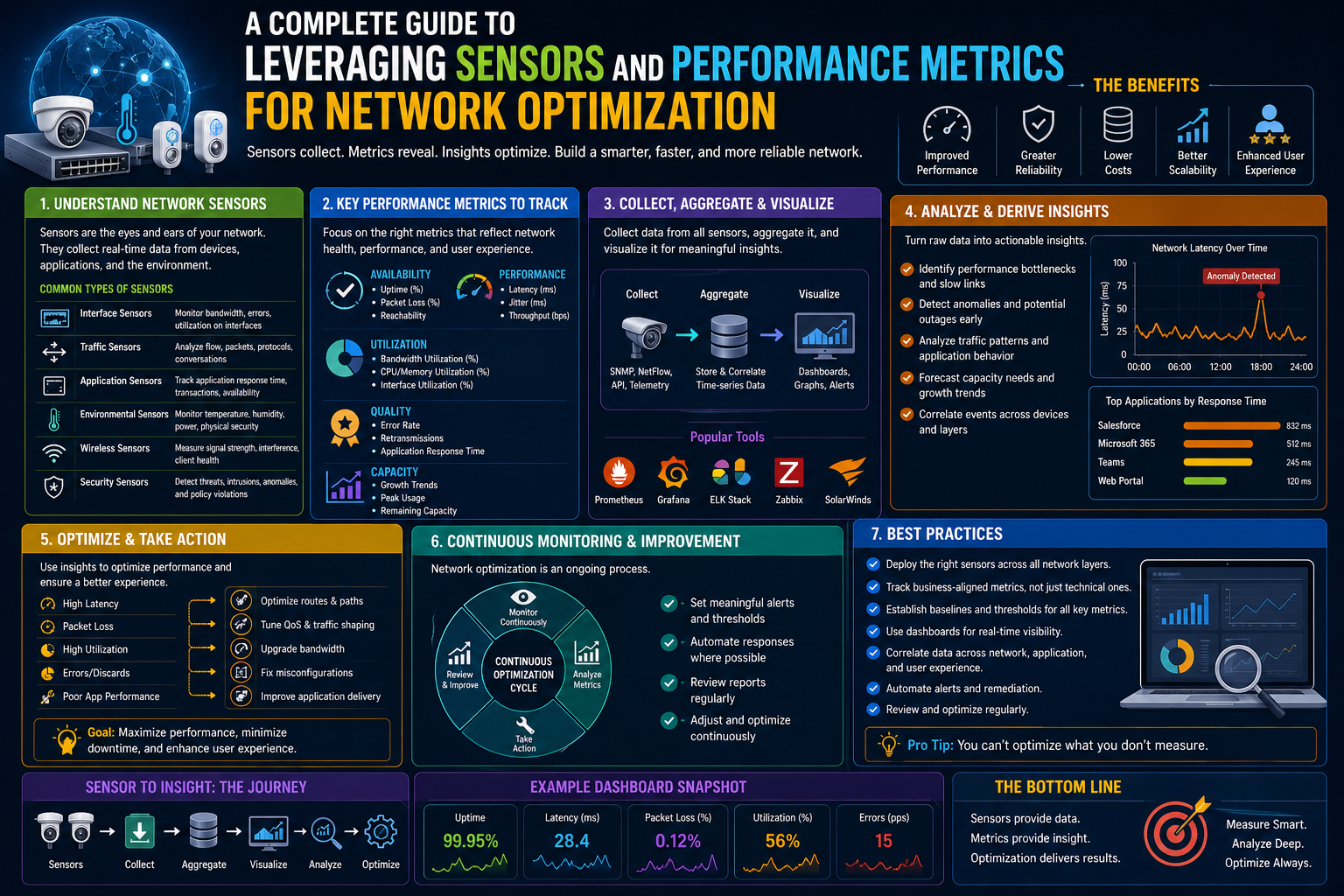
In today’s digitally connected world, networks form the backbone of nearly every business operation. Whether it is cloud-based applications, remote collaboration tools, internal databases, or customer-facing platforms, everything depends on the smooth flow of data across a network. This constant dependency makes network visibility a critical requirement rather than a technical luxury.
Network performance metrics act as the measuring system of this digital environment. They translate complex network behavior into measurable indicators that reveal how well systems are functioning. These metrics help IT teams understand whether the network is healthy, struggling, or approaching failure conditions.
At a basic level, performance metrics are numerical indicators that describe how data moves, how systems respond, and how reliable connections remain over time. However, their real value lies not in the numbers themselves but in the patterns and insights those numbers reveal when continuously monitored.
