Modern enterprise and service provider networks are expected to deliver continuous availability even under hardware failures, link disruptions, or maintenance events. As applications become more dependent on real-time connectivity, even a brief interruption can impact productivity, customer experience, and critical operations. Traditional single-device redundancy methods are no longer sufficient in high-demand environments where downtime must be minimized or eliminated.
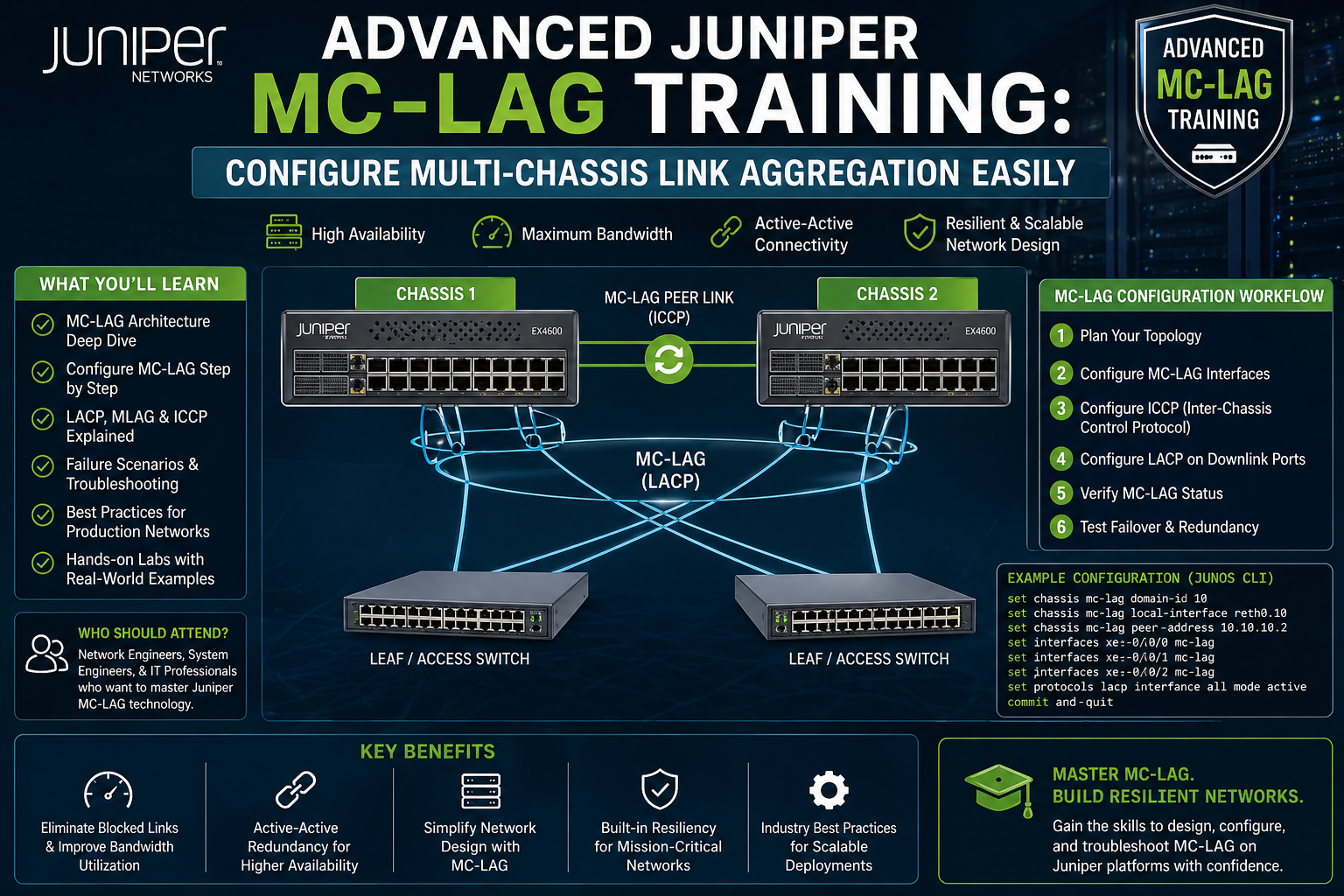
Multi-Chassis Link Aggregation (MC-LAG) emerges as a response to this challenge by extending the concept of link aggregation across multiple physical devices. Instead of relying on a single switch or router to provide aggregated links, MC-LAG allows two or more devices to act as a single logical aggregation system. This design improves both redundancy and performance by ensuring that traffic can continue flowing even if one device experiences a failure.
What MC-LAG represents in network architecture
MC-LAG is essentially an evolution of Link Aggregation Groups (LAGs), where multiple physical Ethernet links are combined into one logical link for higher throughput and redundancy. In a traditional LAG, all member links terminate on a single device. While this protects against individual link failure, it does not protect against device-level failure.
