To understand persistent volume claims in Kubernetes, it helps to first understand the environment they are designed for. Kubernetes is built around the idea of running applications in small, isolated units called pods. Each pod contains one or more containers that work together to perform a specific function, such as serving a website, processing data, or handling API requests.
What makes pods unique is not just their structure, but their behavior. They are intentionally designed to be temporary. A pod can be created, moved, replaced, or deleted at any moment depending on the needs of the system. If a server becomes overloaded, Kubernetes may move pods elsewhere. If an application needs updating, old pods may be destroyed and replaced with new versions. If a failure occurs, the system may recreate pods automatically to maintain stability.
This dynamic nature is what makes Kubernetes powerful for modern cloud environments. However, it also introduces a fundamental challenge. If everything inside a pod is temporary, then anything stored inside it is also temporary. That creates a problem when applications need to store important data.
Many real-world applications cannot function without retaining information. A shopping application must remember orders. A messaging system must preserve conversations. A data analytics service must store processed results. If all of this information disappears whenever a pod is restarted, the application would lose continuity entirely.
This tension between temporary compute and permanent data is the foundation of why Kubernetes storage mechanisms exist.
Why Ephemeral Infrastructure Creates a Storage Challenge
The idea of ephemeral infrastructure means that compute resources are treated as disposable. Instead of carefully maintaining a single long-running machine, Kubernetes treats every pod as replaceable. This approach brings several advantages such as scalability, resilience, and easier deployment management.
However, it also introduces a critical limitation: anything stored directly inside a pod is tied to its lifecycle. If the pod disappears, so does the data stored within it. This is not an accidental flaw but a deliberate design choice. By making pods stateless, Kubernetes ensures that workloads remain flexible and can be redistributed without concern for internal state.
But applications are rarely stateless in practice. Even simple web applications require session data, user profiles, logs, and configuration states. More complex systems require databases, file storage, and long-term record keeping. These requirements cannot be satisfied by ephemeral storage alone.
This is where external storage becomes necessary. Instead of storing data inside the pod, Kubernetes separates storage from compute. The idea is to allow data to exist independently of any individual pod so that it can persist even when workloads change.
This separation introduces a new model where storage is treated as its own independent resource rather than something tied directly to the application container.
Introducing the Concept of Persistent Storage in Kubernetes
