The modern technology landscape is increasingly driven by data. Every application, business process, and digital service produces vast amounts of information that must be stored, processed, analyzed, and transformed into meaningful insights. Because of this shift, professionals in IT are no longer judged only by their ability to manage infrastructure or write code. They are also expected to understand how data flows through complex systems, how it can be optimized, and how organizations can extract value from it.
Cloud computing has become the foundation for this transformation. Instead of relying on traditional on-premises systems, organizations now use cloud platforms to scale data operations efficiently. This shift has created a strong demand for professionals who understand cloud-based data engineering, analytics workflows, and distributed computing systems. As a result, certifications that validate these skills have become an important part of career development in IT.
Within this landscape, big data expertise stands out as one of the most valuable capabilities. Businesses are no longer dealing with small, structured datasets. Instead, they are processing streaming data from IoT devices, unstructured text from social platforms, transaction logs, multimedia content, and real-time analytics pipelines. Handling this level of complexity requires both theoretical understanding and practical skills.
Cloud-based big data roles often involve designing systems that can ingest large volumes of data, store it efficiently, and analyze it in real time or near real time. This includes working with distributed storage systems, data lakes, data warehouses, and serverless analytics tools. Professionals who can manage these systems are highly sought after because they directly contribute to business intelligence, customer insights, fraud detection, and operational optimization.
Because of this demand, structured validation of skills has become essential. Employers want assurance that candidates are not only familiar with concepts but also capable of working with real-world cloud data environments. This is where cloud-focused certifications in big data become relevant, especially those associated with major cloud providers. These certifications help standardize expectations and ensure that professionals meet a consistent level of expertise.
Beyond employability, there is also a practical motivation. Working with cloud data systems requires familiarity with a wide range of services and architectures. Without structured learning, it is easy to develop gaps in understanding, especially when dealing with distributed processing frameworks or large-scale data storage systems. A certification path provides direction and structure, making it easier to navigate the complexity of the field.
The AWS ecosystem, in particular, has become a major player in this space due to its extensive suite of data-related services. These include tools for data ingestion, transformation, storage, visualization, and machine learning integration. As organizations increasingly rely on AWS for their data infrastructure, professionals who understand how to operate within this ecosystem gain a strong competitive advantage.
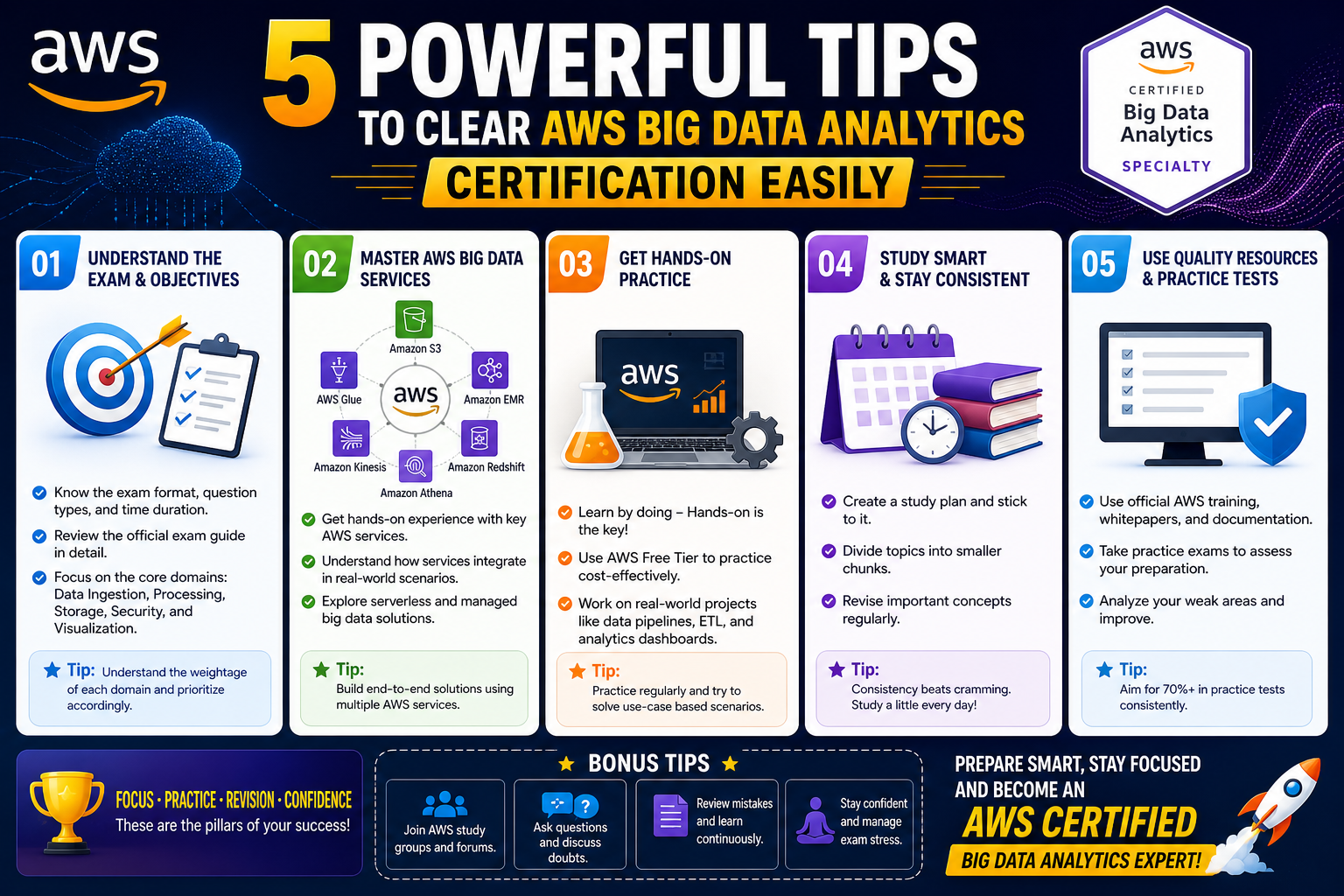
Understanding the AWS Big Data Certification and Its Purpose
The AWS Big Data certification is designed to evaluate a candidate’s ability to work with data analytics solutions on cloud infrastructure. It focuses on practical knowledge of designing, building, securing, and maintaining big data solutions using cloud services. Rather than testing memorization, it emphasizes applied understanding and problem-solving in real-world scenarios.