MC-LAG extends this concept by allowing the member links to terminate on different physical devices. These devices operate in coordination, presenting themselves as a unified logical endpoint to connected devices such as servers, switches, or routers. This means that even if one device fails, the aggregated link remains operational through the surviving device.
This architecture is particularly valuable in data centers and large-scale enterprise environments where network availability must be maintained without interruption.
The role of Junos devices in MC-LAG deployment
In environments using Junos operating systems, MC-LAG is implemented through a combination of synchronization protocols, inter-device communication channels, and carefully coordinated link aggregation configurations. Junos-based devices are designed to support advanced high-availability features, and MC-LAG fits naturally into this ecosystem.
The implementation requires two or more participating devices to coordinate their link states, MAC address tables, and forwarding decisions. This coordination ensures that traffic is handled consistently regardless of which physical device processes it.
Junos environments typically use MC-LAG to create highly available core, distribution, or aggregation layers in a network. These layers are critical because they handle large volumes of traffic and often serve as central points of connectivity for multiple downstream systems.
How MC-LAG differs from traditional link aggregation
At a conceptual level, MC-LAG builds upon standard Link Aggregation Control Protocol (LACP) behavior but introduces additional complexity and coordination between multiple chassis.
In a standard LAG, the decision-making process is localized to a single device. That device manages link membership, hashing algorithms, and failover behavior. If the device fails, the entire aggregated link becomes unavailable, regardless of how many physical links were active.
MC-LAG changes this by distributing responsibilities across multiple devices. Each device participates in a shared logical system that ensures consistent forwarding behavior. This includes synchronization of state information and coordination of active and standby roles where applicable.
Unlike traditional LAGs, MC-LAG requires additional control mechanisms to ensure that both devices remain synchronized. Without this coordination, traffic inconsistencies or loops could occur.
The importance of redundancy in MC-LAG design
Redundancy is one of the core motivations behind MC-LAG deployment. In network design, redundancy ensures that a single point of failure does not disrupt connectivity. MC-LAG provides redundancy at both the link level and the device level.
If a single link fails in an MC-LAG configuration, traffic is automatically redistributed across the remaining active links. If an entire device fails, the partner device continues forwarding traffic using its own active links without requiring manual intervention.
This dual-layer redundancy is particularly important in environments where uptime requirements are strict, such as financial systems, cloud infrastructures, and large-scale enterprise networks.
Understanding the concept of logical single endpoint behavior
One of the most important ideas behind MC-LAG is the concept of presenting multiple physical devices as a single logical endpoint. From the perspective of a connected device, such as a server or access switch, the MC-LAG pair appears as one unified aggregation system.
This abstraction simplifies network design on the access side because connected devices do not need to be aware of the underlying redundancy structure. They simply see a single LAG interface and distribute traffic across it as they would in a standard aggregation scenario.
Behind the scenes, however, the MC-LAG pair is continuously exchanging state information to ensure that both devices maintain consistent forwarding behavior.
The role of synchronization between chassis
Synchronization is a critical component of MC-LAG operation. The participating devices must constantly exchange information about link states, interface statuses, and forwarding decisions. Without synchronization, inconsistencies could arise that may lead to traffic loss or duplication.
This synchronization is typically achieved through dedicated communication channels between the devices. These channels ensure that both devices have an up-to-date view of the network state and can respond to changes in real time.
Synchronization also helps ensure that failover events occur smoothly. When one device becomes unavailable, the remaining device already has the necessary information to continue forwarding traffic without interruption.
Active and standby behavior in MC-LAG systems
Depending on the configuration, MC-LAG can operate in different modes, including active-active and active-standby arrangements. In active-active mode, both devices actively forward traffic, distributing load between them. This improves bandwidth utilization and ensures that resources are fully used.
In active-standby mode, one device actively forwards traffic while the other remains in a backup state. The standby device takes over only when the active device fails. This approach may be used in environments where deterministic control over traffic paths is required.
Both modes rely on coordination between devices to ensure that traffic flows remain consistent and predictable.
Understanding inter-device communication in MC-LAG
A key component of MC-LAG architecture is the communication between participating devices. This communication ensures that both devices are aware of each other’s state and can make consistent forwarding decisions.
Without reliable inter-device communication, MC-LAG would not function correctly, as each device might independently make decisions that conflict with the other. The communication channel typically carries control information such as link status updates, interface health information, and synchronization data.
This channel is separate from user data traffic and is designed to ensure stability and reliability in the MC-LAG system.
