distributed, and how failover scenarios are handled. These decisions depend on the specific requirements of the environment, including performance needs, hardware capabilities, and network architecture.
Despite this complexity, NIC teaming remains a widely adopted solution because of its flexibility. It can be implemented in small environments with minimal configuration or scaled to large enterprise infrastructures with advanced load balancing strategies. This adaptability makes it suitable for a wide range of use cases.
Understanding NIC teaming at this foundational level is important before moving into more technical aspects such as configuration methods, load balancing techniques, and system-level integration. The concept begins with simple redundancy and performance improvement, but it extends into more advanced networking strategies that support modern computing environments.
Traffic Distribution Methods, Teaming Models, and System-Level Behavior
As NIC teaming becomes part of a network infrastructure, its effectiveness depends heavily on how traffic is distributed across multiple network interfaces. This process is not random. Instead, it is governed by specific methods and algorithms that determine how data flows through the system.
At the core of NIC teaming is the concept of load distribution. Since multiple NICs are combined into a single logical interface, the system must decide how to allocate network traffic among them. This allocation is handled using load balancing techniques, which are designed to optimize performance while maintaining stability.
One of the most common approaches is based on address hashing. In this method, the system uses information from network packets, such as source and destination addresses, to generate a mathematical value known as a hash. This hash determines which NIC will handle a particular stream of traffic. The advantage of this method is consistency, as traffic between the same endpoints tends to follow the same path, reducing packet reordering and improving stability.
Another method involves using transport-level information. Instead of focusing only on IP addresses, this approach considers port numbers associated with communication sessions. By analyzing transport-layer data, the system can distribute traffic more granularly, allowing for more efficient use of available bandwidth. This is especially useful in environments with multiple simultaneous connections.
Some NIC teaming configurations use dynamic balancing strategies. These systems continuously monitor network load and adjust traffic distribution based on real-time conditions. If one NIC becomes heavily utilized, new traffic may be directed to less busy interfaces. This adaptive behavior helps maintain balanced performance even as network conditions change.
In addition to load balancing methods, NIC teaming also relies on different operational models that define how the system interacts with network switches. One common model is switch-independent teaming. In this configuration, the NICs in the team operate without requiring special support from network switches. Each NIC can be connected to a different switch or the same switch, and the system manages traffic distribution internally. This approach offers flexibility and is easier to implement in existing environments.
On the other hand, switch-dependent teaming relies on coordination between the server and the network switch. In this model, the switch is aware that multiple physical connections belong to a single logical group. This allows for more advanced features such as enhanced bandwidth aggregation and improved traffic optimization. However, it requires compatible switch configurations and more careful setup.
A widely used protocol in switch-dependent environments is link aggregation control. This mechanism allows network devices to automatically negotiate and manage bundled connections. By using this protocol, switches and servers can dynamically form and maintain grouped connections, reducing the need for manual configuration and improving reliability.
From an operating system perspective, NIC teaming is implemented as a virtual network interface. This interface acts as the primary communication point for applications and services. The underlying physical NICs remain hidden from direct use, which simplifies network configuration at the system level.
When data is transmitted, the operating system sends it through the logical interface. The teaming driver then determines which physical NIC will handle the data based on the configured load balancing method. This process is transparent to applications, meaning software does not need to be aware of the underlying network structure.
Incoming traffic is handled in a similar way, although the behavior may differ depending on configuration. In some setups, incoming data is distributed across multiple NICs, while in others, a single NIC handles incoming traffic to maintain session consistency.
The behavior of NIC teaming also depends on whether the configuration is active-active or active-passive. In an active-active setup, all NICs participate in handling traffic simultaneously. This maximizes bandwidth usage and improves performance. In contrast, active-passive configurations keep one or more NICs in standby mode. These standby interfaces only become active if a primary NIC fails, prioritizing stability over performance.
Another variation includes load-aware distribution, where the system continuously evaluates the workload of each NIC. Instead of following fixed rules, traffic is adjusted dynamically based on current performance metrics. This ensures that no single interface becomes overloaded while others remain underutilized.