Modern networks generate massive amounts of data every second. Without structured measurement, this data would be impossible to interpret. Performance metrics organize this flow into meaningful categories, making it easier to identify issues such as congestion, latency spikes, packet loss, or system overload.
These insights allow organizations to shift from reactive troubleshooting to proactive network management. Instead of waiting for users to report problems, IT teams can detect anomalies early and respond before disruptions escalate.
The Role of Network Sensors in Data Collection
While performance metrics define what needs to be measured, network sensors are responsible for gathering that information. Sensors act as the observational layer of the network, continuously collecting data from different points in the infrastructure.
They operate silently in the background, monitoring traffic, analyzing behavior, and reporting key information to centralized systems. Without sensors, performance metrics would remain theoretical concepts with no real-time input.
Network sensors come in different forms depending on how they interact with the system. Some actively generate traffic to test performance, while others observe existing traffic without interference. Together, they provide a complete picture of network activity.
These tools are essential in environments where speed, reliability, and uptime are critical. Large organizations often deploy hundreds or even thousands of sensors across distributed systems to ensure complete visibility.
Sensors help bridge the gap between raw network activity and meaningful performance analysis. By capturing real-time data, they allow systems to reflect actual user experience rather than estimated performance values.
How Performance Metrics and Sensors Work Together
The relationship between metrics and sensors is foundational to modern network monitoring. Metrics define the parameters of interest, while sensors collect the data required to calculate those parameters.
For example, a metric like latency requires time-based data on how long it takes for information to travel across the network. Sensors capture timestamps at different points, and monitoring systems use that information to compute the final value.
This interaction creates a continuous feedback loop. Sensors collect data, systems analyze it, and metrics reflect the outcome. Over time, this cycle builds a historical record of network behavior that can be used for trend analysis and forecasting.
This combination also supports real-time decision-making. If a sensor detects unusual traffic patterns or delays, the system can immediately update performance metrics and trigger alerts.
The integration of sensors and metrics forms the foundation of network observability. Instead of simply knowing whether a system is up or down, organizations gain deep insight into why performance changes occur and how they can be addressed.
Key Categories of Network Performance Metrics
Network performance cannot be understood through a single measurement. It requires multiple categories of metrics that each represent a different aspect of system behavior. These categories work together to provide a complete performance profile.
Availability Indicators
Availability metrics measure how consistently a network remains operational. They focus on uptime and downtime patterns, helping organizations understand reliability over time.
One important aspect is system uptime, which reflects the percentage of time the network remains accessible and functional. High uptime is essential for business continuity, especially in environments where downtime directly affects productivity.
Another important measure is failure frequency, which tracks how often disruptions occur. Even if outages are short, frequent interruptions can indicate deeper infrastructure problems.
Recovery time is also part of availability analysis. It shows how quickly systems return to normal operation after a failure event. Faster recovery typically indicates stronger infrastructure resilience.
Reliability Measurements
Reliability metrics focus on the consistency and accuracy of data transmission. They help determine whether information is being delivered correctly without distortion or loss.
Packet loss is one of the most critical indicators in this category. When data packets fail to reach their destination, communication quality suffers. High packet loss often leads to incomplete transactions or broken application performance.
Jitter measures variations in data delivery timing. Even if data arrives successfully, inconsistent timing can cause disruptions, especially in real-time applications such as video conferencing or voice communication.
Error rates track how often data becomes corrupted during transmission. These errors may result from hardware issues, signal interference, or network congestion.
Together, these metrics provide insight into how stable and dependable a network truly is under real operating conditions.
Throughput and Capacity Metrics
Throughput metrics measure how much data a network can handle within a given timeframe. They help determine whether the infrastructure is being used efficiently or operating under strain.
Bandwidth utilization reflects how much of the available capacity is currently in use. High utilization may indicate strong demand, but if it consistently reaches maximum levels, it can signal potential congestion.
Data transfer rates measure the actual speed at which information moves across the network. This metric is especially important for applications that rely on large file transfers or continuous data streams.
Transaction rates measure how many operations are completed per second. This is particularly relevant in environments where multiple systems communicate simultaneously, such as financial platforms or cloud services.
These metrics help organizations balance performance demands with available infrastructure resources.
Latency and Response Time Metrics
Latency metrics focus on delay within the network. They measure how quickly data travels from one point to another and how long systems take to respond.
Round-trip time measures the full journey of data from source to destination and back again. It provides a complete view of communication delay across the network path.