The role of LACP in MC-LAG environments
Link Aggregation Control Protocol (LACP) plays an important role in MC-LAG configurations. It is responsible for negotiating and managing link aggregation between devices and endpoints.
In an MC-LAG setup, LACP operates in coordination with the multi-chassis framework to ensure that links are properly distributed across devices. However, because MC-LAG extends beyond a single device, LACP alone is not sufficient to manage the full complexity of the system.
Instead, LACP works alongside additional mechanisms that handle inter-device coordination and synchronization.
Network design considerations before implementing MC-LAG
Deploying MC-LAG requires careful planning of network topology and device roles. Designers must consider how devices will be paired, how traffic will be distributed, and how redundancy will be maintained in failure scenarios.
Physical placement of devices is also important. Ideally, MC-LAG peers should be placed in different physical locations or racks to reduce the risk of simultaneous failure due to environmental or hardware issues.
Bandwidth requirements, traffic patterns, and failure recovery expectations must also be analyzed before deployment.
Challenges associated with MC-LAG adoption
While MC-LAG provides significant benefits, it also introduces additional complexity. The need for synchronization, inter-device communication, and careful configuration increases the operational requirements of the network.
Misconfiguration can lead to issues such as traffic loops, asymmetric forwarding, or inconsistent link states. Additionally, troubleshooting MC-LAG environments can be more complex than traditional LAG setups because multiple devices are involved in forwarding decisions.
Despite these challenges, MC-LAG remains widely used due to its strong redundancy and scalability advantages.
Evolution of multi-device redundancy approaches
MC-LAG represents one of several approaches to achieving multi-device redundancy in modern networks. Over time, networking technologies have evolved from simple failover systems to more sophisticated distributed architectures.
The increasing demand for always-on services has driven innovation in how networks handle failure scenarios. MC-LAG is part of this evolution, offering a balance between performance, redundancy, and operational control.
As network environments continue to grow in complexity, multi-device aggregation techniques like MC-LAG are expected to remain important building blocks in resilient infrastructure design.
MC-LAG Control Plane Coordination and Device Roles in Junos Environments
In a Multi-Chassis Link Aggregation (MC-LAG) setup, the most critical element that allows multiple physical devices to behave like a single logical system is the coordination happening at the control plane level. Unlike traditional link aggregation, where a single device independently manages link membership and forwarding decisions, MC-LAG requires a structured exchange of state information between participating devices. This coordination ensures that both devices maintain consistent views of the network, even when operating under dynamic conditions.
Within Junos-based systems, each device in an MC-LAG pair has a clearly defined role in the control plane relationship. These roles are not static in all cases and may change depending on configuration, operational mode, or failure conditions. The control plane is responsible for managing adjacency relationships, synchronizing interface states, and ensuring that both devices agree on forwarding behavior.
A key aspect of this coordination is the exchange of system-level information such as MAC address tables, link states, and neighbor relationships. Without this synchronization, traffic could be misdirected or duplicated, leading to instability in the network. The control plane, therefore, acts as the intelligence layer that maintains consistency between physically separate devices.
Inter-Chassis Communication and the Role of ICL
A fundamental component of MC-LAG architecture is the Inter-Chassis Link (ICL), which serves as a dedicated communication channel between participating devices. The ICL is responsible for carrying synchronization traffic and ensuring that both devices remain aligned in terms of forwarding state and operational status.
Unlike user-facing data links, the ICL is not designed to carry regular traffic from end devices. Instead, it functions as a high-speed, reliable pathway for control information. This includes updates about link failures, MAC address learning, and configuration synchronization.
The importance of the ICL becomes especially apparent during failure scenarios. If one device loses connectivity to downstream devices, the remaining device relies on the ICL to determine how traffic should be handled and whether failover actions are required. Without a properly functioning ICL, MC-LAG behavior becomes unpredictable and may result in traffic disruption.
In Junos-based implementations, the ICL is tightly integrated into the overall MC-LAG framework, ensuring that both devices maintain real-time awareness of each other’s state. This continuous exchange of information is what allows MC-LAG to provide seamless redundancy across chassis boundaries.
ICCP and Its Role in MC-LAG Synchronization
Inter-Control Center Communications Protocol (ICCP) is another essential component in MC-LAG deployments. It is responsible for enabling control plane communication between devices in a structured and reliable manner. ICCP provides the mechanism through which MC-LAG peers exchange operational data required for coordination.
ICCP operates as a session-based protocol that maintains continuous communication between devices. Through this session, devices exchange information about interface status, redundancy states, and system health. This ensures that both sides of the MC-LAG system have an accurate and up-to-date understanding of the network environment.
One of the most important functions of ICCP is its role in redundancy group management. By using ICCP, MC-LAG peers can determine which device should take active responsibility for specific traffic flows and how failover should be handled in case of failure.