NIC teaming behavior can also be influenced by virtualization environments. In virtualized systems, network traffic may be distributed based on virtual switch configurations. This adds another layer of abstraction, where virtual machines communicate through virtual network interfaces that are themselves mapped to physical NIC teams.
As a result, NIC teaming becomes part of a larger networking hierarchy that includes physical hardware, virtual interfaces, and software-defined networking components. Each layer plays a role in determining how data flows through the system.
Understanding these mechanisms is important because it helps explain why NIC teaming can significantly improve network performance in some environments while requiring careful configuration in others. The effectiveness of the system depends on selecting appropriate load balancing strategies, ensuring compatibility with network infrastructure, and aligning the configuration with workload patterns.
Reliability, Performance Optimization, and Real-World Deployment Considerations
In practical environments, NIC teaming is not just a theoretical networking feature but a critical component of system reliability and performance engineering. Its real value becomes evident when it is deployed in environments where continuous connectivity, predictable performance, and fault tolerance are essential.
One of the most important roles of NIC teaming in real-world systems is ensuring high availability. High availability refers to the ability of a system to remain operational even when components fail. In networking terms, this means maintaining connectivity even when individual network interfaces experience hardware or driver issues.
NIC teaming achieves this by continuously monitoring the health of each physical NIC. If a failure is detected, traffic is automatically redirected to the remaining active interfaces. This failover process is typically instantaneous, meaning users or applications may not even notice the disruption. This capability is especially important in environments that support critical services such as databases, communication platforms, or virtualized infrastructure.
Performance optimization is another key benefit of NIC teaming in production systems. By distributing traffic across multiple NICs, organizations can achieve higher aggregate throughput. This is particularly useful in data-heavy environments where large volumes of information are transmitted continuously. Instead of relying on a single network path, traffic is spread across multiple channels, reducing congestion and improving responsiveness.
However, achieving optimal performance requires careful planning. Not all traffic behaves the same way, and not all load balancing methods are suitable for every scenario. For example, workloads with consistent long-lived connections may benefit from different distribution strategies than workloads with short, bursty traffic patterns. Selecting the appropriate configuration is therefore an important part of system design.
Reliability in NIC teaming is not limited to hardware failure scenarios. It also includes protection against network congestion, misconfiguration, and uneven load distribution. By using multiple interfaces, the system gains flexibility in how it handles traffic fluctuations. This helps maintain stable performance even under unpredictable conditions.
In enterprise deployments, NIC teaming is often integrated into broader infrastructure strategies. It works alongside technologies such as virtualization platforms, storage networks, and distributed application systems. In these environments, network performance is closely tied to overall system performance, making NIC teaming an important architectural component.
Monitoring plays a crucial role in maintaining effective NIC teaming configurations. Administrators must continuously observe network behavior to ensure that load distribution is functioning as expected. Key indicators include bandwidth utilization, packet loss, latency, and interface status. Monitoring these metrics helps identify potential issues before they impact system performance.
Troubleshooting NIC teaming requires a structured approach. When problems occur, the first step is often to verify physical connectivity and hardware status. Faulty cables, damaged ports, or malfunctioning NICs can all disrupt team performance. Once hardware issues are ruled out, attention shifts to configuration settings, driver compatibility, and system logs.
Driver consistency is particularly important in NIC teaming setups. Incompatible or outdated drivers can lead to unpredictable behavior, reduced performance, or even system instability. Ensuring that all NICs use compatible drivers helps maintain consistent operation across the team.
Another important consideration is switch configuration, especially in environments that use switch-dependent teaming. Misaligned switch settings can prevent proper traffic distribution or cause connectivity issues. Ensuring that network switches are correctly configured to support teaming is essential for stable operation.
From a design perspective, NIC teaming works best when combined with well-planned network architecture. This includes choosing appropriate hardware, aligning configurations with workload requirements, and considering future scalability. As network demand grows, the ability to scale bandwidth and maintain redundancy becomes increasingly important.