Network delay isolates the time taken for data to move in one direction. This helps identify where slowdowns occur within the system.
Application response time measures how quickly software systems react to user requests. Even if the network itself is fast, slow application responses can negatively affect user experience.
Latency-related metrics are especially important in modern digital environments where users expect near-instant responses.
Types of Network Sensors and Their Functional Roles
Network sensors play a crucial role in translating raw traffic into structured insights. They are generally categorized based on how they collect data and the type of visibility they provide.
Active Monitoring Sensors
Active sensors generate traffic to test network behavior under controlled conditions. They simulate real user activity by sending requests through the network and measuring responses.
These sensors are useful for identifying potential issues before they affect users. Since they operate in a controlled manner, they can test specific conditions such as connectivity, routing efficiency, or DNS resolution.
Active monitoring helps create predictable performance benchmarks. By comparing expected results with actual outcomes, teams can quickly identify deviations.
Passive Monitoring Sensors
Passive sensors do not generate traffic. Instead, they observe and analyze existing network activity. This allows them to capture real-world performance without influencing system behavior.
These sensors provide highly accurate insights into actual user experience. They can detect subtle performance issues that may not appear during controlled testing.
Passive monitoring is especially useful for understanding long-term trends and identifying recurring performance patterns.
Hybrid Monitoring Approaches
Many modern systems use a combination of active and passive sensors. This hybrid approach ensures both controlled testing and real-world observation.
Active sensors help detect infrastructure weaknesses, while passive sensors provide continuous operational visibility. Together, they create a more complete monitoring framework.
This combined approach is essential in complex environments such as cloud ecosystems, hybrid networks, and distributed enterprise systems.
Data Flow and Monitoring Architecture in Network Systems
Behind every performance metric lies a structured data flow system. This architecture determines how information moves from sensors to analytics platforms and eventually to decision-making systems.
Sensors are typically deployed at strategic points within the network. These points may include routers, switches, servers, or endpoints. Each sensor captures specific types of data based on its position.
Once collected, data is transmitted to aggregation systems. These systems organize and normalize incoming information so it can be analyzed consistently.
After processing, the data is stored in monitoring platforms where it can be visualized and interpreted. These platforms often present information in the form of dashboards, trends, and alerts.
This architecture ensures that raw network activity is transformed into meaningful insights. Without this structured flow, performance data would remain fragmented and difficult to interpret.
Establishing Network Baselines for Performance Understanding
One of the most important concepts in network monitoring is the idea of a baseline. A baseline represents normal network behavior under standard operating conditions.
By establishing a baseline, organizations gain a reference point against which all future performance can be compared. This makes it easier to detect anomalies or unusual patterns.
Baselines are created by observing performance metrics over a period of time. During this phase, data is collected under normal operating conditions without major disruptions.
Once established, baselines help identify deviations in real time. If latency increases or throughput drops significantly, the system can immediately recognize that something is outside normal behavior.
Baselines also evolve over time. As networks grow and change, what is considered normal today may not remain the same in the future. Continuous updates ensure accuracy in performance analysis.
The Growing Importance of Real-Time Network Visibility
Modern networks operate in environments where delays and downtime have immediate consequences. Cloud applications, remote work systems, and global digital services require constant availability.
This makes real-time visibility essential. Organizations need to know what is happening inside their networks at any given moment.
Performance metrics and sensors together provide this visibility. They ensure that changes in network behavior are detected instantly and analyzed continuously.
Real-time monitoring also supports faster decision-making. Instead of investigating issues after they occur, IT teams can respond as soon as early warning signs appear.
This shift toward proactive monitoring reflects the increasing complexity of modern digital infrastructure and the need for continuous system awareness.
Designing a Scalable Network Monitoring Architecture
As modern IT environments expand, network monitoring cannot remain a simple collection of tools operating in isolation. It must evolve into a structured architecture capable of handling large volumes of telemetry data, distributed systems, and increasingly complex traffic patterns. A scalable monitoring architecture ensures that performance metrics and sensor data remain usable even as networks grow in size and complexity.
At the core of this architecture is the principle of structured observability. Instead of focusing only on isolated metrics, the system is designed to continuously collect, process, and correlate data from multiple layers of the network. This includes physical devices, virtual systems, cloud infrastructure, and application endpoints.
Scalability becomes essential because network traffic is no longer static. It fluctuates based on user demand, application workloads, and external connectivity requirements. A monitoring system that cannot scale effectively will quickly become overwhelmed, resulting in incomplete insights or delayed alerts.