ICCP also plays a role in maintaining consistency across configuration changes. When updates are made to MC-LAG-related settings, ICCP ensures that both devices apply these changes in a synchronized manner, reducing the risk of mismatched configurations.
CE LAG Configuration and Endpoint Interaction
Customer Edge (CE) Link Aggregation Groups represent the connection point between external devices and the MC-LAG system. From the perspective of connected devices, the MC-LAG pair appears as a single logical aggregation group. This abstraction simplifies configuration on the customer-facing side, as no special awareness of the underlying multi-device structure is required.
CE LAGs operate using standard link aggregation principles, including load balancing and redundancy across multiple physical links. However, in an MC-LAG environment, these links are distributed across different physical chassis. This distribution ensures that traffic continues to flow even if one device fails.
The interaction between CE devices and the MC-LAG system is governed by LACP behavior. The MC-LAG pair presents itself as a unified system, while internally coordinating link distribution across multiple devices. This allows external devices to operate normally without requiring special configuration adjustments.
CE LAGs also play a role in traffic distribution strategies. Depending on hashing algorithms and interface configurations, traffic can be evenly distributed across available links, improving overall bandwidth utilization while maintaining redundancy.
Active-Standby Operation and Traffic Determinism
In some MC-LAG deployments, active-standby mode is used instead of active-active operation. In this configuration, one device is responsible for actively forwarding traffic, while the other remains in a standby state. The standby device takes over only when the active device fails or becomes unavailable.
Active-standby mode is often chosen in environments where deterministic traffic paths are required. By controlling which device handles traffic at any given time, network administrators can ensure predictable behavior and simplified troubleshooting.
The transition between active and standby states is managed through control plane synchronization. When a failure is detected, the standby device quickly assumes the active role, using pre-synchronized state information to continue forwarding traffic without interruption.
Although this mode reduces complexity in some cases, it may also result in underutilization of available bandwidth, since only one device actively forwards traffic under normal conditions.
Active-Active MC-LAG and Load Distribution Strategies
Active-active MC-LAG configurations allow both devices to simultaneously forward traffic. This approach maximizes resource utilization and improves overall network throughput. In this model, traffic is distributed across both chassis based on predefined hashing algorithms and link selection mechanisms.
Each device independently forwards traffic for its assigned flows while maintaining synchronization with its peer. This requires precise coordination to ensure that traffic is not duplicated or misrouted.
The main advantage of active-active operation is improved performance and redundancy. If one device fails, the remaining device continues handling all traffic without requiring a complete role transition, since it was already actively participating in forwarding.
However, active-active configurations require more complex synchronization logic, particularly in maintaining consistent MAC address learning and forwarding tables across both devices.
MAC Address Synchronization and Forwarding Consistency
One of the most important technical challenges in MC-LAG systems is maintaining consistent MAC address tables across multiple devices. Since both devices may receive traffic for the same endpoints, they must continuously synchronize learned MAC addresses to avoid forwarding inconsistencies.
When a MAC address is learned on one device, this information must be communicated to its MC-LAG peer through synchronization channels. This ensures that both devices can correctly forward return traffic without unnecessary flooding.
Without proper MAC synchronization, traffic could be sent to incorrect ports or result in duplicate forwarding. This is particularly important in active-active environments where both devices are simultaneously processing traffic flows.
Junos-based MC-LAG systems handle MAC synchronization as part of their broader control plane coordination mechanisms, ensuring that forwarding decisions remain consistent across the entire system.
Failure Detection and Convergence Behavior
Failure detection in MC-LAG environments is a multi-layered process that involves monitoring both link-level and device-level health. Each device continuously monitors the status of its interfaces as well as the health of its MC-LAG peer.
When a failure is detected, the system initiates a convergence process to restore stable forwarding behavior. This process involves updating forwarding tables, recalculating link distribution, and potentially transitioning roles between devices.
The speed of convergence is critical in maintaining network stability. MC-LAG systems are designed to minimize disruption by using pre-synchronized state information, allowing the surviving device to continue forwarding traffic with minimal delay.
In cases where only individual links fail, traffic is redistributed across remaining active links. In cases of device failure, the peer device assumes full responsibility for all traffic flows.
Traffic Hashing and Load Balancing Mechanisms
Traffic distribution in MC-LAG systems is governed by hashing algorithms that determine how packets are assigned to specific links. These algorithms typically consider factors such as source and destination IP addresses, MAC addresses, or transport-layer information.
The goal of hashing is to ensure even distribution of traffic across available links while maintaining flow consistency. This means that packets belonging to the same flow are typically sent over the same physical link to avoid reordering issues.
In MC-LAG environments, hashing decisions must also account for the presence of multiple chassis. This adds complexity, as the system must ensure that traffic is not only balanced across links but also across devices.