Persistent storage in Kubernetes refers to storage that exists independently of any single pod. Unlike the temporary storage inside a container, persistent storage continues to exist even if all associated pods are deleted or replaced.
This allows applications to safely store data without worrying about the lifecycle of their compute environment. Whether a pod is restarted, rescheduled, or completely replaced, the data remains available.
The key idea is decoupling. Compute and storage are no longer tightly connected. Instead, storage becomes a separate resource that can be used by different workloads over time.
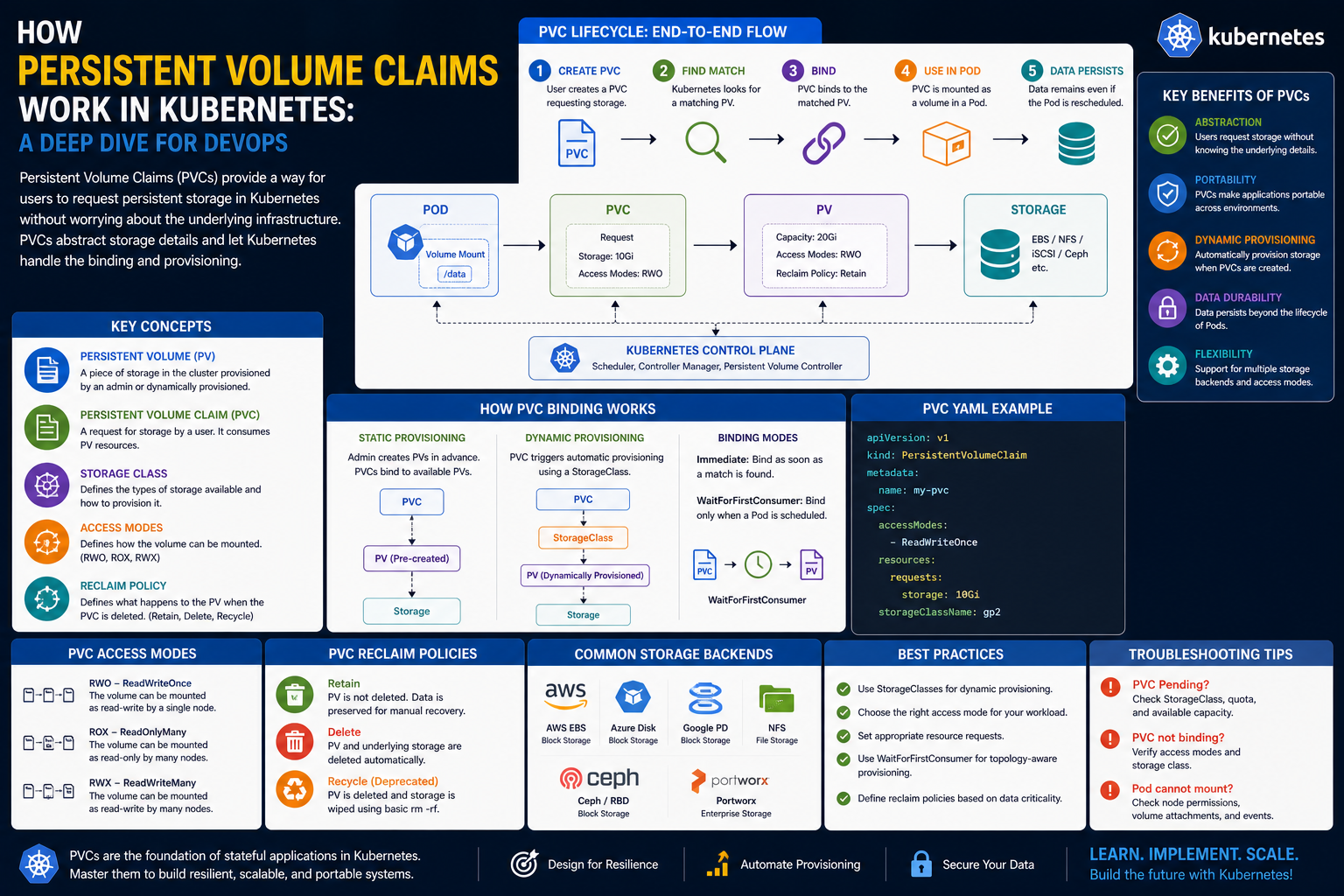
However, Kubernetes does not allow pods to directly manage this storage. Instead, it introduces a structured system where storage is abstracted and controlled through intermediate objects. This is where persistent volumes and persistent volume claims come into play.
These two components form the backbone of Kubernetes storage architecture. One represents the actual storage resource, while the other represents a request for that storage.
Understanding the Role of Persistent Volumes
A persistent volume is a storage resource that exists within the Kubernetes environment. It represents a piece of storage that has been provisioned and made available for use. This storage could come from a cloud provider, a local disk, or a network-based storage system.
The important characteristic of a persistent volume is that it is not tied to any specific pod. It exists independently, waiting to be used by workloads that require storage.
Think of it as a pool of storage capacity. This pool can be divided and assigned to different applications based on their needs. It may be large or small, fast or slow, but its defining feature is independence from individual applications.
A persistent volume does not decide how it is used. Instead, it simply represents available storage that can be consumed when needed. It is a passive resource waiting for requests.
This separation of storage creation from storage usage is essential for flexibility. It allows infrastructure teams to define storage resources ahead of time without knowing exactly which applications will use them.
Why Applications Cannot Directly Use Persistent Volumes
Even though persistent volumes represent real storage, applications do not directly attach to them. This might seem unnecessary at first, but it plays an important role in maintaining abstraction and flexibility.
If applications directly accessed storage resources, they would need to know details about where and how the storage is configured. This would tightly couple applications to infrastructure, making systems harder to manage and scale.
Instead, Kubernetes introduces an intermediary layer. Applications do not request storage directly. Instead, they make a claim for storage based on their requirements.
This abstraction ensures that applications only express what they need, not how it should be fulfilled. They might request a certain amount of space or a certain type of access, but they do not need to know which actual storage resource is assigned to them.
This design makes Kubernetes much more flexible. Storage can be changed, replaced, or reconfigured without affecting the application itself.