Best practices in NIC teaming emphasize consistency and documentation. Using similar hardware across team members reduces compatibility issues and simplifies troubleshooting. Maintaining clear documentation of configurations helps administrators understand system behavior and resolve issues more efficiently.
Testing failover scenarios is another critical practice. By simulating network failures, administrators can verify that redundancy mechanisms are functioning correctly. This ensures that the system will behave as expected during real failure events.
Ultimately, NIC teaming represents a balance between performance enhancement and system resilience. When implemented correctly, it provides a stable and scalable networking foundation that supports a wide range of workloads. Its value lies not only in improving speed but also in ensuring that connectivity remains consistent under varying conditions, making it a fundamental component of modern network design.
Enterprise Scaling, and Real-World Engineering of NIC Teaming
As network environments grow in scale and complexity, NIC teaming evolves from a simple redundancy mechanism into a deeper architectural layer of infrastructure design. In large systems, its role is not just about combining network interfaces, but about integrating with operating system internals, virtualization layers, hardware capabilities, and distributed workload patterns. Understanding this deeper layer requires moving beyond surface-level concepts and examining how NIC teaming behaves inside real production ecosystems.
At the core of advanced NIC teaming is the interaction between the operating system kernel and network drivers. When multiple physical interfaces are grouped together, the operating system does not simply “merge” them in a superficial way. Instead, a specialized driver layer manages coordination between NICs, ensuring that traffic distribution, failover logic, and link monitoring are all handled in real time. This driver layer acts as a mediator between hardware and software, continuously making decisions about how packets should be routed.
In modern systems, this process is highly optimized. The kernel maintains internal structures that track the state of each physical interface, including link status, error rates, and throughput levels. These structures are constantly updated, allowing the system to react quickly when conditions change. For example, if a NIC begins dropping packets or losing link stability, the kernel can immediately reduce its traffic load or remove it from active rotation.
One of the most important architectural considerations in NIC teaming is interrupt handling. Every network interface generates hardware interrupts when data arrives or is transmitted. In systems with multiple NICs, interrupt load can become uneven if not properly managed. Advanced configurations distribute interrupts across CPU cores to prevent bottlenecks. This ensures that no single processor becomes overwhelmed while handling network traffic from multiple interfaces.
Closely related to this is the concept of CPU affinity. In high-performance environments, network processing is often tied to specific CPU cores to reduce cache misses and improve efficiency. When NIC teaming is implemented at scale, careful tuning of CPU affinity can significantly improve throughput and reduce latency. This is especially important in systems handling high-frequency trading, large-scale virtualization, or real-time analytics.
Another important architectural factor is memory management. Network packets must be temporarily stored in memory buffers before being processed. In a NIC team, multiple interfaces may generate traffic simultaneously, leading to increased demand for buffer resources. Efficient buffer allocation ensures that packets are not dropped during peak traffic periods. Advanced systems use dynamic buffer scaling to adjust memory usage based on current network load.
Beyond the operating system, NIC teaming also interacts with hardware-level features such as offloading capabilities. Modern network cards are capable of performing certain processing tasks independently of the CPU. These tasks may include checksum calculation, segmentation, or encryption. When multiple NICs are teamed together, these offloading features must be coordinated to ensure consistent behavior across all interfaces. Misalignment in hardware offloading settings can lead to performance inconsistencies or packet processing errors.
In enterprise environments, virtualization adds another layer of complexity. Virtual machines rely on virtual network interfaces that are mapped to physical NIC teams. This abstraction allows multiple virtual systems to share underlying physical resources while maintaining logical separation. However, this also introduces challenges in traffic distribution. The hypervisor must decide how virtual machine traffic is mapped onto physical NICs, and this decision can significantly impact performance.