Proper configuration of hashing mechanisms is essential for achieving optimal performance and avoiding uneven load distribution.
Interoperability Considerations in MC-LAG Deployments
MC-LAG implementations are often vendor-specific, meaning that behavior can vary significantly between different networking platforms. While the underlying concept remains consistent, the protocols and mechanisms used for synchronization may differ.
This creates challenges in mixed-vendor environments, where interoperability must be carefully evaluated. Devices must be able to agree on link aggregation behavior, failover mechanisms, and control plane communication methods.
In Junos-based environments, MC-LAG is implemented using proprietary coordination mechanisms that ensure tight integration between participating devices. However, when connecting to external systems, standard LACP behavior is typically used to maintain compatibility.
Understanding these interoperability boundaries is essential when designing large-scale networks that involve multiple vendor platforms.
Operational Monitoring and System Visibility
Monitoring MC-LAG systems requires visibility into both link-level and system-level behavior. Administrators must be able to observe interface states, synchronization status, and traffic distribution patterns.
Key indicators include link health, MC-LAG peer status, and control channel stability. These metrics provide insight into whether the system is operating correctly or experiencing synchronization issues.
In addition to real-time monitoring, historical data analysis can help identify performance trends and potential issues. This includes tracking failover events, traffic distribution changes, and link utilization patterns.
Effective monitoring ensures that MC-LAG systems continue to operate reliably under varying network conditions.
Troubleshooting Behavior in Multi-Chassis Environments
Troubleshooting MC-LAG systems requires a structured approach due to the distributed nature of the architecture. Unlike single-device systems, issues may originate from either physical device, the inter-chassis link, or synchronization mechanisms.
Common troubleshooting areas include mismatched configurations, failed synchronization sessions, or inconsistent MAC tables. Each of these issues can lead to traffic disruption or suboptimal performance.
Diagnosing MC-LAG problems often involves examining control plane communication, verifying link states, and analyzing forwarding behavior across both devices. Because multiple systems are involved, isolating the root cause requires careful analysis of inter-device interactions.
Understanding how each component contributes to overall system behavior is essential for effective troubleshooting in MC-LAG environments.
Advanced MC-LAG Deployment Design Patterns in Junos Networks
Designing Multi-Chassis Link Aggregation (MC-LAG) at scale goes far beyond simply connecting two devices. In real-world Junos environments, MC-LAG becomes part of a broader architectural strategy that shapes how traffic flows across data centers, enterprise cores, and service provider aggregation layers. The way MC-LAG is designed directly impacts performance, resilience, operational complexity, and scalability.
At its core, MC-LAG is used to eliminate single points of failure while preserving the simplicity of link aggregation for connected devices. However, achieving this balance requires careful planning of topology, device roles, interconnect behavior, and traffic distribution strategies.
In modern network designs, MC-LAG is often positioned in aggregation layers where it connects access switches to core infrastructure. This placement ensures that redundancy is maintained close to the edge, where device failure risk is higher, and traffic diversity is greater.
Designing MC-LAG Topologies for Scalability
Scalability in MC-LAG environments depends heavily on how devices are arranged and interconnected. A typical MC-LAG deployment involves two or more devices forming a redundancy group, but larger architectures may include multiple MC-LAG pairs distributed across different network tiers.
One common design approach is to use MC-LAG at the aggregation layer while keeping the core layer independent. This separation allows aggregation devices to provide redundancy and load balancing, while core devices focus on high-speed routing and forwarding.
As networks grow, MC-LAG domains may be expanded horizontally by adding additional pairs of devices. Each pair operates independently but follows consistent design principles to ensure predictable behavior across the network.
Proper scaling also requires careful attention to inter-device communication overhead. As more links and devices are added, synchronization traffic increases, which can impact performance if not properly managed.
Traffic Engineering and Flow Optimization in MC-LAG
Traffic engineering plays a critical role in MC-LAG deployments because it determines how efficiently network resources are utilized. Since MC-LAG distributes traffic across multiple links and devices, the choice of hashing algorithms and load-balancing strategies directly affects performance.
In Junos environments, traffic distribution is typically based on flow-level hashing. This ensures that packets belonging to the same session follow a consistent path, reducing the risk of packet reordering. However, when multiple devices are involved, additional considerations must be made to ensure even distribution across the chassis.
Uneven traffic distribution can lead to scenarios where one device becomes overloaded while the other remains underutilized. This not only reduces efficiency but can also increase latency and packet loss under high load conditions.
To mitigate this, network designers often adjust hashing parameters to include additional fields such as Layer 4 port numbers or session identifiers. This increases entropy in the distribution process and improves overall balance.