To address this, modern architectures often rely on distributed sensor deployment combined with centralized or cloud-based analytics engines. This ensures that data collection remains close to the source while analysis happens in a more optimized environment.
The structure typically includes three layers: data collection, data processing, and data visualization. Each layer plays a distinct role in transforming raw network signals into actionable intelligence.
Strategic Placement of Network Sensors Across Infrastructure
The effectiveness of performance monitoring depends heavily on where sensors are placed within the network. Poor placement can lead to blind spots, while strategic deployment ensures comprehensive visibility.
Sensors must be positioned at critical junctures where data flow is most significant. These include entry and exit points of the network, core routing devices, and segments where application traffic is concentrated.
In large-scale environments, sensors are also deployed at edge locations. This helps capture performance data closer to the user, reducing the risk of missing localized issues that may not be visible from centralized monitoring points.
Another important consideration is redundancy. Relying on a single sensor in a critical location can create a single point of failure. Redundant sensor deployment ensures that monitoring continues even if one component fails or becomes unreachable.
Sensor placement is also influenced by network topology. In hierarchical networks, sensors may be distributed across access layers, distribution layers, and core layers to ensure complete coverage.
By carefully designing sensor placement strategies, organizations can achieve a balanced view of both macro-level network performance and micro-level traffic behavior.
Telemetry Data Collection and Signal Processing
Once sensors are deployed, the next challenge is handling the massive amount of telemetry data they generate. Telemetry refers to continuous streams of data collected from network devices, applications, and infrastructure components.
This data must be processed in real time to maintain relevance. Delayed analysis reduces the ability to respond quickly to network issues.
Raw telemetry data is often unstructured and highly granular. It may include packet-level details, timestamped events, device logs, and performance counters. Before it becomes useful, this data must undergo normalization.
Normalization ensures that data from different sources follows a consistent format. This allows monitoring systems to compare and correlate information accurately across the entire network.
After normalization, data is filtered to remove unnecessary noise. Not all collected data is equally valuable, and filtering helps reduce processing overhead while preserving meaningful signals.
Signal processing techniques are then applied to identify patterns, trends, and anomalies. This step transforms raw telemetry into structured insights that can be used for performance analysis.
Building Effective Alerting and Notification Systems
One of the most critical components of network monitoring is the alerting system. Without effective alerts, even the most advanced metrics and sensors lose their practical value.
An alerting system is responsible for notifying administrators when network conditions deviate from expected behavior. These deviations may indicate performance degradation, security threats, or system failures.
Designing an effective alerting system requires careful calibration. If alerts are too sensitive, they generate excessive noise, leading to alert fatigue. If they are too relaxed, critical issues may go unnoticed.
To avoid these extremes, alert thresholds must be defined based on historical performance data. This ensures that alerts are triggered only when meaningful deviations occur.
Alerts can be categorized based on severity levels. Low-level alerts may indicate minor performance fluctuations, while high-severity alerts signal potential system failures or outages.
Modern systems often use multi-channel notifications. Alerts can be delivered through dashboards, emails, messaging platforms, or automated incident management systems.
In advanced setups, alerts can also trigger automated responses. For example, if network congestion exceeds a certain threshold, traffic can be rerouted automatically to maintain performance stability.
Defining Thresholds Through Historical Performance Analysis
Thresholds are essential for determining when network behavior should be considered normal or abnormal. They act as reference boundaries for performance metrics.
Setting thresholds requires a deep understanding of historical network behavior. Data collected over time is analyzed to identify typical performance ranges under different conditions.
These ranges help define acceptable limits for metrics such as latency, throughput, and error rates. Once thresholds are established, they serve as triggers for monitoring systems.
However, thresholds are not static. As network conditions evolve, thresholds must also be adjusted to reflect new performance baselines.
Dynamic thresholding is increasingly used in modern systems. Instead of relying on fixed values, dynamic thresholds adapt based on real-time trends and historical variations.
This approach reduces false positives and ensures that alerts remain relevant even in changing network environments.
Threshold modeling also considers external factors such as time of day, user load, and application behavior. These contextual elements help refine alert accuracy.
Network Performance Optimization Using Analytical Feedback
Monitoring systems are not only designed to detect problems but also to guide optimization efforts. Performance data provides valuable feedback that can be used to improve network efficiency.
Optimization begins by identifying bottlenecks within the system. These bottlenecks may occur in bandwidth usage, routing efficiency, or hardware limitations.