Some virtualization platforms implement port-based distribution, where each virtual switch port is assigned to a specific NIC within the team. Others use dynamic load balancing based on traffic patterns. The choice of method affects how evenly resources are utilized and how resilient the system is to interface failures. In heavily virtualized environments, NIC teaming becomes part of a larger software-defined networking structure where traffic control is handled at multiple layers.
As infrastructure scales further, NIC teaming must also integrate with distributed systems architecture. Large enterprises often run applications across multiple physical locations or data centers. In these environments, network consistency becomes critical. NIC teaming ensures that each individual server maintains stable connectivity, but higher-level systems must coordinate traffic across entire clusters. This means NIC teaming becomes one component of a much larger reliability strategy.
One of the more advanced aspects of NIC teaming in large environments is failure domain management. A failure domain refers to the scope of impact when a component fails. If all NICs in a team are connected to the same switch or physical network path, the failure domain remains small. However, if NICs are distributed across different switches or network paths, the system gains higher resilience. Designing NIC teams with failure domains in mind is a key part of enterprise architecture planning.
Another important consideration is latency sensitivity. Not all network traffic behaves the same way. Some applications require extremely low latency, while others prioritize throughput. NIC teaming must be configured to respect these differences. In latency-sensitive environments, load balancing algorithms are often designed to minimize packet reordering and maintain consistent connection paths. This ensures that time-critical applications remain stable even under heavy load.
Security also plays a subtle but important role in NIC teaming design. While teaming itself is not a security feature, its configuration can influence the attack surface of a system. For example, misconfigured failover behavior could expose unintended network paths. Additionally, traffic distribution patterns may affect how easily network monitoring tools can detect anomalies. In secure environments, NIC teaming configurations are often reviewed as part of broader network security assessments.
Advanced deployments also consider the impact of microbursts in network traffic. Microbursts are short spikes in traffic that can overwhelm network buffers even if average utilization remains low. NIC teaming helps mitigate this by distributing traffic across multiple interfaces, but it must be carefully tuned. If load balancing is not responsive enough, microbursts may still cause packet loss on individual NICs. This is why real-time monitoring and adaptive balancing are important in high-performance systems.
Another layer of complexity arises from multi-queue networking. Modern NICs support multiple transmit and receive queues, allowing parallel processing of network traffic. When NICs are teamed, each interface may have multiple queues operating simultaneously. The system must coordinate these queues to ensure balanced utilization. Poor queue distribution can lead to CPU imbalance and reduced performance.
In high-performance computing environments, NIC teaming is sometimes combined with specialized networking technologies such as remote direct memory access. These technologies allow data to be transferred directly between system memory and network hardware without involving the CPU. When integrated with NIC teaming, this can significantly reduce latency and improve throughput. However, it also requires precise configuration to ensure consistency across all interfaces in the team.
Scalability is another critical dimension. As systems grow, the number of NICs in a team may increase, but adding more interfaces does not always result in linear performance gains. At a certain point, bottlenecks may shift from network hardware to CPU processing, memory bandwidth, or software overhead. Understanding these limits is essential when designing large-scale NIC teaming configurations.
Operational monitoring in such environments becomes increasingly sophisticated. Instead of simply tracking whether interfaces are up or down, administrators must analyze detailed performance metrics across all NICs in the team. This includes per-interface latency, queue depth, packet distribution patterns, and error rates. These metrics help identify subtle inefficiencies that may not be visible through basic monitoring tools.
Troubleshooting in advanced NIC teaming setups often requires examining multiple layers of the system simultaneously. A performance issue may originate from hardware imbalance, driver behavior, switch configuration, or even application-level traffic patterns. Because of this, diagnostics must consider the entire network stack rather than focusing on a single component.
One common challenge in large deployments is uneven traffic distribution. Even when load balancing is enabled, certain NICs may receive more traffic than others due to hashing algorithms or connection patterns. This can lead to performance asymmetry, where some interfaces are heavily utilized while others remain underused. Addressing this requires careful tuning of balancing strategies and sometimes redesigning traffic flow assumptions.