At its core, this certification is intended for professionals who already have experience working with data systems and want to validate their ability to use cloud-native tools effectively. It assumes familiarity with basic cloud computing concepts and builds on that foundation to explore more advanced topics in data engineering and analytics.
One of the key aspects of this certification is its focus on end-to-end data workflows. Candidates are expected to understand how data is collected from different sources, how it is ingested into cloud systems, how it is processed using distributed frameworks, and how it is eventually used for analytics or reporting. This requires a holistic understanding of data pipelines rather than isolated knowledge of individual services.
Another important aspect is performance optimization. Cloud data systems must be designed to handle scale efficiently, which involves selecting the right storage formats, optimizing query performance, and managing resource allocation effectively. The certification evaluates how well candidates can make these decisions under different constraints.
Security and governance also play a critical role. Data in cloud environments must be protected from unauthorized access, and compliance requirements must be met. This includes understanding identity management, encryption, access control policies, and auditing mechanisms. A strong understanding of these concepts is necessary for anyone working with enterprise-level data systems.
The certification also emphasizes real-time data processing. Many modern applications require immediate insights rather than batch processing. This includes monitoring systems, fraud detection engines, and live analytics dashboards. Candidates must understand how streaming data systems operate and how they integrate with other cloud services.
Overall, the certification is not just about knowing individual tools but about understanding how those tools work together in a unified architecture. This systems-level thinking is what makes it valuable in professional environments.
Core Knowledge Areas You Need Before You Start Preparing
Before beginning structured preparation, it is important to understand the foundational areas that form the backbone of cloud-based big data systems. Without this baseline knowledge, advanced topics can feel overwhelming and disconnected.
One of the primary areas is distributed computing. Unlike traditional computing systems, distributed systems split workloads across multiple machines. This allows for greater scalability and fault tolerance but also introduces complexity in coordination and data consistency. Understanding how distributed systems operate is essential for working with big data tools.
Another key area is data storage architecture. Cloud environments typically use a combination of object storage, data lakes, and data warehouses. Each serves a different purpose. Object storage is used for raw data, data lakes provide flexible storage for structured and unstructured data, and data warehouses are optimized for analytical queries. Understanding when and how to use each type is critical.
Data processing frameworks are also central to big data systems. These frameworks allow large datasets to be processed in parallel across multiple nodes. They are designed to handle both batch and streaming workloads. Knowing how these frameworks operate helps in designing efficient data pipelines.