The Purpose of Persistent Volume Claims
A persistent volume claim acts as a request for storage. It is how an application expresses its storage needs to the Kubernetes system.
Instead of interacting directly with a storage resource, an application creates a claim describing what it requires. This might include the amount of storage needed, the type of access required, or the way the storage should behave.
Once a claim is made, Kubernetes looks for a suitable persistent volume that matches those requirements. If a match is found, the claim is linked to that volume, and the application can begin using it.
This process is often compared to a reservation system. The persistent volume is like available capacity, while the claim is like a reservation request. The system matches the request to an available resource.
What makes this approach powerful is that it separates intention from implementation. The application does not need to know how storage is provided. It only needs to specify what it needs.
How Claims Bridge Applications and Storage Resources
The relationship between persistent volumes and persistent volume claims forms a bridge between applications and storage infrastructure.
On one side, applications run inside pods and require data persistence. On the other side, storage systems provide raw capacity. The persistent volume claim sits in the middle, translating application needs into storage allocation decisions.
When a claim is created, it describes the requirements of the application. Kubernetes then evaluates available storage resources and finds one that satisfies those requirements. Once a match is found, the claim is bound to that volume.
After binding, the application can use the storage as if it were part of its own environment, even though the storage exists independently.
This separation allows storage to be managed centrally while still being used dynamically by applications. It also enables multiple applications to use different storage resources without interfering with each other.
The Relationship Between Pods, Claims, and Volumes
The interaction between pods, persistent volume claims, and persistent volumes forms a three-layer system.
At the top level, the pod represents the running application. It needs storage to function but does not manage storage directly.
In the middle, the persistent volume claim represents the application’s request for storage. It defines what is needed without specifying how it will be fulfilled.
At the bottom, the persistent volume represents the actual storage resource. It provides the physical or virtual capacity that will be used by the application.
The pod uses the claim, and the claim uses the volume. This indirect relationship is what allows Kubernetes to maintain flexibility and scalability.
If a pod is removed, the claim may still exist. If the claim is removed, the volume may still remain available for future use. This separation ensures that storage is not tightly bound to application lifecycle events.
Storage Independence and Application Flexibility
One of the most important outcomes of this architecture is storage independence. Applications can come and go without affecting the underlying data. This means that even if an application is completely rebuilt or redeployed, its data can remain intact.
This is particularly important in environments where applications are frequently updated or scaled. Instead of worrying about data loss during deployment changes, developers can rely on persistent storage to maintain continuity.
It also allows workloads to move between different nodes or even different environments without losing access to their data. As long as the persistent volume remains available, the data can be reused.
This flexibility is a key reason why Kubernetes is widely used for cloud-native applications. It supports both dynamic compute and stable storage in a unified system.
How Storage Requests Shape Resource Allocation
When a persistent volume claim is created, it includes specific requirements. These requirements influence how Kubernetes selects a suitable volume.
One of the most important requirements is storage capacity. An application might request a certain amount of space based on its expected usage. Kubernetes then looks for a volume that can satisfy that requirement.
Another important factor is access mode, which defines how the storage can be used. Some storage may be shared across multiple pods, while other storage may only be used by one at a time.
By evaluating these requirements, Kubernetes ensures that storage is allocated in a controlled and predictable manner. This prevents conflicts and ensures that applications receive appropriate resources.
The matching process is automatic, but it is guided by the specifications provided in the claim. This allows developers to focus on application needs rather than infrastructure details.
The Separation of Concerns in Kubernetes Storage Design
The design of persistent volumes and persistent volume claims reflects a broader principle in Kubernetes architecture: separation of concerns.
Instead of combining compute, storage, and application logic into a single system, Kubernetes separates them into distinct layers. Pods handle compute, persistent volumes handle storage, and claims handle coordination between the two.
This separation improves scalability because each layer can evolve independently. Storage systems can be upgraded without affecting applications. Applications can be redeployed without changing storage infrastructure.
It also improves reliability because failures in one layer do not necessarily impact others. If a pod fails, storage remains unaffected. If storage is modified, applications can continue running without interruption.
This modular approach is one of the reasons Kubernetes is considered a highly adaptable system for modern distributed computing environments.