Once identified, corrective actions can be taken to redistribute traffic, upgrade infrastructure, or adjust configurations.
Latency optimization is another important area. By analyzing delay patterns, network paths can be adjusted to minimize response times and improve user experience.
Throughput optimization focuses on maximizing data transfer efficiency without overloading network resources. This often involves balancing traffic loads across multiple paths.
Optimization is an ongoing process rather than a one-time task. As network demands change, continuous adjustments are required to maintain optimal performance.
Role of Predictive Analytics in Network Monitoring
Predictive analytics has become a powerful extension of traditional network monitoring. Instead of only reacting to current conditions, predictive systems analyze historical data to forecast future behavior.
This approach enables proactive decision-making. For example, if traffic patterns indicate a potential overload in the near future, capacity adjustments can be made in advance.
Predictive models rely on machine learning algorithms that analyze trends across multiple metrics. These models identify correlations between variables that may not be immediately obvious.
Over time, predictive accuracy improves as more data becomes available. This allows systems to anticipate issues such as congestion, hardware failure, or performance degradation.
Predictive analytics also supports capacity planning. By forecasting future demand, organizations can allocate resources more effectively and avoid unexpected performance issues.
Managing Network Data at Scale in Distributed Systems
In distributed environments, network data is generated across multiple locations, devices, and cloud platforms. Managing this data at scale requires efficient aggregation and processing strategies.
Data aggregation involves collecting information from multiple sources and combining it into a unified view. This helps eliminate fragmentation and ensures consistency in analysis.
Distributed systems often rely on hierarchical data collection models. Local sensors collect data and send it to regional aggregation points, which then forward it to centralized analytics platforms.
This layered approach reduces bandwidth consumption and improves processing efficiency.
Data compression techniques are also used to optimize storage and transmission. Since telemetry data can be extremely large, compression helps reduce infrastructure costs.
Scalability is achieved through horizontal expansion, where additional processing nodes are added as data volume increases.
Security Implications of Performance Monitoring Systems
While monitoring systems improve visibility, they also introduce new security considerations. Performance data can reveal sensitive information about network structure and behavior.
Unauthorized access to monitoring systems can expose vulnerabilities or provide attackers with insights into network architecture.
To prevent this, strict access controls must be implemented. Only authorized personnel should have access to performance dashboards and raw telemetry data.
Encryption is also essential for protecting data during transmission. Since sensors often communicate across multiple network segments, securing data in transit reduces the risk of interception.
Another concern is sensor integrity. If sensors are compromised, they can provide inaccurate data, leading to incorrect decisions or missed threats.
Regular audits and validation processes help ensure that monitoring systems remain secure and trustworthy.
Integration of Monitoring Tools Across Hybrid Environments
Modern IT infrastructures often combine on-premises systems with cloud-based environments. This creates a hybrid architecture that requires integrated monitoring solutions.
Integration ensures that performance metrics from different environments are visible within a single framework. Without integration, data remains fragmented and difficult to interpret.
Hybrid monitoring systems must support multiple protocols, data formats, and communication channels.
Cloud environments often provide built-in monitoring tools, but these must be combined with on-premises systems to achieve complete visibility.
Standardized APIs and data connectors play a key role in enabling seamless integration between different monitoring platforms.
By unifying data sources, organizations gain a consistent view of performance across their entire infrastructure.
Understanding Network Behavior Through Correlation Analysis
Correlation analysis is a powerful technique used to identify relationships between different performance metrics. Instead of analyzing metrics in isolation, correlation analysis examines how they interact with each other.
For example, an increase in latency may correlate with higher bandwidth utilization. Identifying this relationship helps pinpoint underlying causes more accurately.
Correlation analysis also helps distinguish between symptoms and root causes. A single metric may indicate a problem, but correlated metrics reveal the source of that problem.
This approach improves diagnostic accuracy and reduces the time required to resolve network issues.
Over time, correlation patterns help build a deeper understanding of network behavior under different conditions.
Evolution of Monitoring Systems in Cloud-Driven Networks
Cloud computing has significantly changed how network monitoring systems are designed and deployed. Traditional monitoring models were built for static environments, while cloud-based systems require dynamic adaptability.
Cloud networks are highly elastic, meaning resources can scale up or down based on demand. Monitoring systems must adapt to these changes in real time.
This requires continuous discovery of new resources and automatic integration into monitoring frameworks.
Cloud environments also introduce multi-tenant architectures, where multiple users share infrastructure. Monitoring systems must ensure data isolation while maintaining visibility.