Data modeling is another important concept. Even in large-scale systems, data must be organized in a way that supports efficient querying and analysis. Poor data modeling can lead to slow performance and increased costs. Understanding normalization, denormalization, and schema design principles is essential.
Networking and security fundamentals also play a significant role. Cloud data systems rely heavily on secure communication between services. This includes virtual networks, subnet configurations, and access control policies. Without a clear understanding of these concepts, it becomes difficult to design secure and scalable systems.
Monitoring and troubleshooting are equally important. In production environments, systems must be continuously monitored for performance issues, failures, and bottlenecks. Professionals must understand how to interpret logs, set up alerts, and diagnose system behavior.
These foundational areas form the building blocks of more advanced cloud data concepts. Without them, it becomes difficult to fully understand how different services interact within a larger architecture.
Building the Right Mindset for Certification Success
Approaching a complex certification requires more than just technical knowledge. It also requires the right mindset. Many learners underestimate the depth of understanding required and approach preparation as a short-term memorization task. This often leads to difficulty when faced with scenario-based questions that test applied knowledge.
A more effective approach is to think of preparation as skill-building rather than exam preparation. The goal is not only to pass an assessment but to develop the ability to design and manage real-world data systems. This shift in perspective changes how information is absorbed and retained.
Consistency is another important factor. Big data systems involve many interconnected concepts, and trying to learn everything at once can lead to cognitive overload. A steady, structured approach allows the brain to gradually build connections between different topics.
Curiosity also plays a major role. Instead of memorizing how a system works, it is more effective to understand why it is designed that way. This deeper level of understanding makes it easier to adapt knowledge to unfamiliar scenarios.
Another important mindset shift is acceptance of complexity. Cloud data systems are inherently complex, and it is normal not to understand everything immediately. Progress often comes through repeated exposure and hands-on experience rather than instant comprehension.
Patience with the learning process is essential. Many concepts only become clear after working with them in practice. This is why theoretical study alone is not sufficient. Real understanding comes from combining theory with experimentation.
Structuring Your Preparation Strategy Effectively
A well-structured preparation approach can make a significant difference in how efficiently knowledge is absorbed. Without structure, it is easy to jump between topics randomly, which leads to fragmented understanding.
One effective approach is to divide preparation into thematic areas. Instead of studying services individually, it is more useful to group them based on function. For example, data ingestion, storage, processing, and visualization can be treated as separate learning modules. This helps build a clearer mental model of how systems operate end-to-end.
Another important aspect is sequencing. Some topics naturally build on others. For instance, understanding storage systems should come before optimizing query performance. Similarly, knowledge of data pipelines should precede advanced analytics workflows.
Time management also plays a key role. Long, uninterrupted study sessions often lead to diminishing returns. Shorter, focused sessions tend to be more effective for retaining complex information. This allows the brain to process and consolidate knowledge more efficiently.
Active learning techniques are also important. Instead of passively reading material, it is more effective to engage with it by taking notes, drawing diagrams, and mentally simulating data flows. This reinforces understanding and improves recall.
Repetition is another critical factor. Complex systems require multiple exposures before they are fully understood. Revisiting topics at regular intervals helps strengthen long-term memory and reduces the likelihood of forgetting important details.
Gathering Reliable Study Materials Without Overload
One of the challenges in preparing for a cloud-based certification is the sheer volume of available information. There are documentation pages, tutorials, articles, and community discussions covering almost every topic. While this abundance is useful, it can also become overwhelming if not managed properly.
A more effective approach is to focus on a limited set of high-quality sources. Official documentation is often the most reliable starting point because it reflects the most accurate and up-to-date information about services and their behavior.
However, documentation alone is not always sufficient for understanding practical use cases. Supplementing it with conceptual explanations and real-world examples helps bridge the gap between theory and application.
It is also important to avoid constantly switching between sources. This can fragment understanding and make it difficult to build a coherent mental model. Sticking to a consistent set of materials allows for deeper learning.
Organizing information is equally important. Without structure, notes and references can quickly become scattered and difficult to revisit. Creating a personal system for categorizing topics helps maintain clarity throughout the preparation process.
At this stage, the focus should remain on building foundational understanding rather than attempting to cover every possible detail. Depth is more important than breadth when starting out.
Developing Strong Foundations in Cloud Data Services
Cloud data ecosystems consist of multiple interconnected services that work together to form complete data pipelines. Understanding how these services interact is essential for building effective solutions.