Moving From Concept to Interaction Between Components
In the first part, the idea of separating compute from storage was introduced, along with the roles of pods, persistent volumes, and persistent volume claims. To understand Kubernetes storage more deeply, it is important to move beyond definitions and focus on how these components actually interact in a running system.
At the heart of this interaction is a process called binding. Binding is what connects a storage request (the claim) to an actual storage resource (the volume). Without binding, a claim is simply a request waiting to be fulfilled, and a volume is just unused capacity. Binding turns these two independent objects into a working relationship that applications can use.
This process is not random. It follows a structured evaluation system where Kubernetes continuously checks whether available storage can satisfy pending requests. Once a match is found, the relationship becomes fixed unless explicitly changed.
This mechanism is what allows Kubernetes to scale storage usage dynamically while still maintaining control over how resources are allocated.
How Kubernetes Evaluates Storage Requests
When a persistent volume claim is created, Kubernetes does not immediately assign storage. Instead, it enters a matching process where the system compares the claim’s requirements against available persistent volumes.
Each claim contains a set of constraints. These constraints define what kind of storage is acceptable for the application. The most obvious constraint is capacity, but there are others that influence the decision-making process.
Kubernetes checks whether a volume has enough available space to satisfy the request. It also checks whether the volume supports the required access behavior. Some applications need exclusive access to storage, while others can share it across multiple instances.
Only when all requirements are satisfied does Kubernetes consider a volume eligible for binding. This ensures that applications receive storage that matches their needs without manual intervention.
If no suitable volume is found, the claim remains unbound. In this state, the application that created the claim may not function correctly, depending on whether it can tolerate missing storage.
The Binding Process and Its Implications
Once a suitable match is found, Kubernetes binds the persistent volume claim to a persistent volume. This binding is a one-to-one relationship, meaning that each claim is connected to exactly one volume, and that volume is reserved for that claim.
This exclusivity is important because it prevents multiple applications from unintentionally overwriting each other’s data. Once a volume is bound, it is no longer available for other claims unless explicitly released.
The binding process effectively locks the relationship in place. Even if a better match becomes available later, Kubernetes does not automatically switch bindings. This stability ensures that applications do not experience unexpected changes in storage behavior.
However, this also means that storage planning becomes important. If resources are not managed carefully, some volumes may remain unused while others are overutilized.
The Role of Storage Classes in Dynamic Allocation
In more advanced Kubernetes environments, storage is not always manually created before use. Instead, storage can be dynamically provisioned when a claim is made.
This is made possible through storage classes, which define templates for how storage should be created. A storage class describes characteristics such as performance level, replication strategy, and backend storage type.
When a persistent volume claim is created that references a storage class, Kubernetes can automatically generate a matching persistent volume. This eliminates the need for pre-created storage resources.
This dynamic provisioning model makes storage management more scalable. Instead of manually preparing storage in advance, infrastructure can respond automatically to application needs.
The storage class acts as a blueprint, while the persistent volume claim acts as a trigger. When both align, Kubernetes creates the necessary storage resource on demand.
How Persistent Volumes Are Provisioned Automatically
When dynamic provisioning is enabled, the lifecycle of a persistent volume changes. Instead of existing before a claim, the volume is created in response to the claim.
The process begins when a persistent volume claim is submitted with a storage class reference. Kubernetes identifies the storage class and determines how the volume should be created.
Based on the configuration, a new storage resource is provisioned from the underlying infrastructure. This could be cloud storage, network storage, or local disk resources depending on the environment.
Once the volume is created, it is immediately bound to the claim that triggered its creation. This creates a direct relationship between application demand and storage provisioning.
This model reduces manual work and ensures that storage is allocated efficiently based on real-time demand rather than preallocated assumptions.
Understanding Volume Lifecycle States
Persistent volumes and claims do not remain static throughout their existence. They go through different lifecycle states depending on their relationship and usage.
A volume may be in an available state when it is not yet bound to any claim. In this state, it is ready to be used but not actively assigned.
Once a claim is matched, the volume transitions into a bound state. This indicates that it is actively associated with a specific claim and is reserved for that purpose.
When a claim is removed, the volume does not necessarily disappear. Instead, its behavior depends on its configured retention policy. It may remain available, be deleted, or be retained for manual reuse.