As cloud adoption continues to grow, monitoring systems are evolving toward fully distributed, API-driven architectures capable of handling dynamic workloads.
Advanced Sensor Intelligence in Modern Network Environments
As network infrastructures evolve, sensors are no longer just passive data collectors. They are becoming intelligent components capable of interpreting network behavior at the edge, reducing dependency on centralized processing, and enabling faster decision-making. This shift toward intelligent sensing is transforming how performance metrics are generated, interpreted, and acted upon.
Modern sensor systems are designed to operate in highly dynamic environments where traffic patterns change rapidly. Instead of simply capturing raw packets or logs, advanced sensors can pre-process data, detect anomalies locally, and even trigger automated responses without waiting for centralized systems.
This distributed intelligence is especially important in large-scale environments where latency between data collection and analysis can impact response times. By moving part of the analytical workload closer to the data source, networks become more responsive and resilient.
Intelligent sensors also help reduce data overload. Instead of sending every piece of raw telemetry to central systems, they can filter, compress, and prioritize information based on relevance. This ensures that only meaningful data is transmitted, improving efficiency across the monitoring architecture.
Over time, these sensors can adapt to network behavior. By learning typical traffic patterns, they become more accurate in distinguishing between normal fluctuations and true anomalies. This adaptive capability represents a significant advancement in network observability.
Machine Learning Applications in Performance Metrics Analysis
Machine learning has introduced a new dimension to network performance analysis by enabling systems to identify patterns that are too complex for traditional rule-based monitoring. Instead of relying solely on predefined thresholds, machine learning models analyze historical and real-time data to detect subtle correlations.
These models can process large volumes of metrics simultaneously, including latency, jitter, packet loss, throughput, and error rates. By analyzing relationships between these variables, machine learning systems can detect early warning signs of network degradation.
One of the most powerful applications of machine learning in this context is anomaly detection. Instead of waiting for metrics to exceed fixed thresholds, algorithms can identify behavior that deviates from normal patterns, even if the deviation is small.
This approach significantly improves early detection of performance issues. For example, a gradual increase in latency combined with a slight drop in throughput might not trigger traditional alerts, but a machine learning model can recognize it as a potential failure pattern.
Predictive modeling is another key application. By analyzing historical trends, machine learning systems can forecast future network behavior. This allows IT teams to anticipate congestion, capacity shortages, or hardware failures before they occur.
As these systems continue to learn, their accuracy improves. This makes them increasingly valuable in complex environments where static rules are insufficient for effective monitoring.
Deep Packet Analysis and Its Role in Network Visibility
Deep packet analysis plays a critical role in modern network monitoring by providing granular visibility into data flows. Unlike high-level metrics that summarize performance, packet-level analysis examines the actual contents and structure of network traffic.
This level of inspection allows administrators to understand not just how much data is being transmitted, but what type of data is flowing through the network. It can reveal application behavior, protocol usage, and even user interaction patterns.
Deep packet analysis helps identify performance issues that may not be visible through traditional metrics. For example, a network may appear to be operating normally based on throughput and latency, but packet-level inspection may reveal retransmissions or malformed data causing hidden inefficiencies.
It is also valuable for troubleshooting complex issues involving multiple systems. By tracing packet paths across the network, administrators can identify where delays or failures occur.
However, deep packet analysis generates large volumes of data, making it resource-intensive. To manage this, it is often combined with filtering techniques that focus only on relevant traffic segments.
When integrated with performance metrics and sensors, deep packet analysis adds a critical layer of contextual understanding that enhances overall network observability.
Real-Time Event Correlation Across Distributed Networks
In complex environments, network events rarely occur in isolation. A single performance issue may trigger a chain of related events across multiple systems. Event correlation helps identify these relationships and provides a unified view of network behavior.
Real-time event correlation systems collect data from multiple sensors and monitoring tools, then analyze it to identify connections between seemingly unrelated events.
For example, a spike in CPU usage on a server may correlate with increased latency in network traffic and higher error rates in application responses. By correlating these events, the system can identify the root cause more effectively.
Without correlation, each event would be treated separately, making troubleshooting more time-consuming and less accurate.
Modern correlation engines use time-based alignment, dependency mapping, and behavioral analysis to connect related events. This allows them to reconstruct the sequence of occurrences that led to a performance issue.
Event correlation also reduces alert fatigue by grouping related alerts into a single incident. Instead of receiving multiple notifications for the same underlying problem, administrators receive a consolidated view.