Data storage services are responsible for holding large volumes of structured and unstructured data. They are designed to scale automatically and handle diverse data formats. Knowing how to choose appropriate storage solutions based on workload requirements is a key skill.
Processing services handle the transformation and analysis of data. These systems are designed to distribute workloads across multiple nodes, enabling efficient handling of large datasets. Understanding how these systems manage parallel execution is important for optimizing performance.
Analytics and visualization tools allow users to extract insights from processed data. These tools often integrate directly with storage and processing systems, enabling seamless data exploration. Understanding how queries are executed and optimized is part of this knowledge area.
Data ingestion services are responsible for moving data into cloud systems. This can include real-time streaming data or scheduled batch transfers. Knowing how data flows from source to destination is critical for designing efficient pipelines.
Security services ensure that data is protected throughout its lifecycle. This includes access control, encryption, and auditing mechanisms. Understanding how to secure data pipelines is essential for enterprise environments.
Common Challenges Learners Face at the Beginning
Many learners encounter difficulties when first approaching cloud-based big data concepts. One common challenge is the overwhelming number of services and tools available. Without a clear framework, it can be difficult to understand how everything fits together.
Another challenge is abstract thinking. Big data systems often operate at a scale that is difficult to visualize. Understanding distributed processing or parallel execution requires a shift in thinking compared to traditional computing models.
Lack of hands-on experience can also create barriers. Theoretical knowledge alone is often insufficient for understanding how systems behave in practice. Without experimentation, concepts may remain abstract and difficult to apply.
Time management is another difficulty. Many learners struggle to balance study with other responsibilities, leading to inconsistent progress. Without a structured approach, it becomes easy to lose momentum.
Finally, information overload is a frequent issue. With so many resources available, it can be difficult to determine what is essential and what is secondary. This can lead to confusion and inefficient study patterns.
Creating a Practical Learning Environment in Cloud Systems
Hands-on experience plays a crucial role in understanding cloud data systems. Working directly with services allows learners to observe how theoretical concepts behave in real environments.
Setting up small-scale projects is an effective way to gain this experience. These projects do not need to be complex. Even simple data pipelines can provide valuable insights into how systems interact.
Experimentation is also important. Testing different configurations and observing their impact helps build intuition about system behavior. This kind of learning is difficult to achieve through reading alone.
Another important aspect is problem-solving. Encountering and resolving errors helps deepen understanding of system mechanics. It also builds confidence in working with unfamiliar scenarios.
Over time, practical experience helps transform abstract concepts into concrete knowledge. This makes it easier to understand advanced topics and apply them in real-world situations.
First Steps Toward Effective Practice and Assessment
As foundational knowledge begins to take shape, the next step involves evaluating understanding through structured practice. This is not about testing performance but about identifying areas that require further attention.
Practice scenarios help simulate real-world conditions where multiple concepts must be applied simultaneously. These exercises reveal gaps in understanding that may not be obvious during passive study.
Reviewing mistakes is particularly important. Errors often highlight misunderstandings or overlooked details. Analyzing these mistakes helps refine knowledge and improve accuracy.
Repeated exposure to scenario-based problems helps develop familiarity with question patterns and logical reasoning required in complex environments.
Strengthening Cloud Data Foundations Through Applied Understanding
As preparation for a cloud-focused big data certification progresses beyond the introductory stage, the focus naturally shifts from basic awareness to applied understanding. At this point, learners are expected to connect individual services and concepts into coherent systems rather than viewing them in isolation. This is where real comprehension begins to form, because cloud data environments are not built from standalone components but from tightly integrated architectures that work together to process information at scale.
In practical cloud environments, data rarely follows a simple or linear path. Instead, it moves through multiple layers of ingestion, transformation, storage, and analysis. Each layer has its own set of tools and design considerations. Understanding how these layers interact is essential for building efficient and scalable solutions. Without this systems-level perspective, even strong theoretical knowledge can feel fragmented.
One of the most important aspects of applied understanding is recognizing how data behavior changes depending on volume and velocity. Small datasets can be processed using straightforward methods, but large-scale systems require distributed computing strategies. Similarly, real-time data introduces challenges that do not exist in batch processing environments. These differences shape how architectures are designed and optimized.
At this stage, learners begin to appreciate that cloud data engineering is not just about knowing services but about making design decisions. Every choice has trade-offs related to performance, cost, scalability, and reliability. Understanding these trade-offs is what separates surface-level familiarity from professional-level expertise.