Another subtle issue is packet reordering. When traffic is distributed across multiple NICs, packets belonging to the same communication stream may arrive out of order. While modern systems are designed to handle this, excessive reordering can impact application performance. This is why certain load balancing methods prioritize session consistency over maximum distribution.
Energy efficiency is also becoming a consideration in modern NIC teaming designs. In some systems, unused NICs can be placed into low-power states during periods of low network activity. This reduces overall power consumption while still maintaining redundancy. However, transitioning between power states must be carefully managed to avoid introducing latency during failover events.
In cloud-scale infrastructure, NIC teaming is often abstracted away from direct system management. Instead, it is integrated into automated provisioning systems that configure network interfaces dynamically based on workload requirements. This allows infrastructure to scale elastically without manual intervention. Even though administrators may not interact directly with NIC teams in these environments, the underlying principles remain the same.
Over time, NIC teaming has evolved from a simple redundancy mechanism into a foundational element of modern networking design. Its role now spans performance optimization, fault tolerance, virtualization support, and large-scale infrastructure coordination. As systems continue to grow in complexity, NIC teaming remains a critical component in ensuring that network communication remains stable, efficient, and adaptable under changing conditions.
Real-Time Optimization, and the Future of NIC Teaming in Modern Networks
As networking environments continue to evolve toward higher speeds, distributed systems, and software-defined infrastructure, NIC teaming has moved far beyond its original role as a simple redundancy technique. In modern enterprise and cloud architectures, it functions as part of a larger orchestration system that includes virtualization layers, automated traffic engineering, and intelligent workload distribution. Understanding NIC teaming at this stage requires looking at it not just as a configuration feature, but as an adaptive system that interacts continuously with hardware, software, and application behavior.
One of the most important developments in modern NIC teaming is the shift toward real-time adaptability. Traditional implementations relied on relatively static load balancing rules. Once configured, traffic distribution would remain consistent unless manually adjusted. However, modern environments demand much more flexibility. Network conditions can change rapidly due to workload spikes, virtual machine migrations, container scaling events, or external traffic fluctuations. In response, NIC teaming mechanisms have become more dynamic, capable of adjusting behavior in near real time.
At the core of this adaptability is continuous telemetry. Modern network interfaces generate detailed performance data that is constantly fed into the operating system or networking stack. This includes metrics such as packet throughput, error rates, queue depth, latency variation, and interface utilization. Instead of treating NICs as passive hardware components, the system actively evaluates their performance and adjusts traffic distribution accordingly.
This creates a feedback loop where NIC teaming behavior is influenced by live system conditions. If one interface begins to show signs of congestion, the system can gradually shift traffic away from it. If another interface becomes underutilized, it can be assigned more traffic. This dynamic balancing helps maintain consistent performance even in unpredictable environments.
Another major advancement is the integration of NIC teaming with software-defined networking principles. In traditional networking models, physical hardware defined most of the network behavior. In contrast, software-defined environments abstract network control into programmable layers. NIC teaming in these systems is no longer just a local server configuration but part of a centrally managed policy framework.
In such environments, traffic routing decisions may be influenced by global network policies rather than local device settings. For example, workloads might be assigned to specific NIC teams based on application priority, security classification, or geographic location. This allows organizations to treat network resources as flexible pools rather than fixed hardware allocations.
Closely related to this is the concept of policy-based traffic engineering. Instead of manually selecting load balancing algorithms for each NIC team, administrators define high-level policies that describe desired outcomes. These policies might prioritize low latency, maximum throughput, or balanced utilization. The underlying system then determines how to distribute traffic across NICs to achieve those goals. This abstraction reduces complexity while improving consistency across large-scale deployments.
As network speeds continue to increase, especially with the adoption of multi-gigabit and high-throughput interfaces, NIC teaming faces new challenges. One of the most significant is ensuring that the software layer can keep up with hardware capabilities. While modern NICs are capable of extremely high data rates, inefficient software handling can create bottlenecks that limit overall performance.