This improves operational efficiency and allows teams to focus on resolving root causes rather than individual symptoms.
Optimizing Network Traffic Through Intelligent Load Balancing
Traffic optimization is a key aspect of maintaining network efficiency, especially in environments with high and variable demand. Load balancing distributes network traffic across multiple paths, devices, or servers to prevent overload and ensure consistent performance.
Intelligent load balancing systems use real-time performance metrics to make dynamic routing decisions. Instead of relying on static configurations, they continuously evaluate network conditions and adjust traffic flow accordingly.
For example, if one server becomes overloaded, traffic can be automatically redirected to another server with lower utilization. This helps maintain application responsiveness and prevents bottlenecks.
Load balancing also improves redundancy. If a network path fails, traffic can be rerouted through alternative paths without disrupting service.
Advanced systems take multiple metrics into account when making decisions. These may include latency, bandwidth availability, error rates, and server health indicators.
By combining these factors, load balancing systems ensure that traffic is distributed in a way that maximizes performance and minimizes risk.
The Role of Edge Computing in Performance Monitoring
Edge computing has become increasingly important in modern network architectures. Instead of sending all data to centralized cloud systems, edge computing processes data closer to its source.
This approach significantly reduces latency and improves response times. In performance monitoring, edge computing allows sensors and devices to analyze data locally before transmitting it.
By processing data at the edge, networks reduce the volume of information sent to central systems. This improves efficiency and reduces bandwidth consumption.
Edge-based monitoring also enables faster detection of anomalies. Since data does not need to travel long distances for analysis, issues can be identified and addressed more quickly.
In distributed environments such as IoT networks, edge computing plays a critical role in maintaining scalability. With thousands or millions of connected devices, centralized processing alone would be insufficient.
Edge-based performance metrics allow each device or node to contribute to the overall monitoring system without overwhelming central infrastructure.
Network Resilience and Fault Tolerance Strategies
Network resilience refers to the ability of a system to maintain functionality despite failures or disruptions. Fault tolerance is closely related and focuses on the system’s ability to continue operating even when components fail.
Performance metrics and sensors play a key role in building resilient networks by providing early detection of potential failures.
Resilience strategies often include redundancy, failover mechanisms, and adaptive routing. These systems ensure that if one component fails, another can take over without interrupting service.
Sensors continuously monitor system health to detect early signs of failure, such as increasing error rates, hardware degradation, or traffic anomalies.
When combined with automated response systems, fault detection can trigger immediate corrective actions. This may include rerouting traffic, restarting services, or activating backup systems.
Resilient networks are designed not only to recover from failures but also to prevent them whenever possible. Continuous monitoring ensures that small issues are identified before they escalate into major outages.
Capacity Planning Using Long-Term Performance Data
Capacity planning is the process of ensuring that network resources are sufficient to meet future demand. It relies heavily on historical performance data collected through metrics and sensors.
By analyzing long-term trends, organizations can predict when additional bandwidth, storage, or computing resources will be required.
Capacity planning helps prevent performance degradation caused by resource exhaustion. Without proper planning, networks may become overloaded during peak usage periods.
Performance metrics such as bandwidth utilization, transaction rates, and latency trends provide valuable input for forecasting models.
These models help organizations make informed decisions about infrastructure upgrades and resource allocation.
Capacity planning is not only about scaling up resources but also about optimizing existing infrastructure. In many cases, inefficiencies can be resolved through better traffic distribution or configuration adjustments.
User Experience as a Performance Indicator
While technical metrics provide detailed insights into network behavior, user experience remains one of the most important indicators of overall performance.
User experience metrics focus on how real users perceive network performance. This includes application responsiveness, loading times, and interaction delays.
Even if technical metrics appear stable, poor user experience can indicate underlying issues that are not immediately visible in system-level data.
For example, high latency in a specific geographic region may affect users in that area even if global network performance appears normal.
By incorporating user experience data into performance monitoring, organizations gain a more complete understanding of system effectiveness.
This approach ensures that optimization efforts are aligned with actual user needs rather than purely technical benchmarks.
Continuous Improvement Through Performance Feedback Loops
Network optimization is not a one-time activity but a continuous process driven by feedback loops. Performance metrics and sensor data provide the foundation for these iterative improvements.
A feedback loop begins with data collection, followed by analysis, decision-making, and implementation of changes. The impact of these changes is then measured through updated metrics.
This cycle allows networks to evolve over time, adapting to new demands and conditions.
Continuous improvement ensures that performance remains aligned with business objectives and user expectations.