Deep Dive into Data Ingestion Architectures
Data ingestion is the first major stage in any cloud data pipeline. It refers to the process of collecting data from various sources and bringing it into a cloud environment for further processing. While this may sound simple, in practice it involves handling diverse data formats, varying data speeds, and different reliability requirements.
In modern systems, data can come from applications, sensors, user interactions, logs, external APIs, and third-party systems. Each source behaves differently. Some generate continuous streams of data, while others produce periodic batches. Designing an ingestion system requires understanding these differences and selecting appropriate methods for handling them.
Batch ingestion is typically used when data does not need to be processed immediately. It involves collecting data over a period of time and then transferring it in bulk. This approach is efficient for large, structured datasets but may not be suitable for time-sensitive applications.
Streaming ingestion, on the other hand, handles data in real time. This is essential for applications such as monitoring systems, fraud detection, and live analytics. Streaming systems must be designed to handle continuous input without overwhelming downstream components.
A key challenge in ingestion design is ensuring reliability. Data must be captured accurately even in the presence of network failures or system interruptions. This often requires buffering mechanisms, retry strategies, and fault-tolerant architectures.
Another important consideration is scalability. As data volume increases, ingestion systems must be able to scale without degradation in performance. This often involves distributed ingestion services that can handle parallel data streams.
Understanding ingestion is critical because it sets the foundation for everything that follows in the pipeline. If data is not ingested correctly, downstream processes will produce inaccurate or incomplete results.
Evolving Understanding of Data Storage Systems
Once data is ingested, it must be stored in a way that supports future processing and analysis. Cloud storage systems are designed to handle massive volumes of data while maintaining accessibility and durability. However, not all storage systems are designed for the same purpose.
Object storage is one of the most commonly used storage models in cloud environments. It is designed for storing unstructured data such as images, logs, backups, and raw datasets. Its scalability makes it ideal for big data applications where large volumes of information must be retained over long periods.
Data lakes are built on top of object storage systems and provide a flexible environment for storing both structured and unstructured data. They allow organizations to store raw data without requiring immediate transformation. This flexibility is particularly useful in analytics workflows where data may be processed in different ways depending on the use case.
Data warehouses, in contrast, are optimized for structured data and analytical queries. They organize data into schemas that support fast querying and reporting. Unlike data lakes, they typically require data to be cleaned and transformed before storage.
Understanding when to use each storage model is an important skill. Choosing the wrong storage system can lead to performance issues, increased costs, or unnecessary complexity. For example, using a data warehouse for raw unstructured data would be inefficient, while using a data lake for highly structured reporting could slow down query performance.
Another important concept in storage systems is data partitioning. Partitioning involves dividing large datasets into smaller, more manageable segments. This improves query performance by reducing the amount of data that must be scanned during processing.
Compression and storage formats also play a significant role. Efficient storage formats reduce storage costs and improve processing speed. Understanding how different formats affect performance is part of advanced data engineering knowledge.
Understanding Distributed Processing at Scale
Distributed processing is one of the core concepts in cloud-based big data systems. It allows large datasets to be processed across multiple machines simultaneously. This approach is essential for handling workloads that exceed the capacity of a single system.
In a distributed environment, tasks are divided into smaller units and assigned to different nodes. These nodes process data in parallel and then combine results. This significantly reduces processing time and enables systems to scale horizontally.
However, distributed processing introduces complexity. Coordination between nodes must be managed carefully to ensure consistency and accuracy. Data must be partitioned in a way that balances workload evenly across the system.
Fault tolerance is another important aspect. In large distributed systems, node failures are common. Systems must be designed to continue functioning even when individual components fail. This is achieved through redundancy and task re-execution mechanisms.
Another challenge is data locality. Moving large amounts of data across networks can be expensive and slow. Efficient systems aim to process data close to where it is stored, minimizing data movement.
Understanding distributed processing is essential for working with modern big data frameworks. It provides the foundation for scaling analytics workloads and handling complex data transformations.
Real-Time Data Processing and Streaming Systems
Real-time data processing has become increasingly important in modern applications. Unlike batch processing, which works on historical data, real-time systems process information as it is generated. This enables immediate insights and faster decision-making.
Streaming systems are designed to handle continuous flows of data. These systems must be able to process, analyze, and store data without delays. This requires efficient buffering, low-latency processing, and scalable architectures.
One of the key challenges in streaming systems is maintaining consistency. Since data arrives continuously, systems must ensure that processing does not miss or duplicate events. This often involves event tracking and state management techniques.