These lifecycle states ensure that storage behaves predictably across different application scenarios while still allowing flexibility for infrastructure management.
The Importance of Retention Policies in Storage Management
Retention policies define what happens to a persistent volume after its associated claim is deleted. This is an important aspect of Kubernetes storage behavior because it determines whether data is preserved or removed.
There are generally three types of retention behavior. The first allows the volume to be retained after the claim is deleted. This means the data remains intact and can be reused later if needed.
The second allows the volume to be deleted automatically when the claim is removed. This is useful for temporary workloads where data does not need to persist beyond the application lifecycle.
The third allows the volume to be recycled, meaning it is cleaned and made available for future claims. This behavior depends on the configuration and storage backend capabilities.
These policies give administrators control over how storage should behave after application termination, balancing between data persistence and resource efficiency.
How Pods Connect to Persistent Volume Claims
While persistent volumes and claims handle storage allocation, pods are responsible for using that storage. The connection between a pod and storage is made through the claim.
When a pod is defined, it does not directly reference a persistent volume. Instead, it references a persistent volume claim. This ensures that the pod remains decoupled from the actual storage implementation.
Inside the pod configuration, the claim is mounted to a specific directory within the container. This allows the application running inside the container to read and write data as if it were working with a local file system.
From the perspective of the application, there is no difference between temporary and persistent storage. The abstraction provided by Kubernetes ensures that storage behaves consistently regardless of where it physically resides.
Mounting Storage Into Containers
When a pod starts, Kubernetes ensures that the persistent volume associated with the claim is made available to the container. This process is known as mounting.
Mounting connects the external storage resource to a directory inside the container’s file system. Once mounted, the application can interact with the storage using normal file operations.
This abstraction is powerful because it hides all infrastructure complexity from the application. The application does not need to know whether the storage is local, network-based, or cloud-hosted.
It simply interacts with a file path, while Kubernetes handles all underlying communication with the storage system.
The Separation Between Volume Provisioning and Usage
One of the most important design principles in Kubernetes storage is the separation between provisioning and usage.
Provisioning refers to the creation and allocation of storage resources. This is handled by persistent volumes and storage classes.
Usage refers to how applications interact with storage once it has been allocated. This is handled by persistent volume claims and pods.
By separating these responsibilities, Kubernetes ensures that infrastructure and application layers remain independent. Storage can be scaled, upgraded, or replaced without affecting application logic.
Similarly, applications can be deployed or updated without requiring changes to storage infrastructure.
Handling Multiple Pods and Shared Storage Access
In some cases, multiple pods may need to access the same storage resource. Kubernetes supports this through access modes defined in persistent volume claims.
Some volumes allow single-pod access, meaning only one pod can use the storage at a time. This is useful for databases or applications that require exclusive file access.
Other volumes allow shared access, where multiple pods can read or write to the same storage simultaneously. This is useful for distributed applications or shared file systems.
The access mode ensures that storage behavior aligns with application requirements. Kubernetes enforces these rules during binding to prevent conflicts.
The Role of Resource Requests in Storage Allocation
When a persistent volume claim is created, it specifies how much storage is required. This request plays a critical role in determining which volume will be assigned.
If the request is too large, it may not find a matching volume. If it is too small, it may not fully utilize available resources.
This system encourages efficient storage usage by ensuring that resources are allocated based on actual needs rather than arbitrary assignments.
It also allows infrastructure teams to plan storage capacity more effectively by understanding how applications consume resources over time.
Dynamic Behavior of Storage in Scaling Environments
One of the most powerful aspects of Kubernetes storage is its ability to adapt to scaling environments. As applications grow or shrink, storage needs may change.
When new replicas of a pod are created, they may require additional storage. Kubernetes can respond by creating new claims or binding existing ones depending on configuration.
When workloads are reduced, storage may become available again for other applications.
This dynamic behavior ensures that storage is not wasted and can be efficiently shared across multiple workloads.
Interaction Between Storage and Fault Tolerance
Kubernetes is designed to operate in environments where failures are expected. Nodes may go down, pods may crash, and network interruptions may occur.
Persistent storage plays a critical role in ensuring that data remains safe during these failures. Because storage exists independently of pods, it is not affected when a pod fails.
When a failed pod is recreated, it can reattach to the same persistent volume claim and continue using the same data.