High Availability Strategies Beyond Basic MC-LAG
While MC-LAG itself provides significant redundancy, advanced deployments often combine it with additional high availability mechanisms to create multi-layer resilience. These may include redundant routing protocols, fast convergence techniques, and upstream failover strategies.
In such designs, MC-LAG acts as the first layer of protection at the link and device level. Above this, routing protocols ensure that traffic can be rerouted across different network paths in case of larger-scale failures.
This layered approach ensures that no single failure domain can disrupt service continuity. Even if an entire MC-LAG pair becomes unavailable, upstream routing mechanisms can redirect traffic through alternate paths.
Combining MC-LAG with other redundancy techniques also improves maintenance flexibility. Devices can be upgraded or replaced with minimal impact on network availability.
Role of MC-LAG in Data Center Architectures
In data center environments, MC-LAG is commonly used to connect server access layers to aggregation switches. This allows servers with multiple network interfaces to maintain continuous connectivity even during switch failures.
Data centers often require extremely high levels of availability, especially in environments hosting cloud services, financial applications, or distributed computing systems. MC-LAG helps meet these requirements by ensuring that server connectivity is not dependent on a single physical switch.
In spine-leaf architectures, MC-LAG is typically deployed at the leaf layer, where it connects directly to compute nodes. The spine layer remains independent, handling inter-leaf traffic routing.
This separation of roles ensures that MC-LAG handles local redundancy while the spine layer manages global traffic distribution across the data center.
Failure Domains and Isolation in MC-LAG Systems
A key principle in MC-LAG design is the concept of failure domain isolation. Each MC-LAG pair should ideally operate within a defined failure boundary, ensuring that a single fault does not cascade across the network.
By distributing MC-LAG pairs across different racks, power supplies, or even physical locations, designers can significantly reduce the likelihood of correlated failures.
Failure isolation also extends to control plane communication. If the inter-chassis link is disrupted, the system must be able to detect the issue and adjust forwarding behavior accordingly to avoid traffic blackholing or duplication.
Proper isolation ensures that MC-LAG remains resilient even under complex failure scenarios involving multiple components.
Control Plane Stability and Convergence Optimization
The stability of the control plane is essential for maintaining reliable MC-LAG operation. Since MC-LAG relies heavily on synchronization between devices, any instability in control communication can lead to inconsistent forwarding behavior.
Convergence time is another critical factor. When a failure occurs, the system must quickly adjust to the new topology without introducing significant packet loss or delay.
Junos-based MC-LAG systems are designed to minimize convergence time by maintaining pre-established synchronization between devices. This allows the system to react quickly to changes without requiring full reconvergence.
However, convergence performance can still be affected by factors such as link latency, device load, and configuration complexity. Careful tuning of system parameters is often required in large-scale deployments.
Interaction Between MC-LAG and Routing Protocols
MC-LAG operates at Layer 2 of the network model, but it often interacts closely with Layer 3 routing protocols. This interaction is particularly important in environments where MC-LAG devices also perform routing functions.
Routing protocols such as OSPF or BGP rely on stable underlying connectivity. MC-LAG provides this stability by ensuring that link-level redundancy is maintained even during device failures.
However, routing protocols must also be aware of MC-LAG behavior to avoid suboptimal path selection. For example, if one MC-LAG device fails, routing updates must reflect the change quickly to prevent traffic from being sent to unavailable paths.
In advanced designs, MC-LAG and routing protocols are tightly integrated to ensure consistent network behavior across both layers.
Maintenance Operations in MC-LAG Environments
One of the advantages of MC-LAG is its ability to support maintenance operations without service interruption. Devices can be upgraded, rebooted, or replaced while traffic continues to flow through the remaining active device.
This capability is particularly valuable in environments requiring continuous availability. Maintenance tasks can be performed during normal operation windows without requiring full network downtime.
During maintenance, traffic is automatically redistributed across available links, ensuring that end devices remain connected. Once the maintenance operation is complete, the device can rejoin the MC-LAG group and resume normal operation.
Proper coordination between devices is essential during these operations to avoid temporary inconsistencies in forwarding behavior.
Security Considerations in MC-LAG Deployments
Security is an important aspect of MC-LAG design, particularly because multiple devices share a synchronized control plane. If the inter-device communication channel is compromised, it could potentially affect the integrity of the entire MC-LAG system.
To mitigate this risk, secure communication mechanisms are typically used for synchronization traffic. This ensures that only authorized devices can participate in the MC-LAG group.
Additionally, access control policies are often implemented to restrict configuration changes and prevent unauthorized modifications to MC-LAG settings.
Security considerations also extend to data plane traffic, where consistent forwarding behavior must be maintained to prevent traffic interception or misrouting.