Another challenge is handling varying data speeds. Some streams may produce data at a constant rate, while others may experience spikes. Systems must be able to adapt to these fluctuations without performance degradation.
Streaming systems are commonly used in applications such as fraud detection, real-time monitoring, and personalized recommendations. These use cases require immediate responses based on incoming data.
Understanding streaming architectures is essential for designing modern data pipelines that support real-time analytics.
Exploring Data Transformation and ETL Workflows
Data transformation is a critical step in preparing raw data for analysis. It involves cleaning, structuring, and enriching data so that it can be used effectively in downstream applications. This process is often referred to as ETL, which stands for extract, transform, and load.
The extraction phase involves collecting data from multiple sources. This data is often inconsistent and may contain errors or missing values. The transformation phase addresses these issues by cleaning and standardizing the data. The loading phase involves storing the processed data in a target system.
Transformation can include tasks such as filtering irrelevant data, converting data types, aggregating information, and joining datasets. These operations ensure that the final dataset is suitable for analysis.
One of the challenges in ETL workflows is managing large-scale transformations efficiently. As data volume increases, processing time can become a bottleneck. Distributed processing systems are often used to handle these workloads.
Another challenge is maintaining data quality. Errors in transformation logic can lead to incorrect insights. This makes testing and validation an important part of ETL design.
Modern cloud environments often use automated ETL pipelines that integrate with other data services. These pipelines allow data to flow continuously from ingestion to analysis.
Understanding Query Optimization and Analytical Performance
Once data is stored and transformed, it must be queried efficiently to extract insights. Query optimization plays a key role in ensuring that analytical systems perform well under heavy workloads.
In large datasets, poorly optimized queries can lead to slow performance and high resource usage. Understanding how queries are executed helps in designing more efficient systems.
One important concept is indexing. Indexes allow systems to quickly locate relevant data without scanning entire datasets. Proper indexing can significantly improve query performance.
Another important factor is data partitioning. By dividing data into smaller segments, systems can reduce the amount of data scanned during queries.
Caching is also used to improve performance. Frequently accessed data can be stored in memory to reduce retrieval time.
Understanding query execution plans helps identify bottlenecks in analytical systems. These plans show how queries are processed and where optimizations can be applied.
Managing Security and Access Control in Cloud Data Systems
Security is a fundamental aspect of cloud data systems. As data moves through different stages of processing, it must be protected from unauthorized access and potential breaches.
Access control mechanisms determine who can view or modify data. These mechanisms are based on roles and permissions, ensuring that only authorized users can access sensitive information.
Encryption is another important security measure. Data can be encrypted both at rest and in transit, ensuring that it remains protected even if intercepted.
Auditing systems track data access and modifications. This helps organizations maintain compliance and detect suspicious activity.
Understanding security principles is essential for designing trustworthy data systems in enterprise environments.
Developing Analytical Thinking for Complex Data Scenarios
Beyond technical knowledge, analytical thinking plays a key role in mastering cloud data systems. This involves understanding how different components interact and how changes in one part of the system affect the whole.
Analytical thinking requires the ability to break down complex problems into smaller parts. It also involves identifying patterns in data and understanding relationships between variables.
This type of thinking is essential when designing data pipelines, optimizing performance, or troubleshooting issues.
Over time, analytical thinking becomes a natural part of working with data systems, allowing professionals to make more informed decisions.
Advancing Toward Integrated System Understanding
As learners progress further, individual concepts begin to merge into a unified understanding of cloud data architecture. At this stage, the focus shifts from isolated knowledge to integrated system design.
Understanding how ingestion, storage, processing, transformation, and analytics work together is essential for building complete solutions. Each component plays a role in the overall system, and changes in one area can impact others.
This integrated perspective is what defines advanced expertise in cloud data engineering.
Mastering End-to-End Cloud Data Architecture Thinking
At the advanced stage of preparation for a cloud big data certification, the focus naturally shifts away from learning individual services and toward understanding how entire systems operate as unified architectures. This is where learners begin to think less like tool users and more like system designers. The goal is no longer just knowing what a service does, but understanding how it behaves within a larger ecosystem of interconnected components.
In real-world cloud environments, data systems are rarely isolated. Instead, they are composed of multiple layers that continuously interact with one another. Data flows from ingestion systems into storage layers, passes through transformation engines, and eventually reaches analytical platforms. Each stage depends on the correctness and efficiency of the previous one. Because of this, cloud data engineering becomes an exercise in coordination rather than isolated execution.