This ability to recover state is essential for maintaining application reliability in distributed systems.
The Ongoing Relationship Between Claims and Volumes
Once a claim is bound to a volume, the relationship continues until it is explicitly changed or removed. This relationship ensures consistency in how storage is used over time.
Even if the pod using the storage is deleted, the claim and volume may remain intact. This allows data to persist beyond individual application lifecycles.
This ongoing relationship is what gives Kubernetes storage its durability and flexibility in long-running systems.
From Basic Storage to Real System Behavior
Once the foundational relationship between pods, persistent volume claims, and persistent volumes is understood, the next step is to examine how this system behaves in real production environments. In practice, storage in Kubernetes is not just about creating a claim and binding it to a volume. It involves planning for scaling, handling failures, managing data consistency, and designing systems that remain stable under constant change.
In real-world clusters, storage becomes part of the application architecture rather than a simple backend detail. Applications depend on it for correctness, resilience, and continuity. This makes understanding advanced storage behavior essential for building reliable systems.
At this level, Kubernetes storage is no longer just a mechanism for saving files. It becomes a coordination layer between infrastructure and application lifecycle management.
Stateful Applications and Why They Change the Storage Model
Most modern applications running in Kubernetes are stateless by design. They can be replaced at any time without losing critical information because their state is stored externally. However, not all systems can follow this model.
Stateful applications require persistent identity and consistent storage over time. Examples include databases, message queues, analytics engines, and systems that maintain long-term user data.
These applications introduce complexity because they cannot simply be restarted or replaced without careful handling of their stored data. A database, for example, must ensure that its storage remains consistent even if the underlying pod changes.
Persistent volume claims provide the foundation for this stability by ensuring that storage remains attached to a logical identity rather than a physical pod instance. Even if the pod is deleted and recreated, the claim remains, preserving the link to the same underlying data.
This separation allows Kubernetes to support stateful workloads without sacrificing its core design principle of ephemeral compute.
Identity Persistence Through Storage Binding
One of the most important concepts in stateful workloads is identity persistence. While pods are temporary, the data they use must remain consistent across restarts.
Persistent volume claims act as the anchor for this identity. Instead of binding storage to a specific pod, Kubernetes binds storage to a claim, which can outlive individual pods.
This means that even if a pod is destroyed and replaced, the claim ensures that it reconnects to the same storage resource. The application continues operating as if nothing changed.
This model is particularly important in systems where data consistency is critical. If storage were tied directly to pods, any restart could lead to data fragmentation or loss.
By decoupling identity from compute, Kubernetes ensures that applications can maintain continuity even in highly dynamic environments.
Reattachment of Storage After Failures
Failures are expected in distributed systems. Nodes crash, networks fail, and workloads are rescheduled. Kubernetes is designed to handle these disruptions automatically.
When a pod fails, Kubernetes may recreate it on a different node. In this process, the persistent volume claim remains unchanged. The new pod references the same claim, which points to the same storage resource.
This allows the application to resume exactly where it left off. The storage remains intact, and the data continues to be available.
This reattachment process is critical for maintaining reliability. Without it, every failure would result in data loss or corruption.
The ability to detach and reattach storage dynamically is one of the key reasons Kubernetes is widely used for modern distributed systems.
Multi-Pod Access and Shared Storage Behavior
While many applications require exclusive access to storage, some workloads benefit from shared storage access across multiple pods.
In such cases, Kubernetes allows multiple pods to use the same persistent volume claim, depending on the access mode of the underlying volume.
Shared storage is commonly used in scenarios where multiple application instances need to read the same data. For example, web servers serving static content or distributed processing systems reading shared datasets.
However, shared access introduces challenges related to concurrency. When multiple pods write to the same storage simultaneously, coordination becomes necessary to prevent data corruption.
Kubernetes itself does not manage data consistency at the application level. It only ensures that access rules are enforced. The responsibility for safe concurrent access remains with the application.
This separation allows Kubernetes to remain flexible while supporting a wide range of storage use cases.
Data Consistency and Application Responsibility
One of the most important aspects of Kubernetes storage is that it provides infrastructure-level guarantees, not application-level consistency.
Persistent volumes ensure that storage remains available and stable. Persistent volume claims ensure that access is properly allocated. However, they do not manage how data is written or structured.