Performance Tuning and Optimization Techniques
Optimizing MC-LAG performance involves adjusting multiple parameters across both control and data planes. These include link selection policies, hashing algorithms, interface priorities, and synchronization intervals.
One of the primary goals of optimization is to ensure even traffic distribution across all available links and devices. This helps maximize bandwidth utilization and prevent congestion.
Another important aspect is minimizing the latency introduced by synchronization processes. While control plane communication is essential, excessive overhead can impact overall system performance.
Careful tuning ensures that MC-LAG systems operate efficiently without compromising stability or redundancy.
Operational Challenges in Large-Scale MC-LAG Deployments
As MC-LAG deployments grow in size and complexity, operational challenges become more pronounced. Managing multiple MC-LAG pairs across a large network requires careful coordination and monitoring.
Configuration consistency is one of the most common challenges. Even small mismatches between devices can lead to synchronization issues or traffic imbalance.
Another challenge is troubleshooting distributed failures, where issues may span multiple devices and layers of the network. Identifying the root cause in such environments requires deep visibility into both control and data plane behavior.
Operational discipline and standardized design practices are essential to maintaining stability in large-scale MC-LAG environments.
Evolution of MC-LAG in Modern Networking Architectures
MC-LAG continues to evolve alongside modern networking trends. As networks become more distributed and software-driven, traditional hardware-based redundancy mechanisms are being enhanced with more intelligent coordination systems.
Newer architectures are exploring tighter integration between MC-LAG and software-defined networking principles. This allows for more dynamic control of traffic flows and improved automation of failover behavior.
Despite these advancements, the core principles of MC-LAG remain the same: provide redundancy, improve availability, and simplify connectivity for downstream devices.
As network demands continue to increase, MC-LAG will remain a foundational technology in ensuring resilient and high-performance infrastructure.
Extending Operational Visibility and Telemetry in MC-LAG Systems
In modern Junos-based MC-LAG environments, operational visibility has become increasingly important as networks scale in both size and complexity. Traditional monitoring methods that focus only on interface status or device health are no longer sufficient. Instead, deeper telemetry is required to understand how traffic is flowing across multiple chassis, how synchronization behaves under load, and how quickly the system responds to changes in topology.
Advanced telemetry in MC-LAG environments often includes real-time tracking of link utilization across each member interface. This allows administrators to identify uneven traffic distribution, which can indicate hashing inefficiencies or suboptimal configuration. By observing traffic patterns at a granular level, network operators can adjust settings to improve balance and reduce congestion on specific links.
Another important aspect of visibility is monitoring the health of inter-chassis communication. Since MC-LAG depends heavily on continuous synchronization between devices, any degradation in this communication channel can have a direct impact on forwarding stability. Subtle delays or packet loss in control messages may not immediately cause failures but can lead to inconsistent state synchronization over time. This is why continuous monitoring of control plane latency and reliability is critical in production environments.
Modern MC-LAG deployments also benefit from event correlation systems that aggregate logs from both devices in the redundancy group. Instead of analyzing each device separately, correlated logging provides a unified view of system behavior. This makes it easier to trace failure sequences, identify root causes, and understand how events propagate across the MC-LAG pair.
Scaling MC-LAG in Multi-Tier Network Architectures
As network infrastructures evolve into multi-tier architectures, MC-LAG must adapt to support increasingly complex topologies. In large enterprise or service provider environments, MC-LAG is no longer limited to simple access-aggregation pairs. Instead, it is integrated into hierarchical designs where multiple MC-LAG domains interact with each other across different layers.
At scale, one of the key challenges is maintaining consistency in design across all MC-LAG pairs. Even minor variations in configuration can lead to unpredictable behavior when traffic traverses multiple aggregation points. For this reason, standardized templates and design frameworks are often used to ensure uniform deployment.
Another important consideration in large-scale environments is inter-MC-LAG traffic behavior. When multiple MC-LAG pairs exist within the same network, traffic may need to traverse several redundant domains before reaching its destination. Ensuring that each domain handles traffic consistently requires careful coordination of routing policies and forwarding logic.
As networks expand further, hierarchical redundancy strategies are often introduced. In such designs, lower-tier MC-LAG pairs handle local access redundancy, while upper-tier pairs manage aggregation-level resilience. This layered redundancy model ensures that failures are contained within specific segments of the network without impacting the entire infrastructure.
Behavioral Dynamics During Partial Failures
One of the more complex aspects of MC-LAG operation is its behavior during partial failures, where only a subset of links or interfaces fail rather than an entire device. These scenarios require nuanced decision-making at the control plane level to determine how traffic should be redistributed.
When a partial failure occurs, the system must quickly evaluate which links remain viable and how traffic loads should be adjusted. This involves recalculating hashing distributions and potentially shifting traffic flows to maintain balance across remaining active interfaces.