At this level of understanding, architecture becomes the central theme. Every decision, whether related to performance, cost, scalability, or security, must be evaluated in terms of its impact on the overall system. This requires a mindset shift from “how does this service work” to “how does this system behave under real-world conditions.”
One of the most important realizations at this stage is that there is rarely a single correct solution. Instead, there are multiple viable architectures, each with different trade-offs. A system optimized for speed may consume more resources, while a system optimized for cost may introduce latency. Understanding these trade-offs is essential for designing balanced solutions.
Cloud data architecture also requires awareness of system constraints. These include network limitations, storage bottlenecks, compute capacity, and service quotas. Designing within these constraints requires both technical knowledge and practical judgment.
Designing Scalable and Resilient Data Pipelines
Scalability is one of the defining characteristics of cloud-based systems. Unlike traditional systems that rely on fixed hardware, cloud environments are designed to expand or contract based on demand. This elasticity is what enables modern data systems to handle massive workloads.
A scalable data pipeline is one that can handle increasing volumes of data without degradation in performance. Achieving this requires careful planning at every stage of the pipeline. Ingestion systems must be able to absorb higher data rates, storage systems must accommodate growing datasets, and processing systems must distribute workloads efficiently.
Horizontal scaling plays a key role in achieving this. Instead of upgrading a single machine, additional nodes are added to distribute the workload. This approach improves both performance and reliability.
Resilience is equally important. A resilient system is one that continues to operate even when components fail. In distributed environments, failures are not exceptions but expected occurrences. Systems must therefore be designed with redundancy and recovery mechanisms.
Fault tolerance is often achieved through replication, retry mechanisms, and automated recovery processes. These ensure that data is not lost and processing continues even in the event of hardware or network failures.
Another important aspect of resilience is decoupling system components. When services are tightly coupled, a failure in one component can cascade through the entire system. Decoupling reduces this risk by allowing components to operate independently.
Advanced Data Modeling Strategies in Cloud Environments
Data modeling is a foundational skill in designing efficient cloud systems. At an advanced level, it goes beyond basic schema design and focuses on optimizing data structures for performance, scalability, and analytical efficiency.
In cloud environments, data modeling must account for distributed storage and processing. Traditional relational models may not always be suitable for large-scale analytics workloads. Instead, hybrid approaches are often used.
Denormalization is commonly applied in analytical systems to reduce the need for complex joins. While this may increase storage requirements, it significantly improves query performance.
Dimensional modeling is another widely used approach. It organizes data into fact and dimension tables, making it easier to perform analytical queries. This structure is particularly useful in data warehousing environments.
Partitioning strategies also play a critical role in data modeling. By dividing data into logical segments, systems can improve query efficiency and reduce processing overhead.
Choosing the right data model requires understanding both the nature of the data and the intended use cases. A model optimized for reporting may not be suitable for real-time analytics, and vice versa.
Optimizing Performance in Large-Scale Data Systems
Performance optimization is one of the most critical aspects of cloud data engineering. Even well-designed systems can suffer from inefficiencies if performance is not carefully managed.
One of the primary factors affecting performance is data volume. As datasets grow, query execution times can increase significantly if systems are not optimized. Techniques such as indexing, partitioning, and caching are used to mitigate this issue.
Indexing allows systems to quickly locate relevant data without scanning entire datasets. However, excessive indexing can increase storage costs and slow down write operations. Therefore, indexing strategies must be carefully balanced.
Partitioning reduces the amount of data scanned during queries by dividing datasets into smaller segments. This is particularly effective in large analytical systems.
Caching improves performance by storing frequently accessed data in memory. This reduces the need to repeatedly fetch data from slower storage layers.
Query optimization is another important area. Understanding how queries are executed allows engineers to identify inefficiencies and improve performance. This includes analyzing execution plans and identifying bottlenecks.
Resource allocation also impacts performance. In cloud environments, compute resources can be dynamically adjusted based on workload demands. Proper resource management ensures that systems remain responsive under varying loads.
Real-World Data Integration Challenges
Integrating data from multiple sources is one of the most complex aspects of cloud data engineering. In real-world environments, data often comes from heterogeneous systems with different formats, structures, and update frequencies.
One of the primary challenges is data consistency. When data is collected from multiple sources, ensuring that it remains consistent across systems can be difficult. Differences in timing, format, and structure can lead to discrepancies.
Data synchronization is another challenge. Keeping systems updated in real time requires efficient data pipelines that can handle continuous updates without delays.