This means that applications must handle their own consistency logic. Databases, for example, implement their own transaction systems to ensure correctness.
In distributed systems, this becomes even more important. Multiple pods may interact with the same storage, but Kubernetes does not coordinate those interactions at the data level.
This design decision keeps the system flexible and lightweight, but it also places responsibility on application developers to design safe storage interactions.
Scaling Applications and Storage Implications
Scaling is one of the core features of Kubernetes. Applications can be scaled up or down depending on demand. However, scaling also affects storage behavior.
When new pods are created during scaling, they may require access to existing storage or new storage resources depending on the application design.
If multiple pods share the same persistent volume claim, they all access the same underlying storage. This is common for stateless services that share configuration or static data.
If each pod requires its own storage, Kubernetes may create separate claims for each instance. This is often seen in stateful systems where each replica maintains its own dataset.
The relationship between scaling and storage must be carefully designed. Incorrect configuration can lead to performance bottlenecks or data conflicts.
Storage Performance Considerations in Distributed Systems
Storage performance is a critical factor in application behavior. Different storage backends offer different levels of latency, throughput, and reliability.
Kubernetes itself does not define storage performance. Instead, it relies on the underlying infrastructure to provide the necessary characteristics.
Persistent volume claims can request storage based on size and access type, but performance depends on the storage class and backend system.
In high-performance applications, such as databases or analytics systems, storage latency can directly affect application responsiveness.
This makes storage selection an important architectural decision. Choosing the wrong storage backend can lead to bottlenecks that impact the entire system.
The Role of Storage Classes in Performance Optimization
Storage classes allow administrators to define different types of storage based on performance and behavior characteristics.
For example, one storage class may provide high-speed SSD-based storage, while another may provide slower but more cost-effective disk storage.
When a persistent volume claim references a specific storage class, Kubernetes provisions storage based on those characteristics.
This allows applications to choose storage based on their performance needs without manually configuring infrastructure.
It also enables hybrid environments where different applications use different storage types within the same cluster.
Data Migration Between Persistent Volumes
In some cases, storage needs to be moved from one volume to another. This may happen due to infrastructure upgrades, performance changes, or scaling requirements.
Kubernetes does not automatically migrate data between volumes. Instead, migration is handled through application-level or administrative processes.
The process typically involves creating a new persistent volume, updating the persistent volume claim, and transferring data manually or through application logic.
This ensures that storage migration remains controlled and predictable. Automatic migration could introduce risks of data inconsistency or corruption.
By requiring explicit action, Kubernetes maintains stability in storage behavior.
Backup Strategies in Persistent Storage Environments
Because persistent volumes store critical application data, backup strategies are essential.
Kubernetes does not provide built-in backup mechanisms at the storage level. Instead, backups are handled through external systems or application-level tools.
These backups may involve copying data from persistent volumes to external storage systems or snapshotting underlying storage resources.
Snapshots are particularly useful because they capture the state of a volume at a specific point in time without disrupting ongoing operations.
Backup strategies ensure that data can be recovered in case of failure, corruption, or accidental deletion.
Security Considerations in Persistent Storage Access
Storage security is an important aspect of Kubernetes environments. Since multiple applications may share infrastructure, controlling access to storage is critical.
Persistent volume claims ensure that only authorized pods can access specific storage resources. However, additional security layers are often required at the infrastructure level.
Encryption, access control policies, and network segmentation are commonly used to protect data stored in persistent volumes.
Security responsibilities are shared between Kubernetes and the underlying storage system. Kubernetes manages access relationships, while storage systems manage data protection.
This layered approach provides flexibility while maintaining security boundaries.
Storage Isolation Between Applications
In multi-tenant environments, multiple applications may run on the same Kubernetes cluster. Storage isolation ensures that each application only accesses its own data.
Persistent volume claims help enforce this isolation by binding storage to specific requests. Once bound, storage is not shared unless explicitly configured.
This prevents accidental data leakage between applications and ensures that each workload operates independently.
Isolation is a key requirement for secure and stable cluster operations.
Long-Term Storage Behavior in Evolving Clusters
Kubernetes clusters are not static environments. They evolve over time as nodes are added, removed, or upgraded.