In some cases, partial failures can lead to transient imbalances where one device temporarily handles more traffic than the other. While this is generally expected behavior during recovery, prolonged imbalance may indicate underlying issues such as misconfigured link weights or uneven interface performance.
The ability of MC-LAG systems to gracefully handle partial failures without full disruption is one of its key strengths. However, it also introduces complexity in understanding system behavior, especially when multiple partial failures occur simultaneously across different components.
Long-Term Stability and Lifecycle Management of MC-LAG Deployments
Over time, MC-LAG systems require ongoing lifecycle management to ensure continued stability and performance. This includes periodic validation of synchronization health, review of traffic distribution patterns, and verification of configuration consistency across devices.
As hardware ages or network demands increase, adjustments may be required to maintain optimal performance. This could involve upgrading link capacities, rebalancing traffic across interfaces, or modifying redundancy group configurations.
Lifecycle management also includes planning for device replacement or upgrade cycles. Because MC-LAG allows for non-disruptive maintenance, devices can be upgraded individually while maintaining overall system availability. However, careful coordination is required to ensure that both devices remain compatible throughout the transition process.
In long-running deployments, configuration drift between MC-LAG peers can become a subtle but significant issue. Even minor inconsistencies in interface settings or protocol parameters can lead to synchronization inefficiencies or unexpected behavior. Regular audits and configuration validation processes help mitigate this risk and ensure long-term stability.
As MC-LAG continues to be deployed in increasingly critical environments, its lifecycle management becomes just as important as its initial design. Proper operational discipline ensures that the system remains reliable, scalable, and resilient throughout its operational lifespan.
Conclusion
Multi-Chassis Link Aggregation (MC-LAG) represents a significant step forward in the evolution of resilient network design, especially in environments where uptime, scalability, and performance are critical. By extending traditional link aggregation across multiple physical devices, MC-LAG eliminates the limitations of single-chassis dependency and introduces a more robust approach to redundancy. This architectural shift allows networks to maintain continuous operation even in the presence of hardware failures, link disruptions, or planned maintenance activities.
One of the most important strengths of MC-LAG lies in its ability to present multiple physical devices as a single logical entity. From the perspective of connected systems, this abstraction simplifies network integration while still delivering advanced redundancy behind the scenes. Devices such as servers, switches, and routers interact with MC-LAG systems using standard link aggregation principles, without needing awareness of the underlying multi-device structure. This simplicity at the edge contrasts with the complexity operating within the MC-LAG core, where continuous synchronization and coordination ensure consistent forwarding behavior.
In Junos-based environments, MC-LAG is supported by a combination of inter-chassis communication, synchronization protocols, and link aggregation mechanisms that work together to maintain stability. The Inter-Chassis Link (ICL) and ICCP-based communication channels play a vital role in ensuring that both devices remain aligned in terms of state, configuration, and forwarding decisions. This tight coordination is what enables seamless failover behavior and prevents traffic disruption during device or link failures.
Another key advantage of MC-LAG is its flexibility in supporting both active-active and active-standby configurations. This allows network designers to tailor deployments based on specific performance and redundancy requirements. Active-active setups maximize bandwidth utilization by distributing traffic across multiple devices, while active-standby configurations prioritize deterministic control and simplified failover behavior. This adaptability makes MC-LAG suitable for a wide range of network scenarios, from high-performance data centers to enterprise aggregation layers.
However, MC-LAG is not without its challenges. Its distributed nature introduces complexity in configuration, troubleshooting, and operational management. Synchronization between devices must remain consistent at all times, and even minor mismatches can lead to traffic inconsistencies or performance degradation. Additionally, scaling MC-LAG across large networks requires careful planning to avoid excessive control plane overhead and to ensure uniform design practices across all deployment points.
Despite these challenges, MC-LAG remains a widely adopted solution due to its strong balance of redundancy, performance, and operational transparency for end devices. It effectively bridges the gap between simple link aggregation and full network redundancy architectures, offering a practical and efficient way to build resilient infrastructures.
As networking environments continue to evolve toward higher levels of automation, virtualization, and distributed architecture, MC-LAG is expected to remain a foundational technology. Its principles align closely with modern demands for always-on connectivity and fault-tolerant design. Future developments are likely to further integrate MC-LAG with software-driven networking models, improving automation, visibility, and adaptability.
Ultimately, MC-LAG plays a crucial role in ensuring that modern networks can withstand failures without service interruption. By combining intelligent control plane coordination with flexible data plane distribution, it provides a reliable framework for building high-availability systems. Its continued relevance in both enterprise and service provider environments underscores its importance as a core technology in resilient network engineering.