As networks become more complex, feedback loops become increasingly automated. Systems can now adjust configurations dynamically based on real-time performance data.
This level of automation reduces manual intervention and allows networks to self-optimize in many scenarios.
Emerging Trends in Network Performance Intelligence
The future of network performance monitoring is moving toward greater automation, intelligence, and integration. Traditional monitoring systems focused primarily on detection, while modern systems emphasize prediction and prevention.
Artificial intelligence, edge computing, and distributed analytics are reshaping how performance metrics are collected and interpreted.
There is also a growing shift toward unified observability platforms that integrate metrics, logs, and traces into a single framework.
This unified approach provides deeper insights into system behavior and simplifies troubleshooting.
Another emerging trend is the use of self-healing networks. These systems automatically detect issues and apply corrective actions without human intervention.
As networks continue to evolve, performance monitoring will become increasingly autonomous, adaptive, and predictive, enabling more resilient and efficient digital infrastructures.
Conclusion
Network performance metrics and sensors have become foundational elements in the way modern digital systems are designed, operated, and improved. In today’s highly connected environment, where businesses rely on cloud services, distributed applications, remote teams, and real-time communication platforms, network stability is no longer optional. It is a core requirement for operational continuity, user satisfaction, and long-term scalability.
Throughout the discussion, it becomes clear that performance metrics are not just technical measurements stored in dashboards. They are meaningful indicators of how effectively a network is functioning under real-world conditions. Metrics such as latency, throughput, packet loss, jitter, and uptime each represent a different dimension of network health. When combined, they create a complete picture of system behavior that allows organizations to move beyond guesswork and into data-driven decision-making.
However, metrics alone cannot deliver value without a mechanism for data collection. This is where sensors play a crucial role. They act as the foundation of visibility, continuously gathering information from across the network infrastructure. Whether through active testing or passive observation, sensors ensure that performance data is always up to date and reflective of real conditions. Without them, metrics would be theoretical rather than actionable.
The integration of sensors and metrics forms a continuous feedback system. Data is collected, processed, analyzed, and then transformed into insights that guide operational decisions. This cycle enables organizations to detect problems early, understand their root causes, and implement solutions before users are significantly affected. It also supports proactive management, where potential issues are addressed before they escalate into outages or performance degradation.
One of the most important outcomes of this system is improved visibility. Modern networks are complex, often spanning multiple environments such as on-premises infrastructure, cloud platforms, and edge devices. Without comprehensive monitoring, these environments can become fragmented and difficult to manage. Performance metrics and sensors unify this complexity by providing a centralized understanding of network behavior.
Another key benefit is predictability. By analyzing historical data, organizations can identify trends and forecast future performance needs. This allows for better capacity planning, ensuring that resources are allocated efficiently and that networks are prepared for growth. Predictive insights also reduce the risk of unexpected failures, as early warning signs can be detected through subtle changes in performance patterns.
Equally important is the role of automation in modern monitoring systems. As networks scale, manual oversight becomes impractical. Automated alerting, dynamic thresholding, and self-adjusting systems help ensure that performance issues are addressed quickly and consistently. In more advanced environments, automation can even trigger corrective actions without human intervention, such as rerouting traffic or reallocating resources.
Despite these advantages, implementing performance monitoring systems is not without challenges. Scalability, data management, security, and integration complexity all require careful planning. Large volumes of telemetry data must be processed efficiently, stored securely, and analyzed intelligently. At the same time, monitoring systems must remain flexible enough to adapt to evolving network architectures and emerging technologies.
Security is another critical consideration. Since performance data often reflects internal network structure and behavior, it must be protected from unauthorized access. Proper encryption, access control, and system hardening are essential to ensure that monitoring tools do not introduce new vulnerabilities into the environment they are designed to protect.
As technology continues to evolve, network performance monitoring is also undergoing significant transformation. The rise of cloud computing, edge processing, and artificial intelligence is reshaping how data is collected and analyzed. Monitoring systems are becoming more intelligent, more distributed, and more autonomous. Instead of simply reporting problems, they are increasingly capable of predicting and preventing them.
In this evolving landscape, organizations that invest in strong performance monitoring strategies gain a significant advantage. They achieve higher reliability, better user experiences, and more efficient use of infrastructure resources. More importantly, they develop the ability to respond to change quickly, which is essential in a digital world where demands can shift rapidly.
Ultimately, performance metrics and sensors are not just technical tools. They represent a strategic capability that enables organizations to maintain control, visibility, and resilience across their entire network environment.