To address this, many systems rely on hardware offloading and parallel processing techniques. Network processing tasks are distributed across multiple CPU cores, and in some cases, delegated entirely to NIC hardware. When combined with NIC teaming, this allows multiple interfaces to operate at high efficiency without overwhelming system resources.
Another important aspect of modern NIC teaming is its interaction with containerized environments. Containers introduce a lightweight form of virtualization where multiple isolated applications share the same operating system kernel. In such environments, network traffic is often managed through virtual network interfaces that sit on top of physical NIC teams.
This layered architecture means that traffic may pass through several abstraction layers before reaching physical hardware. A single packet might originate in a container, pass through a virtual bridge, be processed by a software-defined network layer, and finally be distributed across a NIC team. Each layer adds flexibility but also introduces complexity in terms of performance optimization.
To manage this complexity, modern systems use hierarchical traffic control mechanisms. These mechanisms ensure that decisions about traffic distribution are coordinated across different layers of the networking stack. For example, a container orchestration system might decide which physical node handles a workload, while the NIC teaming layer determines how that node’s network interfaces handle the traffic.
Another emerging trend is the increasing importance of latency consistency. While traditional networking focused heavily on maximizing throughput, modern applications such as real-time analytics, financial trading, and interactive cloud services are more sensitive to latency variations. NIC teaming configurations must therefore be optimized not only for speed but also for predictable response times.
This has led to the development of more sophisticated load balancing strategies that prioritize flow stability. Instead of constantly shifting traffic between interfaces, these strategies aim to maintain consistent paths for specific data flows. This reduces jitter and improves the predictability of network performance, which is critical for latency-sensitive workloads.
At the same time, systems must still maintain flexibility for failover scenarios. If a NIC fails or becomes unstable, traffic must be quickly redistributed without disrupting ongoing connections. This requires careful balancing between stability and responsiveness. Too much stability can delay failover, while too much responsiveness can introduce unnecessary traffic shifts.
Another key area of advancement is predictive network management. Instead of reacting to network conditions after they occur, modern systems attempt to anticipate changes based on historical patterns and real-time analytics. For example, if a system detects that network usage typically spikes at certain times, it can preemptively adjust NIC teaming behavior to prepare for increased load.
This predictive approach extends to failure detection as well. Rather than waiting for a NIC to fully fail, systems can identify early warning signs such as increasing error rates or subtle latency increases. Traffic can then be gradually shifted away from the affected interface before a complete failure occurs, improving overall system resilience.
Energy efficiency is also becoming an increasingly important consideration in NIC teaming design. In large-scale data centers, thousands of network interfaces may be active simultaneously. Optimizing how these interfaces are used can lead to significant reductions in power consumption. Some systems now incorporate power-aware networking strategies, where unused NICs can be placed into low-power states during periods of low demand.
However, this introduces a trade-off between energy savings and responsiveness. Waking a NIC from a low-power state takes time, which can impact failover speed. As a result, systems must carefully balance energy efficiency against performance requirements, often dynamically adjusting based on workload intensity.
Security considerations are also evolving alongside NIC teaming technology. While teaming itself is not inherently a security mechanism, its configuration can influence how traffic flows through a system. In modern environments, network segmentation is often combined with NIC teaming to isolate different types of traffic. For example, management traffic, application traffic, and storage traffic may be routed through separate NIC teams to improve both security and performance isolation.
In some cases, encryption processing is also integrated into the network stack. When traffic is distributed across multiple NICs, encryption workloads must be handled consistently to avoid performance degradation. This requires coordination between NIC hardware capabilities and software encryption engines.
Another area of development is resilience against partial failures. In traditional systems, NIC failure is often treated as a binary event—either a NIC is fully operational or it is not. However, in real-world environments, partial degradation is common. A NIC might still function but operate at reduced capacity or increased error rates. Modern NIC teaming systems are increasingly capable of detecting and responding to these partial failures by gradually reducing traffic allocation rather than immediately removing the interface from service.