Schema evolution adds another layer of complexity. As systems evolve, data structures may change. Ensuring compatibility between old and new formats is essential for maintaining system stability.
Data quality issues also arise frequently. Incomplete, duplicate, or inconsistent data can affect downstream analytics. Implementing validation and cleansing processes is essential for maintaining accuracy.
Understanding Cost Optimization in Cloud Data Systems
Cost management is an important consideration in cloud environments. While cloud systems offer scalability and flexibility, improper design choices can lead to unnecessary expenses.
One of the key factors affecting cost is storage. Large datasets can quickly accumulate storage costs if not managed efficiently. Choosing appropriate storage classes and data retention policies can help reduce expenses.
Compute usage is another major cost factor. Inefficient queries or poorly optimized processing jobs can consume excessive resources. Optimizing workloads helps reduce compute costs.
Data transfer between services can also contribute to cost. Minimizing unnecessary data movement improves both performance and efficiency.
Automated scaling policies help balance performance and cost by adjusting resources based on demand. This ensures that systems are not over-provisioned during low usage periods.
Understanding cost implications is essential for designing sustainable cloud architectures.
Monitoring, Logging, and Observability in Data Systems
In large-scale cloud environments, monitoring and observability are critical for maintaining system health. Without proper visibility, it becomes difficult to detect issues or optimize performance.
Monitoring involves tracking system metrics such as CPU usage, memory consumption, and query performance. These metrics provide insight into system behavior.
Logging captures detailed information about system events. Logs are essential for troubleshooting and understanding system activity.
Observability goes beyond monitoring and logging by providing a holistic view of system behavior. It allows engineers to understand not just what is happening, but why it is happening.
Alerting systems are used to notify engineers when predefined thresholds are exceeded. This allows for proactive issue resolution.
Together, these components ensure that cloud data systems remain reliable and efficient.
Advanced Security Considerations in Cloud Data Engineering
Security becomes increasingly important as data systems grow in complexity. Protecting sensitive information requires a multi-layered approach that covers data, infrastructure, and access control.
Identity and access management ensures that only authorized users can access specific resources. Role-based access control is commonly used to enforce permissions.
Encryption protects data both at rest and in transit. This ensures that even if data is intercepted, it cannot be read without proper authorization.
Network security involves controlling how systems communicate with each other. Virtual private networks and firewall rules are commonly used to restrict access.
Auditing provides a record of system activity. This is important for compliance and security analysis.
Security design must be integrated into the architecture from the beginning rather than added later.
Building Real-World Problem-Solving Skills
At an advanced level, success depends not only on technical knowledge but also on problem-solving ability. Real-world cloud systems are dynamic, and unexpected issues frequently arise.
Problem-solving involves identifying the root cause of issues rather than addressing symptoms. This requires systematic analysis and logical reasoning.
Debugging distributed systems can be particularly challenging due to their complexity. Issues may arise from multiple interacting components.
Effective problem-solving also involves experimentation. Testing different configurations and observing results helps identify optimal solutions.
Over time, experience builds intuition, making it easier to anticipate and resolve issues.
Conclusion
Preparing for a cloud big data certification is ultimately about developing both technical depth and structured thinking. While the exam itself focuses on validating knowledge of data services, architectures, and workflows, the real value comes from how these concepts shape your ability to design and manage modern data systems. Cloud environments are complex, and success in this space depends on understanding how individual components interact within larger, distributed ecosystems.
Throughout preparation, it becomes clear that memorization alone is not enough. Concepts such as data ingestion, storage strategies, distributed processing, streaming systems, and security controls only become meaningful when they are applied in real-world scenarios. This is why consistent practice, hands-on experimentation, and system-level thinking are essential parts of the learning process.
Equally important is the ability to evaluate trade-offs. Every architectural decision in a cloud environment involves balancing performance, cost, scalability, and reliability. Developing this judgment is what transforms theoretical knowledge into practical expertise. Over time, learners begin to move from understanding isolated services to designing complete, end-to-end data pipelines that function efficiently under real-world conditions.
Another key takeaway is that preparation is not a linear process. It involves revisiting concepts multiple times, refining understanding, and gradually building confidence through application. Mistakes and gaps in knowledge are not setbacks but necessary steps in mastering complex systems.
Ultimately, success in cloud big data certification reflects more than exam readiness. It demonstrates the ability to think critically about data systems, solve complex problems, and contribute to scalable, data-driven environments that power modern digital organizations.