Persistent storage must remain stable throughout these changes. Because persistent volumes exist independently of nodes, they are not affected by cluster scaling operations.
This ensures that data remains available even as infrastructure changes underneath it.
However, administrators must still ensure that storage systems remain compatible with evolving cluster configurations.
Designing Applications Around Persistent Storage
Modern application design often assumes that storage is external and persistent. This allows applications to be more modular and resilient.
Instead of embedding storage logic into the application itself, developers rely on persistent volume claims to provide consistent access to data.
This separation allows applications to focus on business logic while Kubernetes handles storage coordination.
It also enables applications to be deployed across different environments without modification, as long as storage configuration is preserved.
Behavioral Model of Kubernetes Storage
At a system level, Kubernetes storage behavior can be understood as a continuous interaction between demand, allocation, and persistence.
Applications generate demand through persistent volume claims. Kubernetes allocates storage by binding claims to volumes. Storage systems maintain persistence independently of application lifecycle.
This three-part interaction ensures that data remains available, consistent, and flexible across dynamic environments.
Even as applications scale, fail, or evolve, storage remains a stable foundation supporting the entire system.
Conclusion
Persistent storage in Kubernetes represents one of the most important building blocks for running modern applications at scale. While Kubernetes is often introduced through its ability to manage containers and automate deployments, its real strength becomes more visible when stateful workloads and data persistence are taken into account. Without a structured approach to storage, the flexibility of ephemeral containers would quickly become a limitation rather than an advantage.
At the core of this storage model is the separation between compute and data. Pods, which run application workloads, are intentionally designed to be temporary. They can be created, destroyed, and replaced at any time as part of Kubernetes’ normal operation. This design enables high availability, scaling, and self-healing behavior, but it also means that any data stored inside a pod cannot be relied upon to persist. Persistent storage solves this challenge by moving data outside the lifecycle of individual pods and into a stable, independent layer.
Persistent volumes provide the actual storage resources, while persistent volume claims act as the bridge between applications and those resources. This separation introduces a powerful abstraction. Applications no longer need to know where their data is physically stored or how the storage infrastructure is configured. Instead, they simply request what they need through a claim, and Kubernetes handles the process of finding or provisioning suitable storage.
This model brings consistency and predictability to environments that are otherwise highly dynamic. Storage can be allocated, reused, and managed independently of application lifecycles. At the same time, applications remain portable because they rely on standardized requests rather than fixed infrastructure dependencies. This balance between abstraction and control is what allows Kubernetes to function effectively in large-scale, distributed systems.
Another important outcome of this architecture is resilience. Since persistent volumes exist independently of pods, data remains intact even when workloads fail or are rescheduled. When a pod is recreated, it can reattach to the same persistent volume claim and continue operating with the same underlying data. This ability to recover state seamlessly is essential for applications that require reliability, such as databases, content management systems, and data processing pipelines.
The introduction of storage classes and dynamic provisioning further enhances this system by reducing manual intervention. Instead of pre-creating storage resources, Kubernetes can generate them on demand based on application requirements. This ensures that storage allocation is both efficient and scalable, adapting automatically to changing workloads. It also simplifies infrastructure management by shifting complexity away from administrators and into declarative configuration.
However, this flexibility also introduces responsibility. While Kubernetes manages storage lifecycle and attachment, it does not control how data is used or protected within the application itself. Developers must ensure that their applications handle concurrency, consistency, and data integrity correctly. Similarly, backup strategies and long-term data protection must be designed at the system level rather than relying solely on Kubernetes mechanisms.
Security and isolation are also critical considerations. Persistent volume claims help ensure that storage is allocated to specific workloads, preventing unintended access between applications. In multi-tenant environments, this separation becomes especially important for maintaining data integrity and protecting sensitive information.
Ultimately, Kubernetes persistent storage is not just a technical feature but a foundational design pattern that enables cloud-native architecture. It allows applications to remain stateless while still supporting complex stateful requirements. It enables infrastructure to scale independently of application logic. And it provides a stable data layer in environments that are constantly changing.
By decoupling storage from compute and introducing a structured system for managing data access, Kubernetes creates a model where applications can be both flexible and reliable at the same time. This combination is what makes it possible to run modern distributed systems that are resilient, scalable, and adaptable to evolving demands.