This granular approach to failure handling improves overall system stability and reduces the likelihood of sudden performance drops. It also allows for more graceful degradation in situations where hardware is beginning to fail but has not completely stopped functioning.
As networking continues to evolve, NIC teaming is also being influenced by emerging technologies such as artificial intelligence-driven network management. These systems analyze large volumes of network telemetry data to identify patterns and optimize traffic distribution automatically. Over time, they can learn which configurations perform best under specific conditions and adjust NIC teaming behavior accordingly.
This represents a shift from manually configured networking toward autonomous network management. Instead of administrators defining all parameters, systems increasingly make decisions based on learned behavior and real-time analysis. NIC teaming becomes one component of a self-optimizing network ecosystem.
Despite these advancements, the fundamental principles of NIC teaming remain consistent. The core goals—performance improvement, redundancy, and efficient resource utilization—continue to guide its design and implementation. What has changed is the level of intelligence, automation, and integration with broader system architectures.
Looking forward, NIC teaming is likely to become even more deeply integrated into infrastructure automation systems. As networks continue to scale and workloads become more dynamic, static configuration models will become less practical. Instead, NIC teaming will function as part of a continuously adapting system that responds to application demands, hardware conditions, and environmental changes in real time.
This evolution reflects a broader trend in computing infrastructure: the shift from manually managed systems to adaptive, self-optimizing environments. In this context, NIC teaming is no longer just a networking technique but a foundational element of intelligent infrastructure design, ensuring that data flows efficiently, reliably, and predictably across increasingly complex digital ecosystems.
Building on this trajectory, one of the most important practical implications is how NIC teaming influences long-term infrastructure planning. Network architects are increasingly required to design systems that do not just perform well under current workloads, but can also adapt to future changes without requiring complete redesigns. NIC teaming supports this goal by providing a flexible abstraction layer that can scale horizontally simply by adding more interfaces to a team, rather than replacing entire network architectures.
Another subtle but important aspect is operational continuity during upgrades. In enterprise environments, network hardware and drivers must be updated regularly. NIC teaming allows these updates to be performed in a staggered manner, where individual interfaces can be taken offline, updated, and brought back into the team without disrupting overall connectivity. This reduces maintenance windows and minimizes service interruptions, which is critical in always-on systems.
Finally, as edge computing becomes more widespread, NIC teaming is also finding new relevance outside traditional data centers. Edge devices often operate in constrained environments where reliability is essential but physical redundancy is limited. In such cases, even small-scale NIC teaming configurations can significantly improve resilience and performance, ensuring stable connectivity for distributed applications closer to end users.
Conclusion
NIC teaming has evolved into a foundational networking strategy that plays a critical role in modern IT infrastructure. At its core, it addresses two essential requirements of enterprise systems: performance and reliability. By combining multiple network interface cards into a single logical unit, organizations gain increased bandwidth, improved fault tolerance, and more efficient traffic distribution. This makes it especially valuable in environments where continuous connectivity is essential and downtime is not acceptable.
Beyond its basic function, NIC teaming has become deeply integrated into advanced computing environments, including virtualization platforms, cloud systems, and software-defined networks. It supports complex workloads by ensuring that network traffic is distributed intelligently across available resources. At the same time, it provides resilience by automatically rerouting traffic when hardware failures occur, reducing the impact of unexpected disruptions.
As systems scale, NIC teaming also contributes to operational flexibility. It allows administrators to adapt network configurations without redesigning entire infrastructures, making it easier to respond to changing performance demands. In combination with modern monitoring and automation tools, it becomes part of a broader ecosystem of adaptive network management.
Looking forward, NIC teaming will continue to evolve alongside emerging technologies such as artificial intelligence-driven optimization and edge computing. Its role will expand further as networks become more distributed and dynamic. Despite these advancements, the fundamental principles remain the same: ensuring stable connectivity, maximizing resource utilization, and maintaining consistent performance under varying conditions.